 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPyramid: Enabling Pyramid View and Deformable Pyramid Reception for Semantic Segmentation in Cataract Surgery Videos
Jul 04, 2022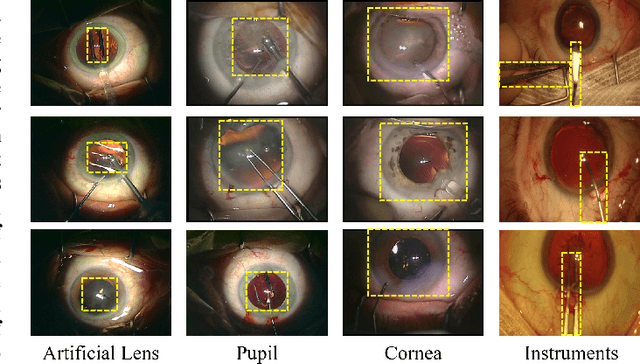



Semantic segmentation in cataract surgery has a wide range of applications contributing to surgical outcome enhancement and clinical risk reduction. However, the varying issues in segmenting the different relevant structures in these surgeries make the designation of a unique network quite challenging. This paper proposes a semantic segmentation network, termed DeepPyramid, that can deal with these challenges using three novelties: (1) a Pyramid View Fusion module which provides a varying-angle global view of the surrounding region centering at each pixel position in the input convolutional feature map; (2) a Deformable Pyramid Reception module which enables a wide deformable receptive field that can adapt to geometric transformations in the object of interest; and (3) a dedicated Pyramid Loss that adaptively supervises multi-scale semantic feature maps. Combined, we show that these modules can effectively boost semantic segmentation performance, especially in the case of transparency, deformability, scalability, and blunt edges in objects. We demonstrate that our approach performs at a state-of-the-art level and outperforms a number of existing methods with a large margin (3.66% overall improvement in intersection over union compared to the best rival approach).
ReCal-Net: Joint Region-Channel-Wise Calibrated Network for Semantic Segmentation in Cataract Surgery Videos
Sep 25, 2021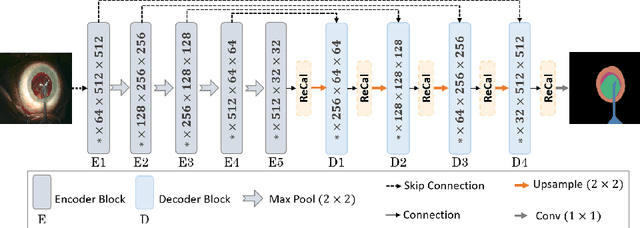

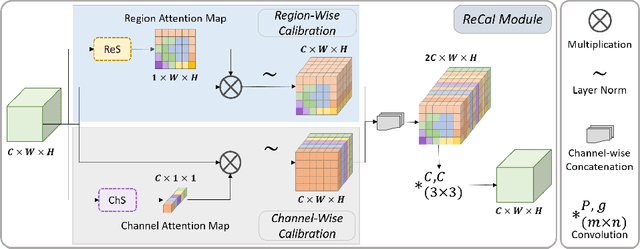
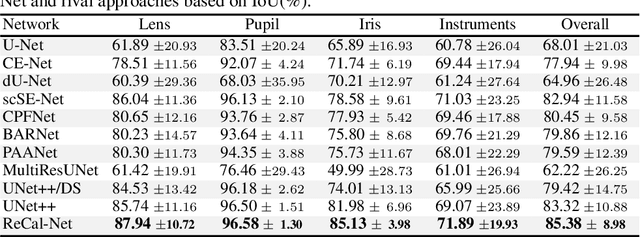
Semantic segmentation in surgical videos is a prerequisite for a broad range of applications towards improving surgical outcomes and surgical video analysis. However, semantic segmentation in surgical videos involves many challenges. In particular, in cataract surgery, various features of the relevant objects such as blunt edges, color and context variation, reflection, transparency, and motion blur pose a challenge for semantic segmentation. In this paper, we propose a novel convolutional module termed as \textit{ReCal} module, which can calibrate the feature maps by employing region intra-and-inter-dependencies and channel-region cross-dependencies. This calibration strategy can effectively enhance semantic representation by correlating different representations of the same semantic label, considering a multi-angle local view centering around each pixel. Thus the proposed module can deal with distant visual characteristics of unique objects as well as cross-similarities in the visual characteristics of different objects. Moreover, we propose a novel network architecture based on the proposed module termed as ReCal-Net. Experimental results confirm the superiority of ReCal-Net compared to rival state-of-the-art approaches for all relevant objects in cataract surgery. Moreover, ablation studies reveal the effectiveness of the ReCal module in boosting semantic segmentation accuracy.
DeepPyram: Enabling Pyramid View and Deformable Pyramid Reception for Semantic Segmentation in Cataract Surgery Videos
Sep 11, 2021Semantic segmentation in cataract surgery has a wide range of applications contributing to surgical outcome enhancement and clinical risk reduction. However, the varying issues in segmenting the different relevant instances make the designation of a unique network quite challenging. This paper proposes a semantic segmentation network termed as DeepPyram that can achieve superior performance in segmenting relevant objects in cataract surgery videos with varying issues. This superiority mainly originates from three modules: (i) Pyramid View Fusion, which provides a varying-angle global view of the surrounding region centering at each pixel position in the input convolutional feature map; (ii) Deformable Pyramid Reception, which enables a wide deformable receptive field that can adapt to geometric transformations in the object of interest; and (iii) Pyramid Loss that adaptively supervises multi-scale semantic feature maps. These modules can effectively boost semantic segmentation performance, especially in the case of transparency, deformability, scalability, and blunt edges in objects. The proposed approach is evaluated using four datasets of cataract surgery for objects with different contextual features and compared with thirteen state-of-the-art segmentation networks. The experimental results confirm that DeepPyram outperforms the rival approaches without imposing additional trainable parameters. Our comprehensive ablation study further proves the effectiveness of the proposed modules.
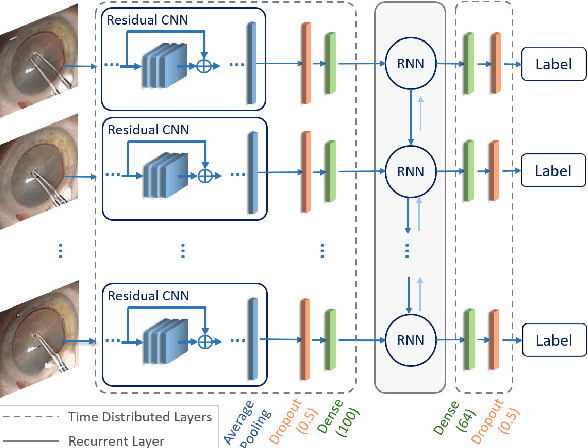
LensID: A CNN-RNN-Based Framework Towards Lens Irregularity Detection in Cataract Surgery Videos
Jul 02, 2021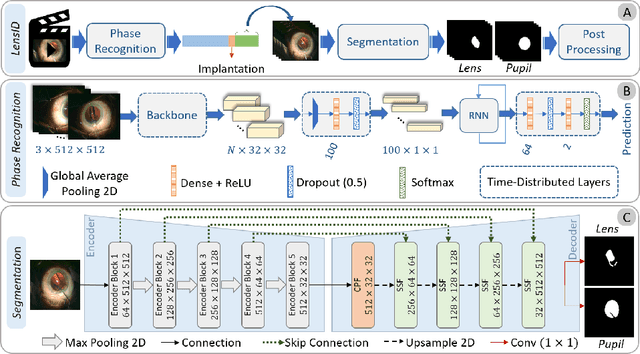
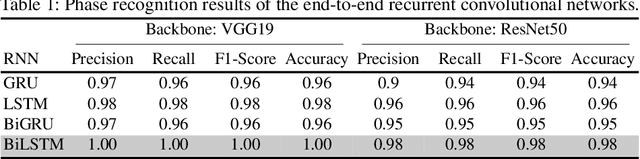

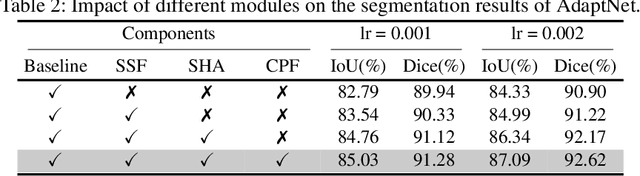
A critical complication after cataract surgery is the dislocation of the lens implant leading to vision deterioration and eye trauma. In order to reduce the risk of this complication, it is vital to discover the risk factors during the surgery. However, studying the relationship between lens dislocation and its suspicious risk factors using numerous videos is a time-extensive procedure. Hence, the surgeons demand an automatic approach to enable a larger-scale and, accordingly, more reliable study. In this paper, we propose a novel framework as the major step towards lens irregularity detection. In particular, we propose (I) an end-to-end recurrent neural network to recognize the lens-implantation phase and (II) a novel semantic segmentation network to segment the lens and pupil after the implantation phase. The phase recognition results reveal the effectiveness of the proposed surgical phase recognition approach. Moreover, the segmentation results confirm the proposed segmentation network's effectiveness compared to state-of-the-art rival approaches.
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization
Apr 29, 2021


In cataract surgery, the operation is performed with the help of a microscope. Since the microscope enables watching real-time surgery by up to two people only, a major part of surgical training is conducted using the recorded videos. To optimize the training procedure with the video content, the surgeons require an automatic relevance detection approach. In addition to relevance-based retrieval, these results can be further used for skill assessment and irregularity detection in cataract surgery videos. In this paper, a three-module framework is proposed to detect and classify the relevant phase segments in cataract videos. Taking advantage of an idle frame recognition network, the video is divided into idle and action segments. To boost the performance in relevance detection, the cornea where the relevant surgical actions are conducted is detected in all frames using Mask R-CNN. The spatiotemporally localized segments containing higher-resolution information about the pupil texture and actions, and complementary temporal information from the same phase are fed into the relevance detection module. This module consists of four parallel recurrent CNNs being responsible to detect four relevant phases that have been defined with medical experts. The results will then be integrated to classify the action phases as irrelevant or one of four relevant phases. Experimental results reveal that the proposed approach outperforms static CNNs and different configurations of feature-based and end-to-end recurrent networks.
Automatic Separation of Compound Figures in Scientific Articles
Oct 18, 2016

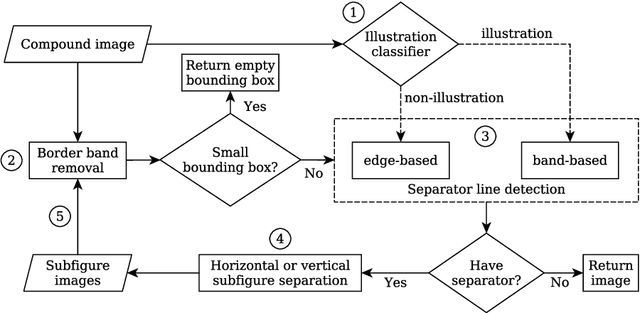
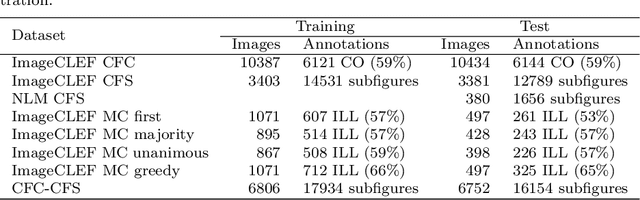
Content-based analysis and retrieval of digital images found in scientific articles is often hindered by images consisting of multiple subfigures (compound figures). We address this problem by proposing a method to automatically classify and separate compound figures, which consists of two main steps: (i) a supervised compound figure classifier (CFC) discriminates between compound and non-compound figures using task-specific image features; and (ii) an image processing algorithm is applied to predicted compound images to perform compound figure separation (CFS). Our CFC approach is shown to achieve state-of-the-art classification performance on a published dataset. Our CFS algorithm shows superior separation accuracy on two different datasets compared to other known automatic approaches. Finally, we propose a method to evaluate the effectiveness of the CFC-CFS process chain and use it to optimize the misclassification loss of CFC for maximal effectiveness in the process chain.