 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained-Context Conditional Diffusion Models for Imitation Learning
Nov 02, 2023Offline Imitation Learning (IL) is a powerful paradigm to learn visuomotor skills, especially for high-precision manipulation tasks. However, IL methods are prone to spurious correlation - expressive models may focus on distractors that are irrelevant to action prediction - and are thus fragile in real-world deployment. Prior methods have addressed this challenge by exploring different model architectures and action representations. However, none were able to balance between sample efficiency, robustness against distractors, and solving high-precision manipulation tasks with complex action space. To this end, we present $\textbf{C}$onstrained-$\textbf{C}$ontext $\textbf{C}$onditional $\textbf{D}$iffusion $\textbf{M}$odel (C3DM), a diffusion model policy for solving 6-DoF robotic manipulation tasks with high precision and ability to ignore distractions. A key component of C3DM is a fixation step that helps the action denoiser to focus on task-relevant regions around the predicted action while ignoring distractors in the context. We empirically show that C3DM is able to consistently achieve high success rate on a wide array of tasks, ranging from table top manipulation to industrial kitting, that require varying levels of precision and robustness to distractors. For details, please visit this https://sites.google.com/view/c3dm-imitation-learning
Generalizable Pose Estimation Using Implicit Scene Representations
May 26, 2023



6-DoF pose estimation is an essential component of robotic manipulation pipelines. However, it usually suffers from a lack of generalization to new instances and object types. Most widely used methods learn to infer the object pose in a discriminative setup where the model filters useful information to infer the exact pose of the object. While such methods offer accurate poses, the model does not store enough information to generalize to new objects. In this work, we address the generalization capability of pose estimation using models that contain enough information about the object to render it in different poses. We follow the line of work that inverts neural renderers to infer the pose. We propose i-$\sigma$SRN to maximize the information flowing from the input pose to the rendered scene and invert them to infer the pose given an input image. Specifically, we extend Scene Representation Networks (SRNs) by incorporating a separate network for density estimation and introduce a new way of obtaining a weighted scene representation. We investigate several ways of initial pose estimates and losses for the neural renderer. Our final evaluation shows a significant improvement in inference performance and speed compared to existing approaches.
On CAD Informed Adaptive Robotic Assembly
Aug 02, 2022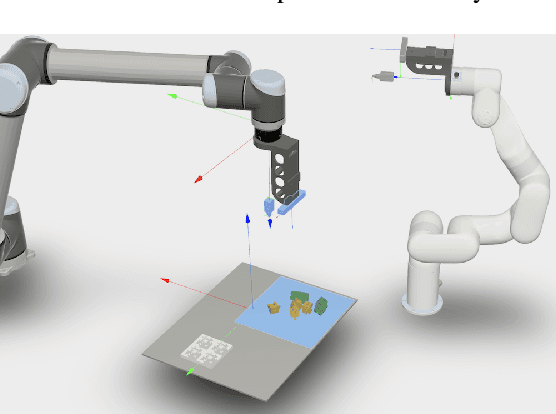


We introduce a robotic assembly system that streamlines the design-to-make workflow for going from a CAD model of a product assembly to a fully programmed and adaptive assembly process. Our system captures (in the CAD tool) the intent of the assembly process for a specific robotic workcell and generates a recipe of task-level instructions. By integrating visual sensing with deep-learned perception models, the robots infer the necessary actions to assemble the design from the generated recipe. The perception models are trained directly from simulation, allowing the system to identify various parts based on CAD information. We demonstrate the system with a workcell of two robots to assemble interlocking 3D part designs. We first build and tune the assembly process in simulation, verifying the generated recipe. Finally, the real robotic workcell assembles the design using the same behavior.