 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Flores Bloomz Wrong: Cross-Direction Contamination in Machine Translation Evaluation
Jan 28, 2026Large language models (LLMs) can be benchmark-contaminated, resulting in inflated scores that mask memorization as generalization, and in multilingual settings, this memorization can even transfer to "uncontaminated" languages. Using the FLORES-200 translation benchmark as a diagnostic, we study two 7-8B instruction-tuned multilingual LLMs: Bloomz, which was trained on FLORES, and Llama as an uncontaminated control. We confirm Bloomz's FLORES contamination and demonstrate that machine translation contamination can be cross-directional, artificially boosting performance in unseen translation directions due to target-side memorization. Further analysis shows that recall of memorized references often persists despite various source-side perturbation efforts like paraphrasing and named entity replacement. However, replacing named entities leads to a consistent decrease in BLEU, suggesting an effective probing method for memorization in contaminated models.
Translating away Translationese without Parallel Data
Oct 28, 2023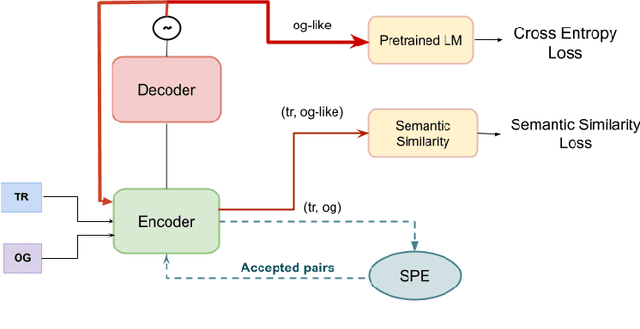

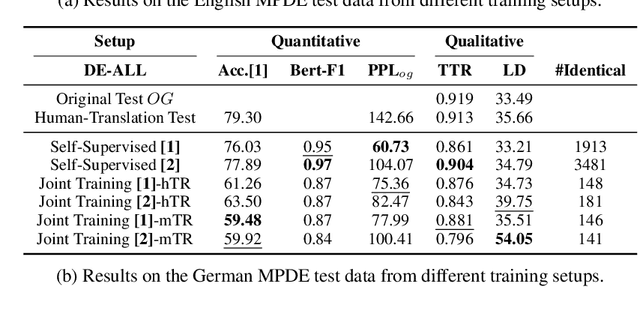

Translated texts exhibit systematic linguistic differences compared to original texts in the same language, and these differences are referred to as translationese. Translationese has effects on various cross-lingual natural language processing tasks, potentially leading to biased results. In this paper, we explore a novel approach to reduce translationese in translated texts: translation-based style transfer. As there are no parallel human-translated and original data in the same language, we use a self-supervised approach that can learn from comparable (rather than parallel) mono-lingual original and translated data. However, even this self-supervised approach requires some parallel data for validation. We show how we can eliminate the need for parallel validation data by combining the self-supervised loss with an unsupervised loss. This unsupervised loss leverages the original language model loss over the style-transferred output and a semantic similarity loss between the input and style-transferred output. We evaluate our approach in terms of original vs. translationese binary classification in addition to measuring content preservation and target-style fluency. The results show that our approach is able to reduce translationese classifier accuracy to a level of a random classifier after style transfer while adequately preserving the content and fluency in the target original style.
Towards Debiasing Translation Artifacts
May 16, 2022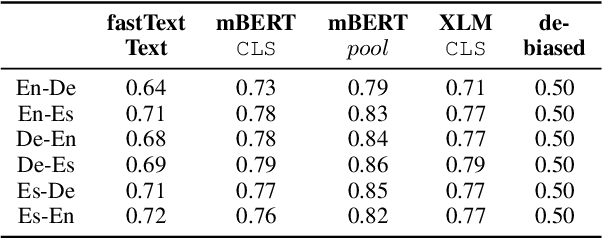
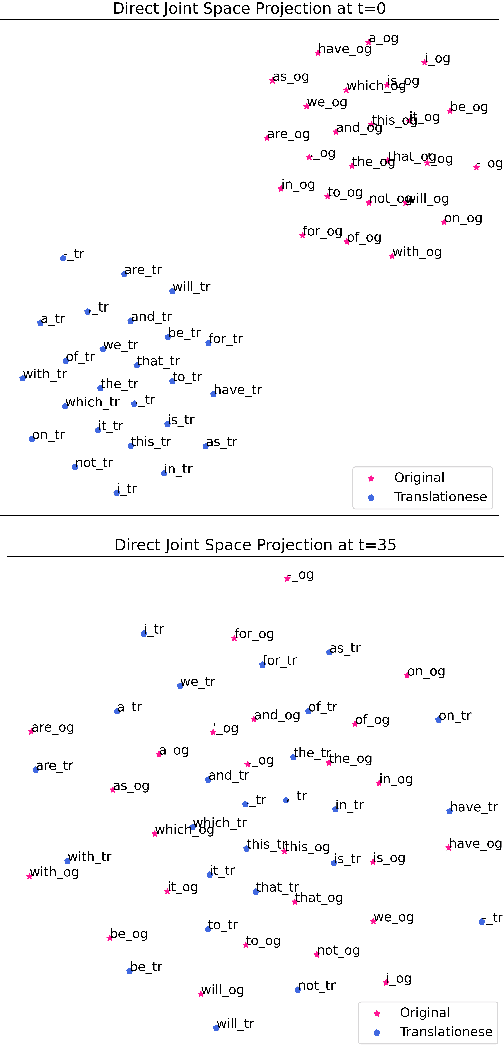
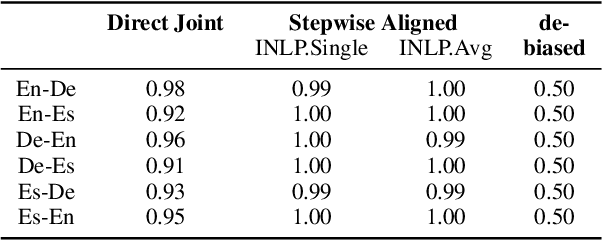
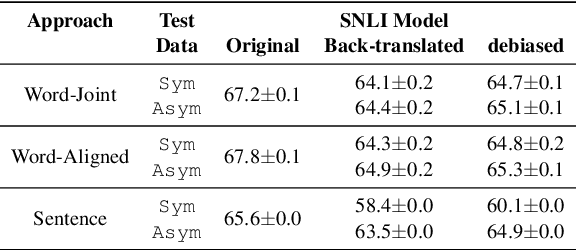
Cross-lingual natural language processing relies on translation, either by humans or machines, at different levels, from translating training data to translating test sets. However, compared to original texts in the same language, translations possess distinct qualities referred to as translationese. Previous research has shown that these translation artifacts influence the performance of a variety of cross-lingual tasks. In this work, we propose a novel approach to reducing translationese by extending an established bias-removal technique. We use the Iterative Null-space Projection (INLP) algorithm, and show by measuring classification accuracy before and after debiasing, that translationese is reduced at both sentence and word level. We evaluate the utility of debiasing translationese on a natural language inference (NLI) task, and show that by reducing this bias, NLI accuracy improves. To the best of our knowledge, this is the first study to debias translationese as represented in latent embedding space.
EdinSaar@WMT21: North-Germanic Low-Resource Multilingual NMT
Sep 29, 2021
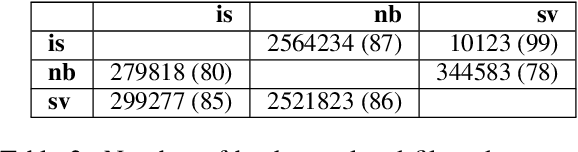
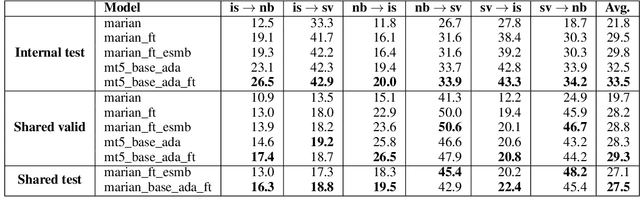
We describe the EdinSaar submission to the shared task of Multilingual Low-Resource Translation for North Germanic Languages at the Sixth Conference on Machine Translation (WMT2021). We submit multilingual translation models for translations to/from Icelandic (is), Norwegian-Bokmal (nb), and Swedish (sv). We employ various experimental approaches, including multilingual pre-training, back-translation, fine-tuning, and ensembling. In most translation directions, our models outperform other submitted systems.
Comparing Feature-Engineering and Feature-Learning Approaches for Multilingual Translationese Classification
Sep 15, 2021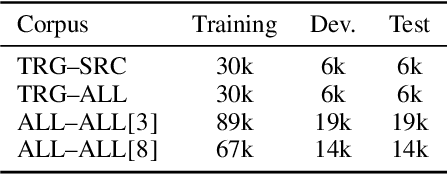
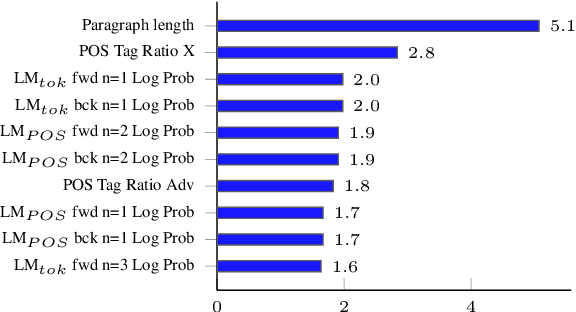
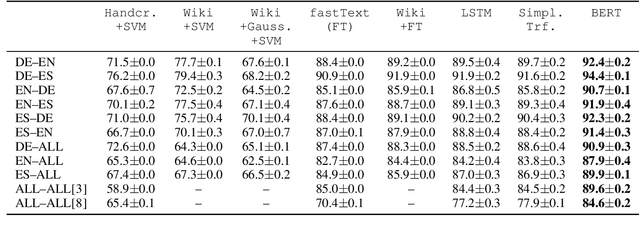
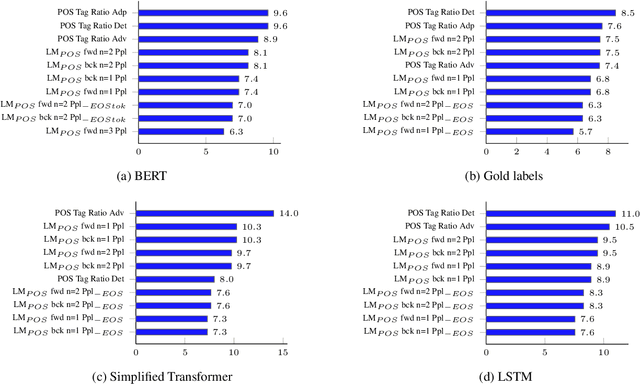
Traditional hand-crafted linguistically-informed features have often been used for distinguishing between translated and original non-translated texts. By contrast, to date, neural architectures without manual feature engineering have been less explored for this task. In this work, we (i) compare the traditional feature-engineering-based approach to the feature-learning-based one and (ii) analyse the neural architectures in order to investigate how well the hand-crafted features explain the variance in the neural models' predictions. We use pre-trained neural word embeddings, as well as several end-to-end neural architectures in both monolingual and multilingual settings and compare them to feature-engineering-based SVM classifiers. We show that (i) neural architectures outperform other approaches by more than 20 accuracy points, with the BERT-based model performing the best in both the monolingual and multilingual settings; (ii) while many individual hand-crafted translationese features correlate with neural model predictions, feature importance analysis shows that the most important features for neural and classical architectures differ; and (iii) our multilingual experiments provide empirical evidence for translationese universals across languages.
The RGNLP Machine Translation Systems for WAT 2018
Dec 03, 2018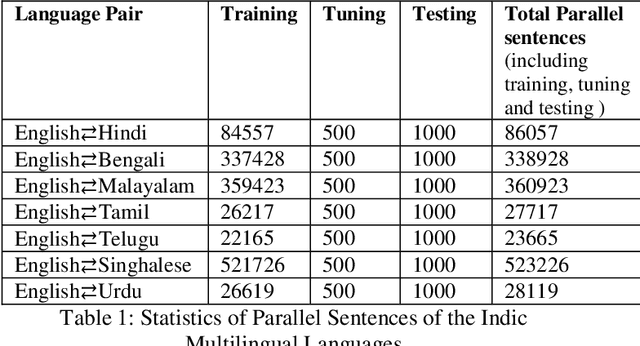
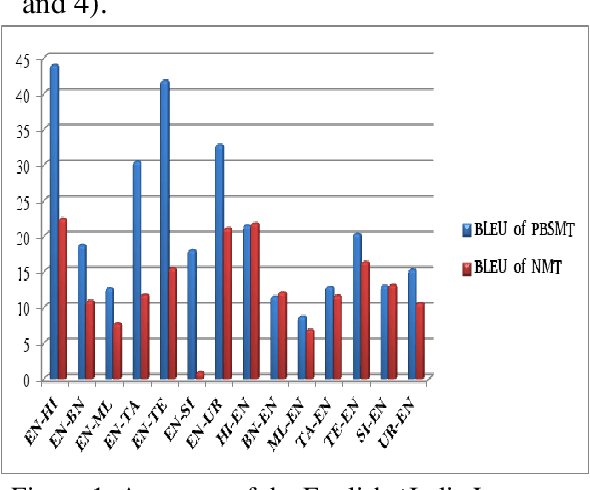
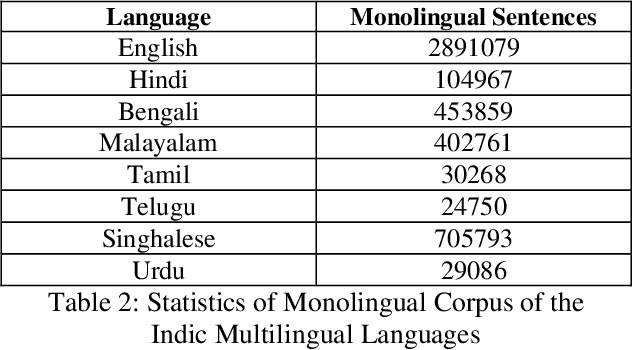
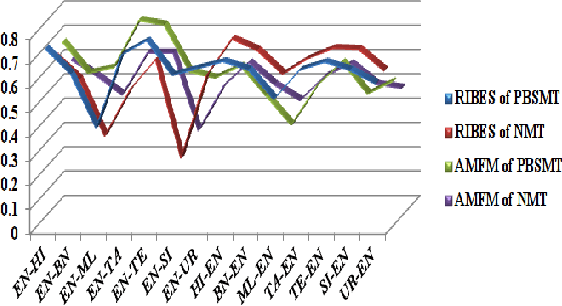
This paper presents the system description of Machine Translation (MT) system(s) for Indic Languages Multilingual Task for the 2018 edition of the WAT Shared Task. In our experiments, we (the RGNLP team) explore both statistical and neural methods across all language pairs. (We further present an extensive comparison of language-related problems for both the approaches in the context of low-resourced settings.) Our PBSMT models were highest score on all automatic evaluation metrics in the English into Telugu, Hindi, Bengali, Tamil portion of the shared task.