Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyna-AIL : Adversarial Imitation Learning by Planning
Paper and Code
Mar 08, 2019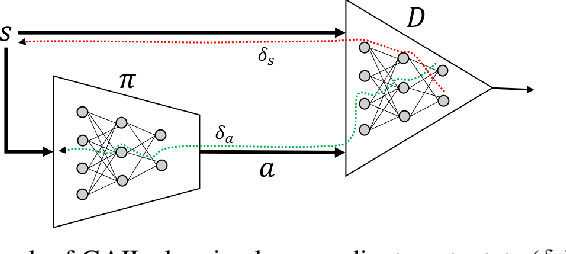
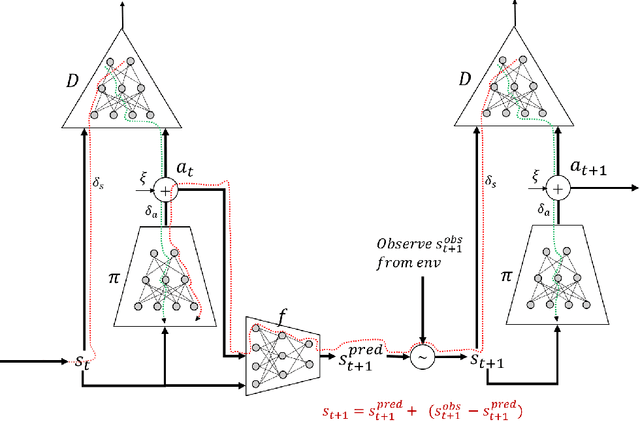
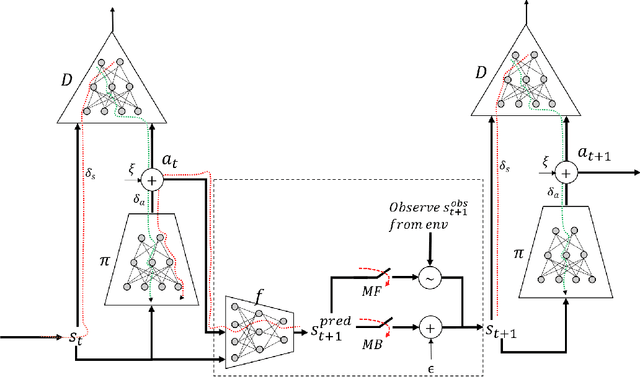
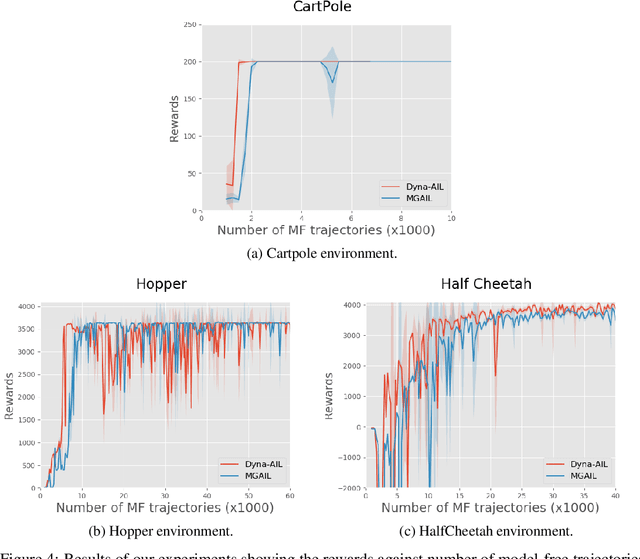
Adversarial methods for imitation learning have been shown to perform well on various control tasks. However, they require a large number of environment interactions for convergence. In this paper, we propose an end-to-end differentiable adversarial imitation learning algorithm in a Dyna-like framework for switching between model-based planning and model-free learning from expert data. Our results on both discrete and continuous environments show that our approach of using model-based planning along with model-free learning converges to an optimal policy with fewer number of environment interactions in comparison to the state-of-the-art learning methods.
* 8 pages, 6 figures, pre-print
View paper on