 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Question Answering with Reinforcement Learning
Nov 05, 2023Causal questions inquire about causal relationships between different events or phenomena. Specifically, they often aim to determine whether there is a relationship between two phenomena, or to identify all causes/effects of a phenomenon. Causal questions are important for a variety of use cases, including virtual assistants and search engines. However, many current approaches to causal question answering cannot provide explanations or evidence for their answers. Hence, in this paper, we aim to answer causal questions with CauseNet, a large-scale dataset of causal relations and their provenance data. Inspired by recent, successful applications of reinforcement learning to knowledge graph tasks, such as link prediction and fact-checking, we explore the application of reinforcement learning on CauseNet for causal question answering. We introduce an Actor-Critic based agent which learns to search through the graph to answer causal questions. We bootstrap the agent with a supervised learning procedure to deal with large action spaces and sparse rewards. Our evaluation shows that the agent successfully prunes the search space to answer binary causal questions by visiting less than 30 nodes per question compared to over 3,000 nodes by a naive breadth-first search. Our ablation study indicates that our supervised learning strategy provides a strong foundation upon which our reinforcement learning agent improves. The paths returned by our agent explain the mechanisms by which a cause produces an effect. Moreover, for each edge on a path, CauseNet stores its original source on the web allowing for easy verification of paths.
Counterfactual Explanations for Concepts in $\mathcal{ELH}$
Jan 12, 2023Knowledge bases are widely used for information management on the web, enabling high-impact applications such as web search, question answering, and natural language processing. They also serve as the backbone for automatic decision systems, e.g. for medical diagnostics and credit scoring. As stakeholders affected by these decisions would like to understand their situation and verify fair decisions, a number of explanation approaches have been proposed using concepts in description logics. However, the learned concepts can become long and difficult to fathom for non-experts, even when verbalized. Moreover, long concepts do not immediately provide a clear path of action to change one's situation. Counterfactuals answering the question "How must feature values be changed to obtain a different classification?" have been proposed as short, human-friendly explanations for tabular data. In this paper, we transfer the notion of counterfactuals to description logics and propose the first algorithm for generating counterfactual explanations in the description logic $\mathcal{ELH}$. Counterfactual candidates are generated from concepts and the candidates with fewest feature changes are selected as counterfactuals. In case of multiple counterfactuals, we rank them according to the likeliness of their feature combinations. For evaluation, we conduct a user survey to investigate which of the generated counterfactual candidates are preferred for explanation by participants. In a second study, we explore possible use cases for counterfactual explanations.
EvoLearner: Learning Description Logics with Evolutionary Algorithms
Nov 08, 2021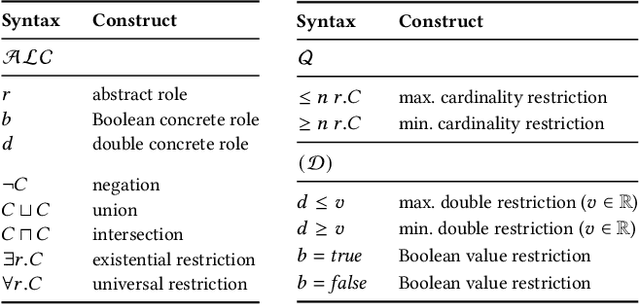
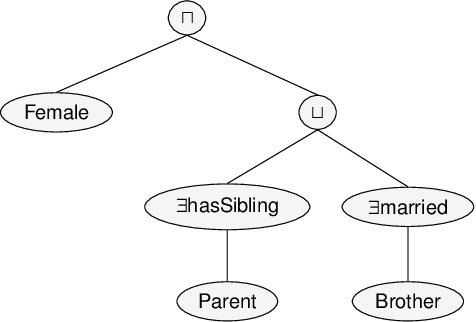
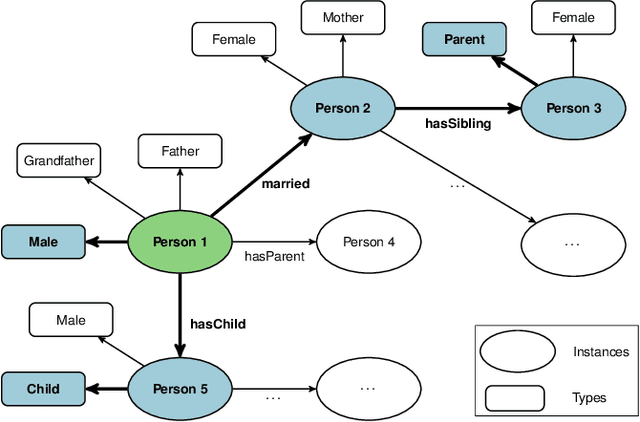
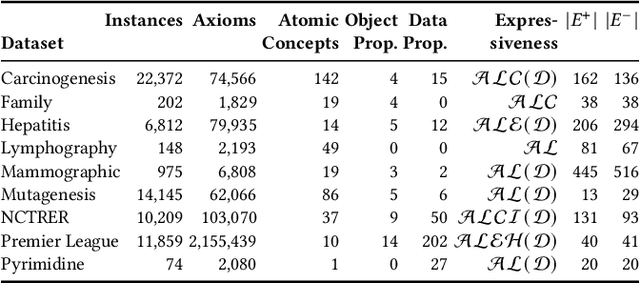
Classifying nodes in knowledge graphs is an important task, e.g., predicting missing types of entities, predicting which molecules cause cancer, or predicting which drugs are promising treatment candidates. While black-box models often achieve high predictive performance, they are only post-hoc and locally explainable and do not allow the learned model to be easily enriched with domain knowledge. Towards this end, learning description logic concepts from positive and negative examples has been proposed. However, learning such concepts often takes a long time and state-of-the-art approaches provide limited support for literal data values, although they are crucial for many applications. In this paper, we propose EvoLearner - an evolutionary approach to learn ALCQ(D), which is the attributive language with complement (ALC) paired with qualified cardinality restrictions (Q) and data properties (D). We contribute a novel initialization method for the initial population: starting from positive examples (nodes in the knowledge graph), we perform biased random walks and translate them to description logic concepts. Moreover, we improve support for data properties by maximizing information gain when deciding where to split the data. We show that our approach significantly outperforms the state of the art on the benchmarking framework SML-Bench for structured machine learning. Our ablation study confirms that this is due to our novel initialization method and support for data properties.