 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-AID: Identifying Actionable Information from Disaster-related Tweets
Paper and Code
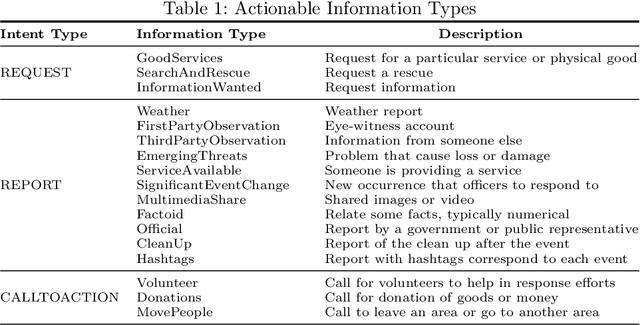
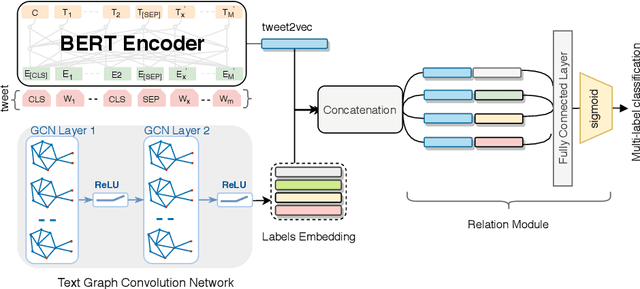
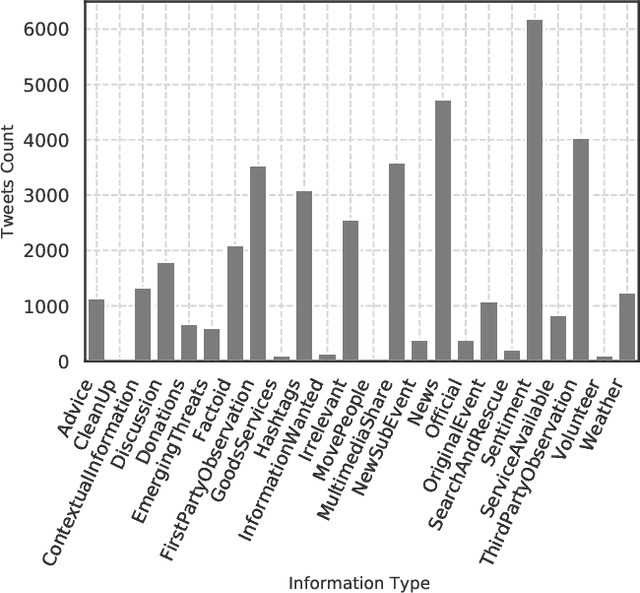
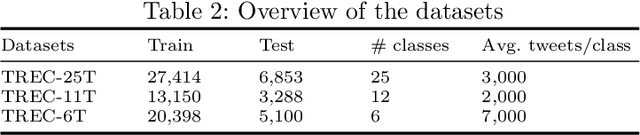
Social media data plays a significant role in modern disaster management by providing valuable data about affected people, donations, help requests, and advice. Recent studies highlight the need to filter information on social media into fine-grained content categories. However, identifying useful information from massive amounts of social media posts during a crisis is a challenging task. Automatically categorizing the information (e.g., reports on affected individuals, donations, and volunteers) contained in these posts is vital for their efficient handling and consumption by the communities affected and organizations concerned. In this paper, we propose a system, dubbed I-AID, to automatically filter tweets with critical or actionable information from the enormous volume of social media data. Our system combines state-of-the-art approaches to process and represents textual data in order to capture its underlying semantics. In particular, we use 1) Bidirectional Encoder Representations from Transformers (commonly known as, BERT) to learn a contextualized vector representation of a tweet, and 2) a graph-based architecture to compute semantic correlations between the entities and hashtags in tweets and their corresponding labels. We conducted our experiments on a real-world dataset of disaster-related tweets. Our experimental results indicate that our model outperforms state-of-the-art approaches baselines in terms of F1-score by +11%.