 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Spurious Correlation in Classification: 'Clever Hans' in Translationese
Aug 25, 2023



Recent work has shown evidence of 'Clever Hans' behavior in high-performance neural translationese classifiers, where BERT-based classifiers capitalize on spurious correlations, in particular topic information, between data and target classification labels, rather than genuine translationese signals. Translationese signals are subtle (especially for professional translation) and compete with many other signals in the data such as genre, style, author, and, in particular, topic. This raises the general question of how much of the performance of a classifier is really due to spurious correlations in the data versus the signals actually targeted for by the classifier, especially for subtle target signals and in challenging (low resource) data settings. We focus on topic-based spurious correlation and approach the question from two directions: (i) where we have no knowledge about spurious topic information and its distribution in the data, (ii) where we have some indication about the nature of spurious topic correlations. For (i) we develop a measure from first principles capturing alignment of unsupervised topics with target classification labels as an indication of spurious topic information in the data. We show that our measure is the same as purity in clustering and propose a 'topic floor' (as in a 'noise floor') for classification. For (ii) we investigate masking of known spurious topic carriers in classification. Both (i) and (ii) contribute to quantifying and (ii) to mitigating spurious correlations.
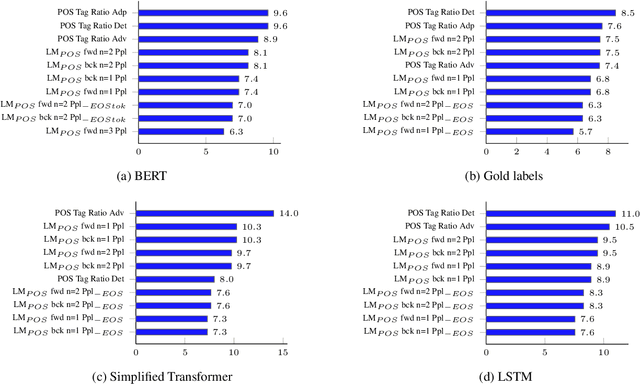
Explaining Translationese: why are Neural Classifiers Better and what do they Learn?
Oct 24, 2022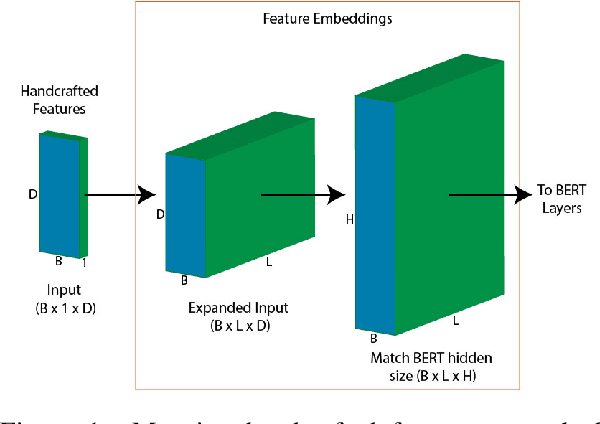


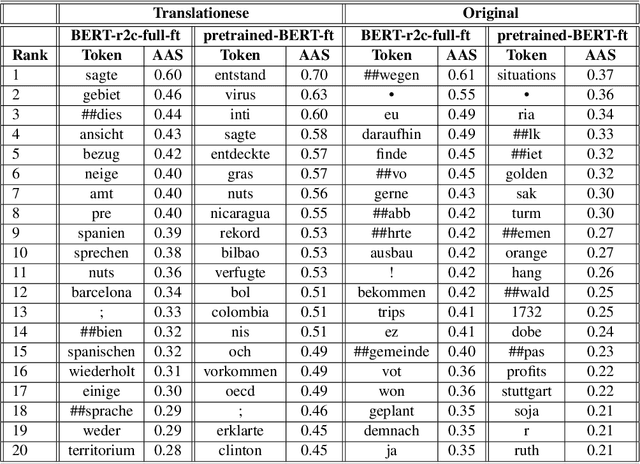
Recent work has shown that neural feature- and representation-learning, e.g. BERT, achieves superior performance over traditional manual feature engineering based approaches, with e.g. SVMs, in translationese classification tasks. Previous research did not show $(i)$ whether the difference is because of the features, the classifiers or both, and $(ii)$ what the neural classifiers actually learn. To address $(i)$, we carefully design experiments that swap features between BERT- and SVM-based classifiers. We show that an SVM fed with BERT representations performs at the level of the best BERT classifiers, while BERT learning and using handcrafted features performs at the level of an SVM using handcrafted features. This shows that the performance differences are due to the features. To address $(ii)$ we use integrated gradients and find that $(a)$ there is indication that information captured by hand-crafted features is only a subset of what BERT learns, and $(b)$ part of BERT's top performance results are due to BERT learning topic differences and spurious correlations with translationese.
Comparing Feature-Engineering and Feature-Learning Approaches for Multilingual Translationese Classification
Sep 15, 2021
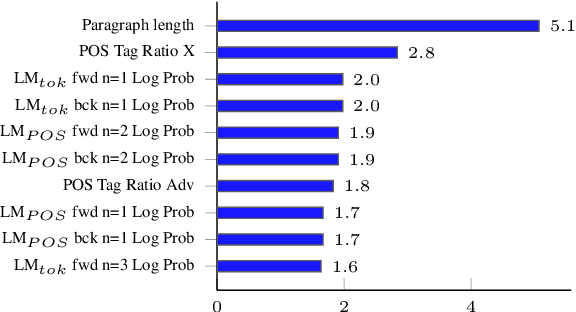
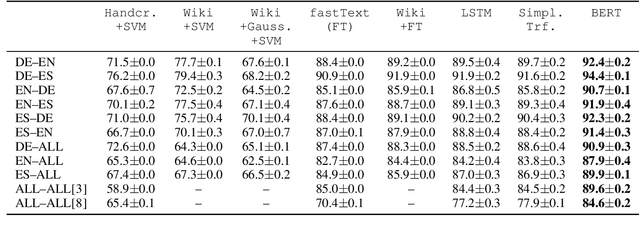
Traditional hand-crafted linguistically-informed features have often been used for distinguishing between translated and original non-translated texts. By contrast, to date, neural architectures without manual feature engineering have been less explored for this task. In this work, we (i) compare the traditional feature-engineering-based approach to the feature-learning-based one and (ii) analyse the neural architectures in order to investigate how well the hand-crafted features explain the variance in the neural models' predictions. We use pre-trained neural word embeddings, as well as several end-to-end neural architectures in both monolingual and multilingual settings and compare them to feature-engineering-based SVM classifiers. We show that (i) neural architectures outperform other approaches by more than 20 accuracy points, with the BERT-based model performing the best in both the monolingual and multilingual settings; (ii) while many individual hand-crafted translationese features correlate with neural model predictions, feature importance analysis shows that the most important features for neural and classical architectures differ; and (iii) our multilingual experiments provide empirical evidence for translationese universals across languages.
Leveraging Neural Machine Translation for Word Alignment
Mar 31, 2021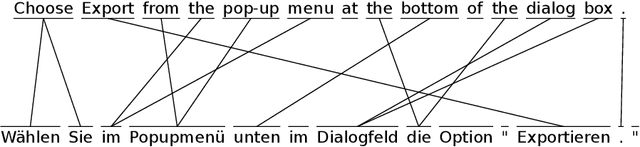

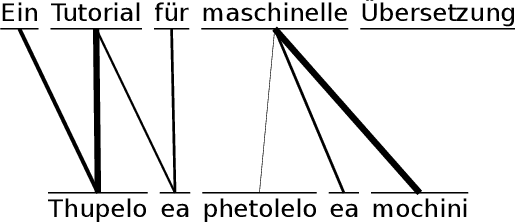
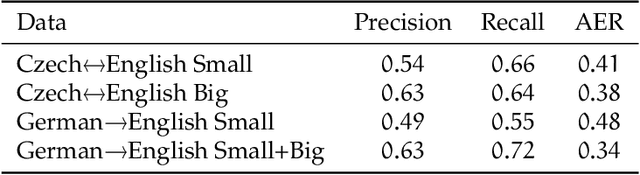
The most common tools for word-alignment rely on a large amount of parallel sentences, which are then usually processed according to one of the IBM model algorithms. The training data is, however, the same as for machine translation (MT) systems, especially for neural MT (NMT), which itself is able to produce word-alignments using the trained attention heads. This is convenient because word-alignment is theoretically a viable byproduct of any attention-based NMT, which is also able to provide decoder scores for a translated sentence pair. We summarize different approaches on how word-alignment can be extracted from alignment scores and then explore ways in which scores can be extracted from NMT, focusing on inferring the word-alignment scores based on output sentence and token probabilities. We compare this to the extraction of alignment scores from attention. We conclude with aggregating all of the sources of alignment scores into a simple feed-forward network which achieves the best results when combined alignment extractors are used.