 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating away Translationese without Parallel Data
Paper and Code
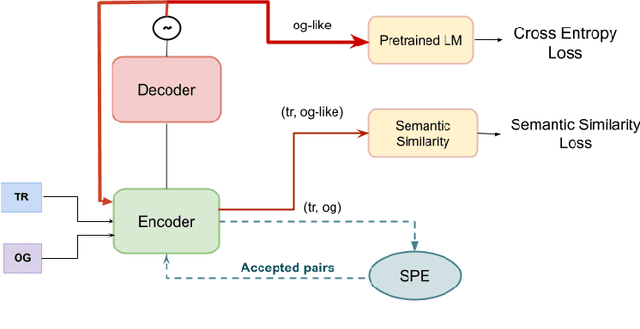

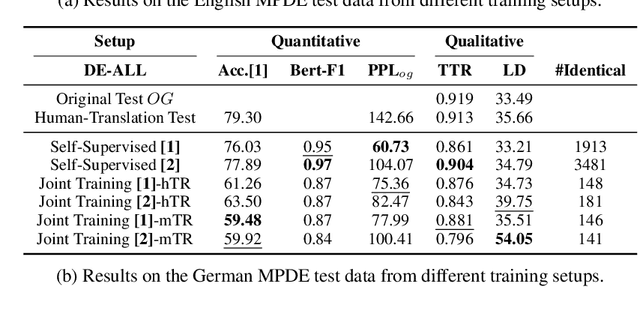

Translated texts exhibit systematic linguistic differences compared to original texts in the same language, and these differences are referred to as translationese. Translationese has effects on various cross-lingual natural language processing tasks, potentially leading to biased results. In this paper, we explore a novel approach to reduce translationese in translated texts: translation-based style transfer. As there are no parallel human-translated and original data in the same language, we use a self-supervised approach that can learn from comparable (rather than parallel) mono-lingual original and translated data. However, even this self-supervised approach requires some parallel data for validation. We show how we can eliminate the need for parallel validation data by combining the self-supervised loss with an unsupervised loss. This unsupervised loss leverages the original language model loss over the style-transferred output and a semantic similarity loss between the input and style-transferred output. We evaluate our approach in terms of original vs. translationese binary classification in addition to measuring content preservation and target-style fluency. The results show that our approach is able to reduce translationese classifier accuracy to a level of a random classifier after style transfer while adequately preserving the content and fluency in the target original style.