 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Knowledge Editing using Logical Rules
Jun 09, 2026Large Language Models (LLMs) are increasingly deployed in real-world applications that require access to up-to-date knowledge. However, retraining LLMs is computationally expensive. Therefore, knowledge editing techniques are crucial for maintaining current information and correcting erroneous assertions within pre-trained models. Current benchmarks for knowledge editing primarily focus on recalling edited facts, often neglecting their logical consequences. To address this limitation, we introduce a new benchmark designed to evaluate how knowledge editing methods handle the logical consequences of a single fact edit. Our benchmark extracts relevant logical rules from a knowledge graph for a given edit. Then, it generates multi-hop questions based on these rules to assess the impact on logical consequences. Our findings indicate that while existing knowledge editing approaches can accurately insert direct assertions into LLMs, they frequently fail to inject entailed knowledge. Specifically, experiments with popular methods like ROME and FT reveal a substantial performance gap, up to 24%, between evaluations on directly edited knowledge and on entailed knowledge. This highlights the critical need for semantics-aware evaluation frameworks in knowledge editing.
* Accepted at the 24th International Semantic Web Conference 2025
Universal Knowledge Graph Embeddings
Oct 23, 2023A variety of knowledge graph embedding approaches have been developed. Most of them obtain embeddings by learning the structure of the knowledge graph within a link prediction setting. As a result, the embeddings reflect only the semantics of a single knowledge graph, and embeddings for different knowledge graphs are not aligned, e.g., they cannot be used to find similar entities across knowledge graphs via nearest neighbor search. However, knowledge graph embedding applications such as entity disambiguation require a more global representation, i.e., a representation that is valid across multiple sources. We propose to learn universal knowledge graph embeddings from large-scale interlinked knowledge sources. To this end, we fuse large knowledge graphs based on the owl:sameAs relation such that every entity is represented by a unique identity. We instantiate our idea by computing universal embeddings based on DBpedia and Wikidata yielding embeddings for about 180 million entities, 15 thousand relations, and 1.2 billion triples. Moreover, we develop a convenient API to provide embeddings as a service. Experiments on link prediction show that universal knowledge graph embeddings encode better semantics compared to embeddings computed on a single knowledge graph. For reproducibility purposes, we provide our source code and datasets open access at https://github.com/dice-group/Universal_Embeddings
I-AID: Identifying Actionable Information from Disaster-related Tweets
Aug 04, 2020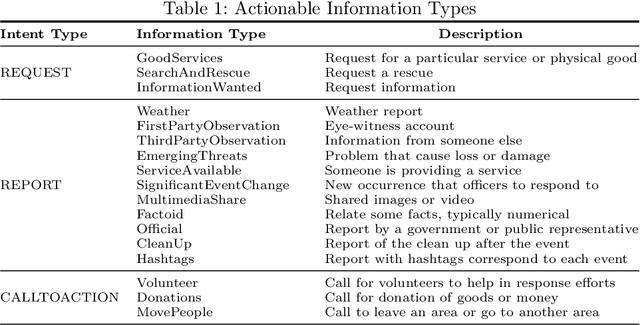
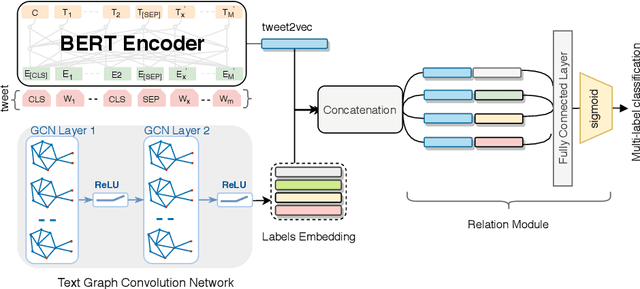
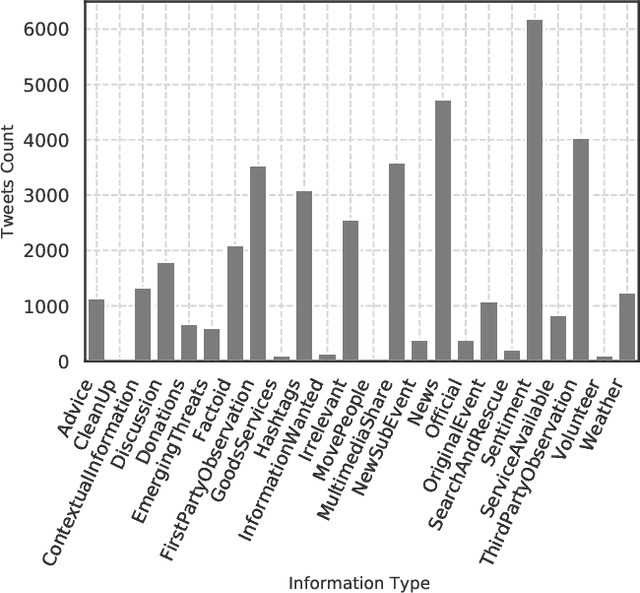
Social media data plays a significant role in modern disaster management by providing valuable data about affected people, donations, help requests, and advice. Recent studies highlight the need to filter information on social media into fine-grained content categories. However, identifying useful information from massive amounts of social media posts during a crisis is a challenging task. Automatically categorizing the information (e.g., reports on affected individuals, donations, and volunteers) contained in these posts is vital for their efficient handling and consumption by the communities affected and organizations concerned. In this paper, we propose a system, dubbed I-AID, to automatically filter tweets with critical or actionable information from the enormous volume of social media data. Our system combines state-of-the-art approaches to process and represents textual data in order to capture its underlying semantics. In particular, we use 1) Bidirectional Encoder Representations from Transformers (commonly known as, BERT) to learn a contextualized vector representation of a tweet, and 2) a graph-based architecture to compute semantic correlations between the entities and hashtags in tweets and their corresponding labels. We conducted our experiments on a real-world dataset of disaster-related tweets. Our experimental results indicate that our model outperforms state-of-the-art approaches baselines in terms of F1-score by +11%.
Semantic-based End-to-End Learning for Typhoon Intensity Prediction
Mar 22, 2020
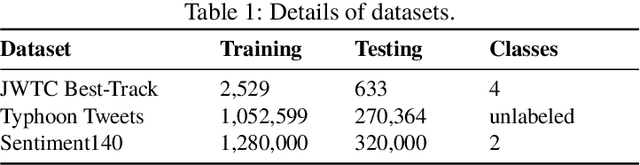
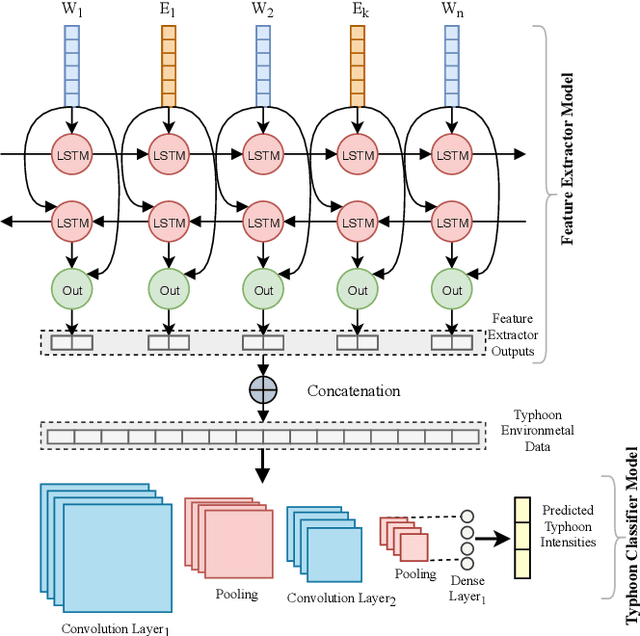
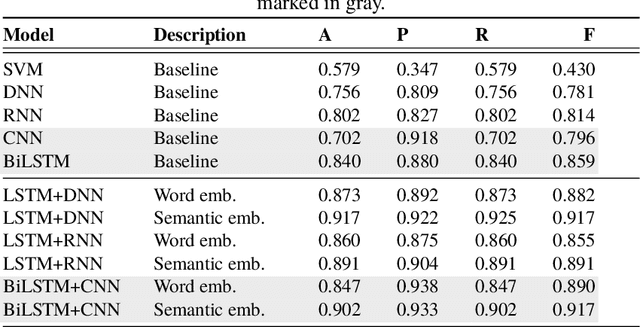
Disaster prediction is one of the most critical tasks towards disaster surveillance and preparedness. Existing technologies employ different machine learning approaches to predict incoming disasters from historical environmental data. However, for short-term disasters (e.g., earthquakes), historical data alone has a limited prediction capability. Therefore, additional sources of warnings are required for accurate prediction. We consider social media as a supplementary source of knowledge in addition to historical environmental data. However, social media posts (e.g., tweets) is very informal and contains only limited content. To alleviate these limitations, we propose the combination of semantically-enriched word embedding models to represent entities in tweets with their semantic representations computed with the traditionalword2vec. Moreover, we study how the correlation between social media posts and typhoons magnitudes (also called intensities)-in terms of volume and sentiments of tweets-. Based on these insights, we propose an end-to-end based framework that learns from disaster-related tweets and environmental data to improve typhoon intensity prediction. This paper is an extension of our work originally published in K-CAP 2019 [32]. We extended this paper by building our framework with state-of-the-art deep neural models, up-dated our dataset with new typhoons and their tweets to-date and benchmark our approach against recent baselines in disaster prediction. Our experimental results show that our approach outperforms the accuracy of the state-of-the-art baselines in terms of F1-score with (CNN by12.1%and BiLSTM by3.1%) improvement compared with last experiments