 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Reasoning for Robust Instance Retrieval in $\mathcal{SHOIQ}$
Oct 23, 2025Concept learning exploits background knowledge in the form of description logic axioms to learn explainable classification models from knowledge bases. Despite recent breakthroughs in neuro-symbolic concept learning, most approaches still cannot be deployed on real-world knowledge bases. This is due to their use of description logic reasoners, which are not robust against inconsistencies nor erroneous data. We address this challenge by presenting a novel neural reasoner dubbed EBR. Our reasoner relies on embeddings to approximate the results of a symbolic reasoner. We show that EBR solely requires retrieving instances for atomic concepts and existential restrictions to retrieve or approximate the set of instances of any concept in the description logic $\mathcal{SHOIQ}$. In our experiments, we compare EBR with state-of-the-art reasoners. Our results suggest that EBR is robust against missing and erroneous data in contrast to existing reasoners.
Discrete Diffusion-Based Model-Level Explanation of Heterogeneous GNNs with Node Features
Aug 11, 2025Many real-world datasets, such as citation networks, social networks, and molecular structures, are naturally represented as heterogeneous graphs, where nodes belong to different types and have additional features. For example, in a citation network, nodes representing "Paper" or "Author" may include attributes like keywords or affiliations. A critical machine learning task on these graphs is node classification, which is useful for applications such as fake news detection, corporate risk assessment, and molecular property prediction. Although Heterogeneous Graph Neural Networks (HGNNs) perform well in these contexts, their predictions remain opaque. Existing post-hoc explanation methods lack support for actual node features beyond one-hot encoding of node type and often fail to generate realistic, faithful explanations. To address these gaps, we propose DiGNNExplainer, a model-level explanation approach that synthesizes heterogeneous graphs with realistic node features via discrete denoising diffusion. In particular, we generate realistic discrete features (e.g., bag-of-words features) using diffusion models within a discrete space, whereas previous approaches are limited to continuous spaces. We evaluate our approach on multiple datasets and show that DiGNNExplainer produces explanations that are realistic and faithful to the model's decision-making, outperforming state-of-the-art methods.
A Responsible Face Recognition Approach for Small and Mid-Scale Systems Through Personalized Neural Networks
May 26, 2025Traditional face recognition systems rely on extracting fixed face representations, known as templates, to store and verify identities. These representations are typically generated by neural networks that often lack explainability and raise concerns regarding fairness and privacy. In this work, we propose a novel model-template (MOTE) approach that replaces vector-based face templates with small personalized neural networks. This design enables more responsible face recognition for small and medium-scale systems. During enrollment, MOTE creates a dedicated binary classifier for each identity, trained to determine whether an input face matches the enrolled identity. Each classifier is trained using only a single reference sample, along with synthetically balanced samples to allow adjusting fairness at the level of a single individual during enrollment. Extensive experiments across multiple datasets and recognition systems demonstrate substantial improvements in fairness and particularly in privacy. Although the method increases inference time and storage requirements, it presents a strong solution for small- and mid-scale applications where fairness and privacy are critical.
Utilizing Description Logics for Global Explanations of Heterogeneous Graph Neural Networks
May 21, 2024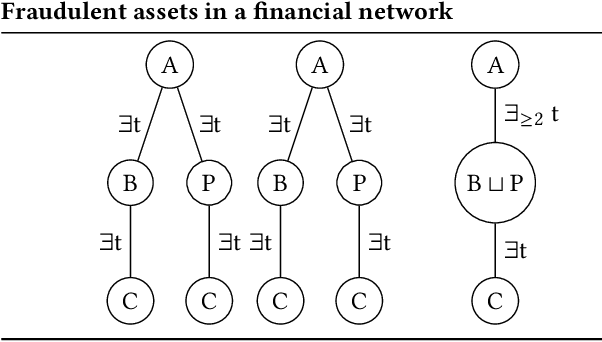

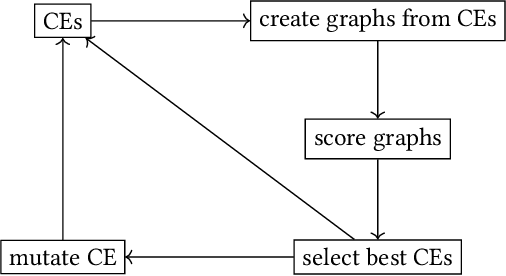
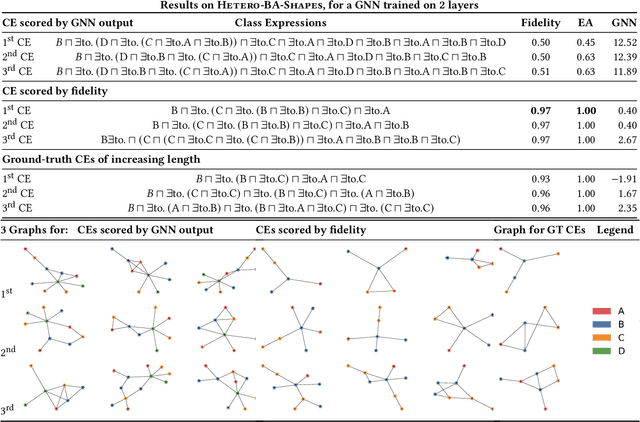
Graph Neural Networks (GNNs) are effective for node classification in graph-structured data, but they lack explainability, especially at the global level. Current research mainly utilizes subgraphs of the input as local explanations or generates new graphs as global explanations. However, these graph-based methods are limited in their ability to explain classes with multiple sufficient explanations. To provide more expressive explanations, we propose utilizing class expressions (CEs) from the field of description logic (DL). Our approach explains heterogeneous graphs with different types of nodes using CEs in the EL description logic. To identify the best explanation among multiple candidate explanations, we employ and compare two different scoring functions: (1) For a given CE, we construct multiple graphs, have the GNN make a prediction for each graph, and aggregate the predicted scores. (2) We score the CE in terms of fidelity, i.e., we compare the predictions of the GNN to the predictions by the CE on a separate validation set. Instead of subgraph-based explanations, we offer CE-based explanations.
Causal Question Answering with Reinforcement Learning
Nov 05, 2023Causal questions inquire about causal relationships between different events or phenomena. Specifically, they often aim to determine whether there is a relationship between two phenomena, or to identify all causes/effects of a phenomenon. Causal questions are important for a variety of use cases, including virtual assistants and search engines. However, many current approaches to causal question answering cannot provide explanations or evidence for their answers. Hence, in this paper, we aim to answer causal questions with CauseNet, a large-scale dataset of causal relations and their provenance data. Inspired by recent, successful applications of reinforcement learning to knowledge graph tasks, such as link prediction and fact-checking, we explore the application of reinforcement learning on CauseNet for causal question answering. We introduce an Actor-Critic based agent which learns to search through the graph to answer causal questions. We bootstrap the agent with a supervised learning procedure to deal with large action spaces and sparse rewards. Our evaluation shows that the agent successfully prunes the search space to answer binary causal questions by visiting less than 30 nodes per question compared to over 3,000 nodes by a naive breadth-first search. Our ablation study indicates that our supervised learning strategy provides a strong foundation upon which our reinforcement learning agent improves. The paths returned by our agent explain the mechanisms by which a cause produces an effect. Moreover, for each edge on a path, CauseNet stores its original source on the web allowing for easy verification of paths.
Universal Knowledge Graph Embeddings
Oct 23, 2023A variety of knowledge graph embedding approaches have been developed. Most of them obtain embeddings by learning the structure of the knowledge graph within a link prediction setting. As a result, the embeddings reflect only the semantics of a single knowledge graph, and embeddings for different knowledge graphs are not aligned, e.g., they cannot be used to find similar entities across knowledge graphs via nearest neighbor search. However, knowledge graph embedding applications such as entity disambiguation require a more global representation, i.e., a representation that is valid across multiple sources. We propose to learn universal knowledge graph embeddings from large-scale interlinked knowledge sources. To this end, we fuse large knowledge graphs based on the owl:sameAs relation such that every entity is represented by a unique identity. We instantiate our idea by computing universal embeddings based on DBpedia and Wikidata yielding embeddings for about 180 million entities, 15 thousand relations, and 1.2 billion triples. Moreover, we develop a convenient API to provide embeddings as a service. Experiments on link prediction show that universal knowledge graph embeddings encode better semantics compared to embeddings computed on a single knowledge graph. For reproducibility purposes, we provide our source code and datasets open access at https://github.com/dice-group/Universal_Embeddings
LitCQD: Multi-Hop Reasoning in Incomplete Knowledge Graphs with Numeric Literals
Apr 28, 2023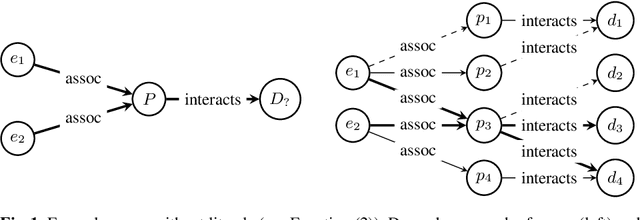
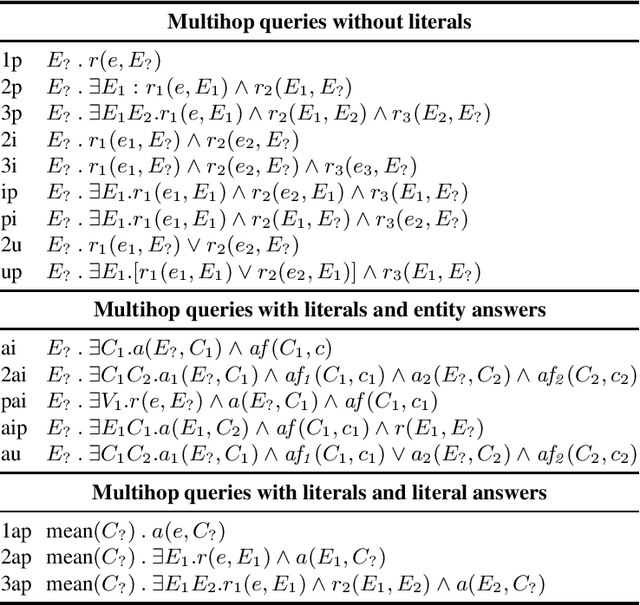
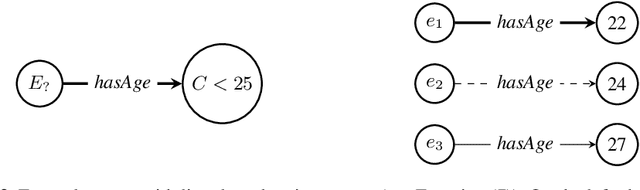
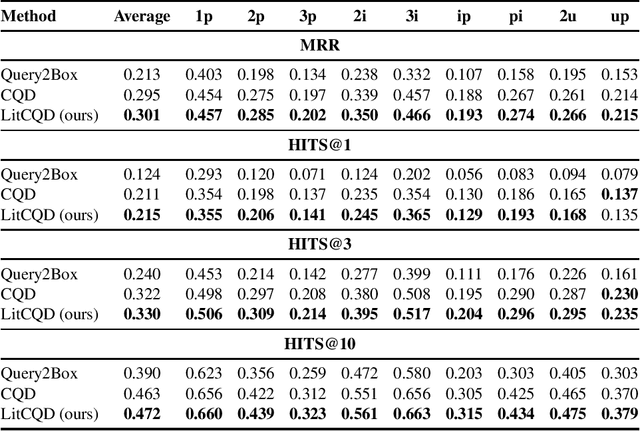
Most real-world knowledge graphs, including Wikidata, DBpedia, and Yago are incomplete. Answering queries on such incomplete graphs is an important, but challenging problem. Recently, a number of approaches, including complex query decomposition (CQD), have been proposed to answer complex, multi-hop queries with conjunctions and disjunctions on such graphs. However, all state-of-the-art approaches only consider graphs consisting of entities and relations, neglecting literal values. In this paper, we propose LitCQD -- an approach to answer complex, multi-hop queries where both the query and the knowledge graph can contain numeric literal values: LitCQD can answer queries having numerical answers or having entity answers satisfying numerical constraints. For example, it allows to query (1)~persons living in New York having a certain age, and (2)~the average age of persons living in New York. We evaluate LitCQD on query types with and without literal values. To evaluate LitCQD, we generate complex, multi-hop queries and their expected answers on a version of the FB15k-237 dataset that was extended by literal values.
Counterfactual Explanations for Concepts in $\mathcal{ELH}$
Jan 12, 2023Knowledge bases are widely used for information management on the web, enabling high-impact applications such as web search, question answering, and natural language processing. They also serve as the backbone for automatic decision systems, e.g. for medical diagnostics and credit scoring. As stakeholders affected by these decisions would like to understand their situation and verify fair decisions, a number of explanation approaches have been proposed using concepts in description logics. However, the learned concepts can become long and difficult to fathom for non-experts, even when verbalized. Moreover, long concepts do not immediately provide a clear path of action to change one's situation. Counterfactuals answering the question "How must feature values be changed to obtain a different classification?" have been proposed as short, human-friendly explanations for tabular data. In this paper, we transfer the notion of counterfactuals to description logics and propose the first algorithm for generating counterfactual explanations in the description logic $\mathcal{ELH}$. Counterfactual candidates are generated from concepts and the candidates with fewest feature changes are selected as counterfactuals. In case of multiple counterfactuals, we rank them according to the likeliness of their feature combinations. For evaluation, we conduct a user survey to investigate which of the generated counterfactual candidates are preferred for explanation by participants. In a second study, we explore possible use cases for counterfactual explanations.
Neural Class Expression Synthesis
Nov 18, 2021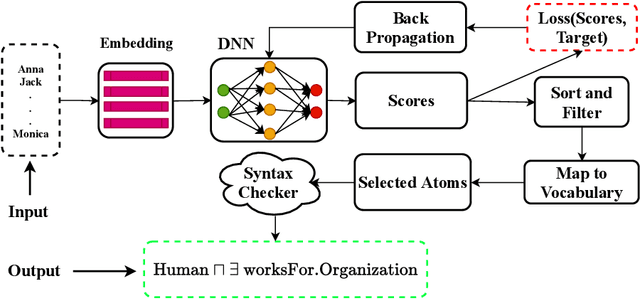

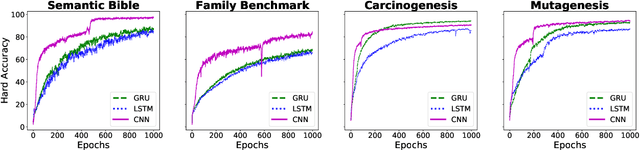
Class expression learning is a branch of explainable supervised machine learning of increasing importance. Most existing approaches for class expression learning in description logics are search algorithms or hard-rule-based. In particular, approaches based on refinement operators suffer from scalability issues as they rely on heuristic functions to explore a large search space for each learning problem. We propose a new family of approaches, which we dub synthesis approaches. Instances of this family compute class expressions directly from the examples provided. Consequently, they are not subject to the runtime limitations of search-based approaches nor the lack of flexibility of hard-rule-based approaches. We study three instances of this novel family of approaches that use lightweight neural network architectures to synthesize class expressions from sets of positive examples. The results of their evaluation on four benchmark datasets suggest that they can effectively synthesize high-quality class expressions with respect to the input examples in under a second on average. Moreover, a comparison with the state-of-the-art approaches CELOE and ELTL suggests that we achieve significantly better F-measures on large ontologies. For reproducibility purposes, we provide our implementation as well as pre-trained models in the public GitHub repository at https://github.com/ConceptLengthLearner/NCES
EvoLearner: Learning Description Logics with Evolutionary Algorithms
Nov 08, 2021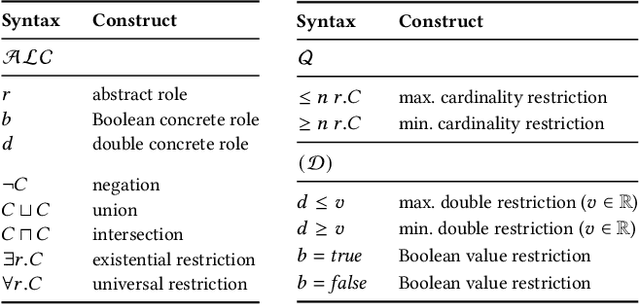
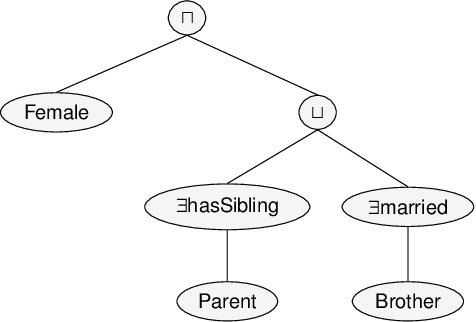
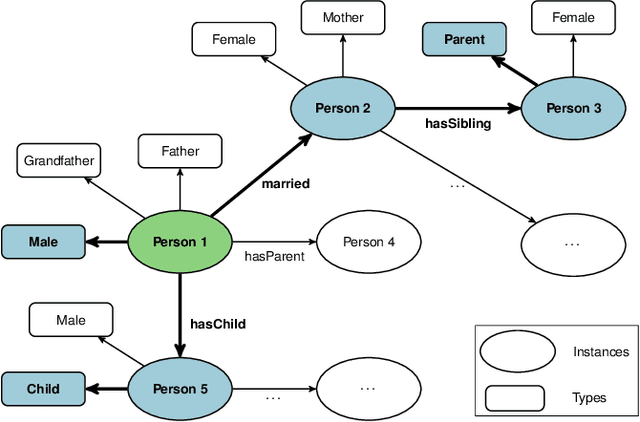
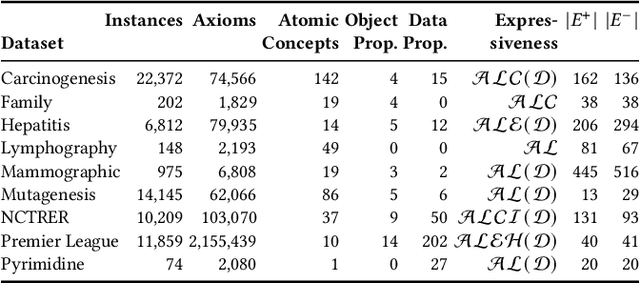
Classifying nodes in knowledge graphs is an important task, e.g., predicting missing types of entities, predicting which molecules cause cancer, or predicting which drugs are promising treatment candidates. While black-box models often achieve high predictive performance, they are only post-hoc and locally explainable and do not allow the learned model to be easily enriched with domain knowledge. Towards this end, learning description logic concepts from positive and negative examples has been proposed. However, learning such concepts often takes a long time and state-of-the-art approaches provide limited support for literal data values, although they are crucial for many applications. In this paper, we propose EvoLearner - an evolutionary approach to learn ALCQ(D), which is the attributive language with complement (ALC) paired with qualified cardinality restrictions (Q) and data properties (D). We contribute a novel initialization method for the initial population: starting from positive examples (nodes in the knowledge graph), we perform biased random walks and translate them to description logic concepts. Moreover, we improve support for data properties by maximizing information gain when deciding where to split the data. We show that our approach significantly outperforms the state of the art on the benchmarking framework SML-Bench for structured machine learning. Our ablation study confirms that this is due to our novel initialization method and support for data properties.