 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaintaining Difficulty: A Margin Scheduler for Triplet Loss in Siamese Networks Training
Mar 27, 2026The Triplet Margin Ranking Loss is one of the most widely used loss functions in Siamese Networks for solving Distance Metric Learning (DML) problems. This loss function depends on a margin parameter μ, which defines the minimum distance that should separate positive and negative pairs during training. In this work, we show that, during training, the effective margin of many triplets often exceeds the predefined value of μ, provided that a sufficient number of triplets violating this margin is observed. This behavior indicates that fixing the margin throughout training may limit the learning process. Based on this observation, we propose a margin scheduler that adjusts the value of μ according to the proportion of easy triplets observed at each epoch, with the goal of maintaining training difficulty over time. We show that the proposed strategy leads to improved performance when compared to both a constant margin and a monotonically increasing margin scheme. Experimental results on four different datasets show consistent gains in verification performance.
Clinical named entity recognition in the Portuguese language: a benchmark of modern BERT models and LLMs
Mar 27, 2026Clinical notes contain valuable unstructured information. Named entity recognition (NER) enables the automatic extraction of medical concepts; however, benchmarks for Portuguese remain scarce. In this study, we aimed to evaluate BERT-based models and large language models (LLMs) for clinical NER in Portuguese and to test strategies for addressing multilabel imbalance. We compared BioBERTpt, BERTimbau, ModernBERT, and mmBERT with LLMs such as GPT-5 and Gemini-2.5, using the public SemClinBr corpus and a private breast cancer dataset. Models were trained under identical conditions and evaluated using precision, recall, and F1-score. Iterative stratification, weighted loss, and oversampling were explored to mitigate class imbalance. The mmBERT-base model achieved the best performance (micro F1 = 0.76), outperforming all other models. Iterative stratification improved class balance and overall performance. Multilingual BERT models, particularly mmBERT, perform strongly for Portuguese clinical NER and can run locally with limited computational resources. Balanced data-splitting strategies further enhance performance.
Structured dataset documentation: a datasheet for CheXpert
May 07, 2021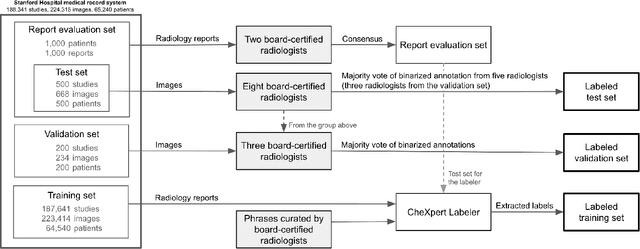
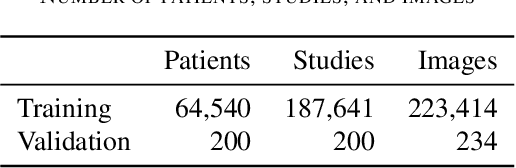
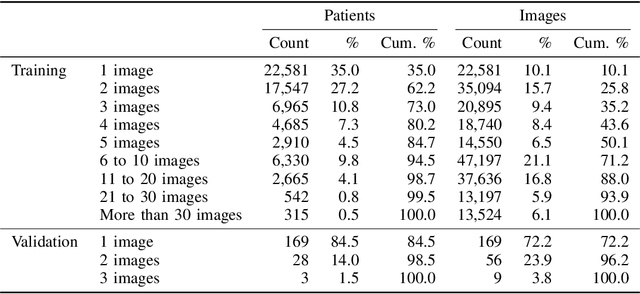

Billions of X-ray images are taken worldwide each year. Machine learning, and deep learning in particular, has shown potential to help radiologists triage and diagnose images. However, deep learning requires large datasets with reliable labels. The CheXpert dataset was created with the participation of board-certified radiologists, resulting in the strong ground truth needed to train deep learning networks. Following the structured format of Datasheets for Datasets, this paper expands on the original CheXpert paper and other sources to show the critical role played by radiologists in the creation of reliable labels and to describe the different aspects of the dataset composition in detail. Such structured documentation intends to increase the awareness in the machine learning and medical communities of the strengths, applications, and evolution of CheXpert, thereby advancing the field of medical image analysis. Another objective of this paper is to put forward this dataset datasheet as an example to the community of how to create detailed and structured descriptions of datasets. We believe that clearly documenting the creation process, the contents, and applications of datasets accelerates the creation of useful and reliable models.
Automatic Separation of Compound Figures in Scientific Articles
Oct 18, 2016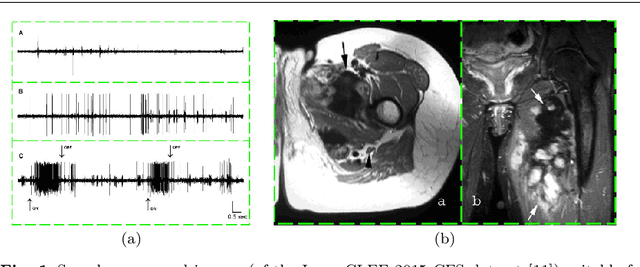

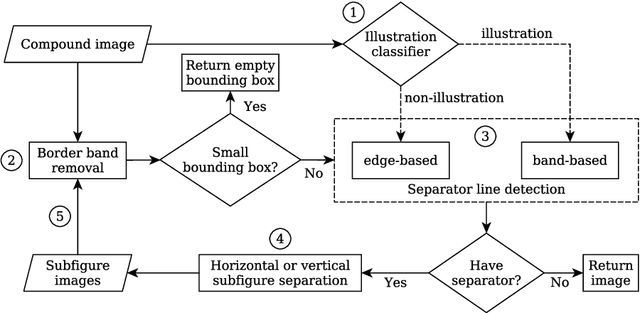
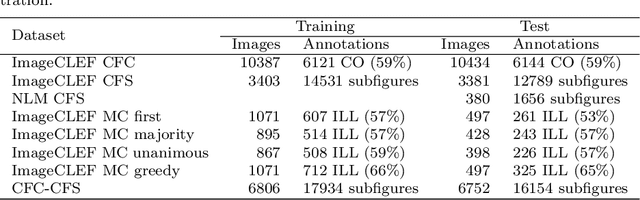
Content-based analysis and retrieval of digital images found in scientific articles is often hindered by images consisting of multiple subfigures (compound figures). We address this problem by proposing a method to automatically classify and separate compound figures, which consists of two main steps: (i) a supervised compound figure classifier (CFC) discriminates between compound and non-compound figures using task-specific image features; and (ii) an image processing algorithm is applied to predicted compound images to perform compound figure separation (CFS). Our CFC approach is shown to achieve state-of-the-art classification performance on a published dataset. Our CFS algorithm shows superior separation accuracy on two different datasets compared to other known automatic approaches. Finally, we propose a method to evaluate the effectiveness of the CFC-CFS process chain and use it to optimize the misclassification loss of CFC for maximal effectiveness in the process chain.