 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame or Not? Enhancing Visual Perception in Vision-Language Models
Dec 29, 2025Vision-language models (VLMs) excel at broad visual understanding but remain coarse-grained, exhibit visual biases, and miss subtle visual details. Existing training corpora reinforce this limitation by emphasizing general recognition ("Is it a cat or a dog?") over fine-grained perception. To address this, we introduce a new training corpus and task designed to enhance the perceptual abilities of VLMs. TWIN is a large-scale dataset of 561,000 image-pair queries that task models to determine whether two visually similar images depict the same object, encouraging attention to nuanced visual cues. The dataset spans a diverse range of everyday objects across contexts, viewpoints, and appearances. Fine-tuning VLMs on TWIN yields notable gains in fine-grained recognition, even on unseen domains such as art, animals, plants, and landmarks. To quantify these gains, we introduce FGVQA, a benchmark suite of 12,000 queries that repurposes fine-grained recognition and retrieval datasets from multiple domains. While existing VLMs struggle on FGVQA, when fine-tuned on TWIN they improve by up to 19.3%, without compromising performance on general VQA benchmarks. Finally, our TWIN dataset scales favorably with object annotations, and our analysis shows that scale is key to performance. We envision TWIN as a drop-in addition to open-source VLM training corpora, advancing perceptual precision of future models. Project webpage: https://glab-caltech.github.io/twin/
No Labels, No Problem: Training Visual Reasoners with Multimodal Verifiers
Dec 09, 2025Visual reasoning is challenging, requiring both precise object grounding and understanding complex spatial relationships. Existing methods fall into two camps: language-only chain-of-thought approaches, which demand large-scale (image, query, answer) supervision, and program-synthesis approaches which use pre-trained models and avoid training, but suffer from flawed logic and erroneous grounding. We propose an annotation-free training framework that improves both reasoning and grounding. Our framework uses AI-powered verifiers: an LLM verifier refines LLM reasoning via reinforcement learning, while a VLM verifier strengthens visual grounding through automated hard-negative mining, eliminating the need for ground truth labels. This design combines the strengths of modern AI systems: advanced language-only reasoning models for decomposing spatial queries into simpler subtasks, and strong vision specialist models improved via performant VLM critics. We evaluate our approach across diverse spatial reasoning tasks, and show that our method improves visual reasoning and surpasses open-source and proprietary models, while with our improved visual grounding model we further outperform recent text-only visual reasoning methods. Project webpage: https://glab-caltech.github.io/valor/
NeurIPS 2025 E2LM Competition : Early Training Evaluation of Language Models
Jun 09, 2025Existing benchmarks have proven effective for assessing the performance of fully trained large language models. However, we find striking differences in the early training stages of small models, where benchmarks often fail to provide meaningful or discriminative signals. To explore how these differences arise, this competition tackles the challenge of designing scientific knowledge evaluation tasks specifically tailored for measuring early training progress of language models. Participants are invited to develop novel evaluation methodologies or adapt existing benchmarks to better capture performance differences among language models. To support this effort, we provide three pre-trained small models (0.5B, 1B, and 3B parameters), along with intermediate checkpoints sampled during training up to 200B tokens. All experiments and development work can be run on widely available free cloud-based GPU platforms, making participation accessible to researchers with limited computational resources. Submissions will be evaluated based on three criteria: the quality of the performance signal they produce, the consistency of model rankings at 1 trillion tokens of training, and their relevance to the scientific knowledge domain. By promoting the design of tailored evaluation strategies for early training, this competition aims to attract a broad range of participants from various disciplines, including those who may not be machine learning experts or have access to dedicated GPU resources. Ultimately, this initiative seeks to make foundational LLM research more systematic and benchmark-informed from the earliest phases of model development.
Visual Agentic AI for Spatial Reasoning with a Dynamic API
Feb 10, 2025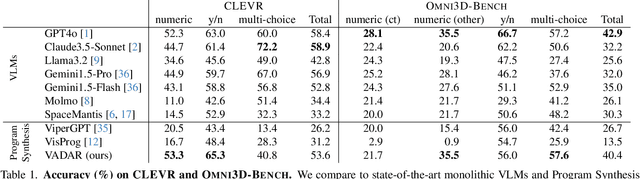
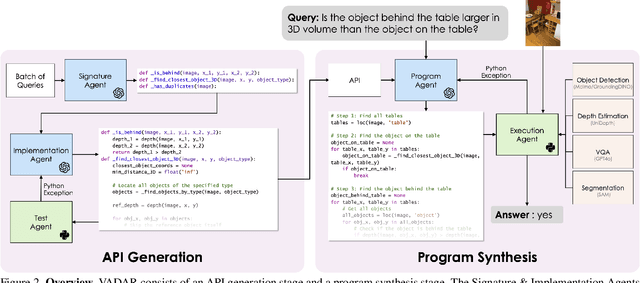

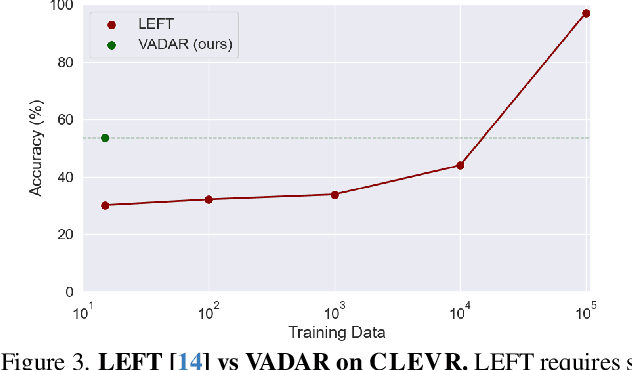
Visual reasoning -- the ability to interpret the visual world -- is crucial for embodied agents that operate within three-dimensional scenes. Progress in AI has led to vision and language models capable of answering questions from images. However, their performance declines when tasked with 3D spatial reasoning. To tackle the complexity of such reasoning problems, we introduce an agentic program synthesis approach where LLM agents collaboratively generate a Pythonic API with new functions to solve common subproblems. Our method overcomes limitations of prior approaches that rely on a static, human-defined API, allowing it to handle a wider range of queries. To assess AI capabilities for 3D understanding, we introduce a new benchmark of queries involving multiple steps of grounding and inference. We show that our method outperforms prior zero-shot models for visual reasoning in 3D and empirically validate the effectiveness of our agentic framework for 3D spatial reasoning tasks. Project website: https://glab-caltech.github.io/vadar/