 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagewise Knowledge Distillation
Paper and Code
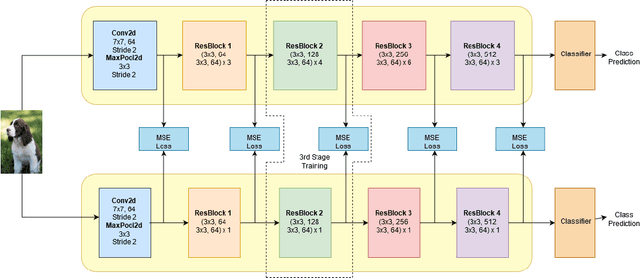
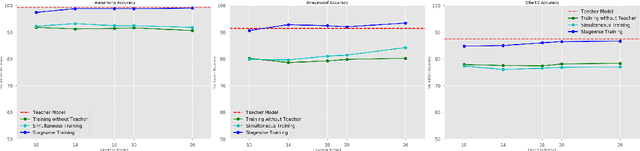
The deployment of modern Deep Learning models requires high computational power. However, many applications are targeted for embedded devices like smartphones and wearables which lack such computational abilities. This necessitates compact networks that reduce computations while preserving the performance. Knowledge Distillation is one of the methods used to achieve this. Traditional Knowledge Distillation methods transfer knowledge from teacher to student in a single stage. We propose progressive stagewise training to improve the transfer of knowledge. We also show that this method works even with a fraction of the data used for training the teacher model, without compromising on the metric. This method can complement other model compression methods and also can be viewed as a generalized model compression technique.