 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCal-Net: Joint Region-Channel-Wise Calibrated Network for Semantic Segmentation in Cataract Surgery Videos
Paper and Code
Sep 25, 2021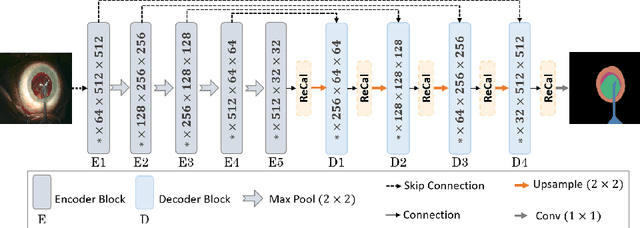

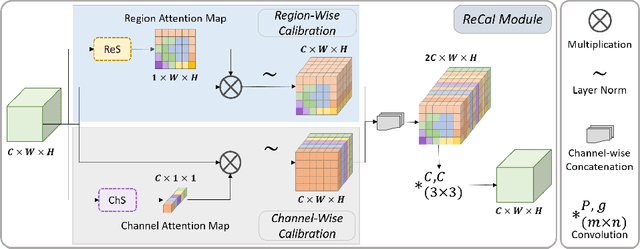
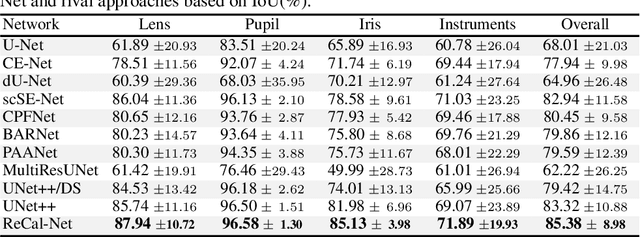
Semantic segmentation in surgical videos is a prerequisite for a broad range of applications towards improving surgical outcomes and surgical video analysis. However, semantic segmentation in surgical videos involves many challenges. In particular, in cataract surgery, various features of the relevant objects such as blunt edges, color and context variation, reflection, transparency, and motion blur pose a challenge for semantic segmentation. In this paper, we propose a novel convolutional module termed as \textit{ReCal} module, which can calibrate the feature maps by employing region intra-and-inter-dependencies and channel-region cross-dependencies. This calibration strategy can effectively enhance semantic representation by correlating different representations of the same semantic label, considering a multi-angle local view centering around each pixel. Thus the proposed module can deal with distant visual characteristics of unique objects as well as cross-similarities in the visual characteristics of different objects. Moreover, we propose a novel network architecture based on the proposed module termed as ReCal-Net. Experimental results confirm the superiority of ReCal-Net compared to rival state-of-the-art approaches for all relevant objects in cataract surgery. Moreover, ablation studies reveal the effectiveness of the ReCal module in boosting semantic segmentation accuracy.