 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured dataset documentation: a datasheet for CheXpert
Paper and Code
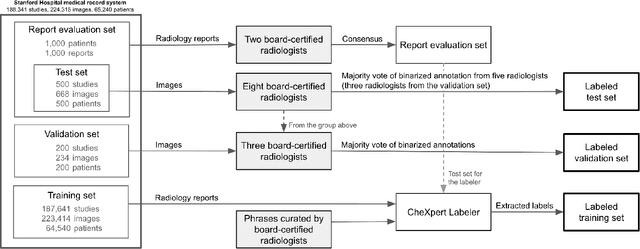
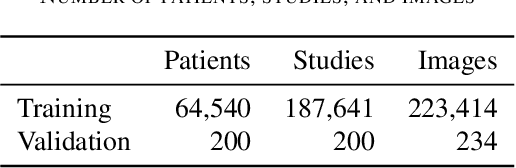
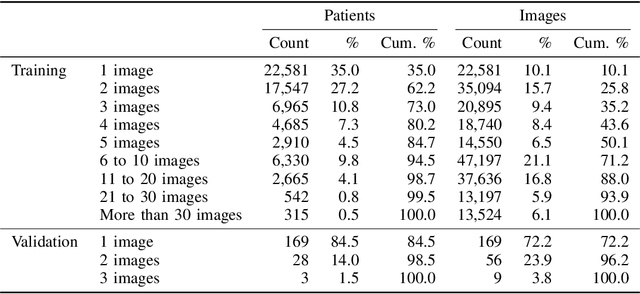

Billions of X-ray images are taken worldwide each year. Machine learning, and deep learning in particular, has shown potential to help radiologists triage and diagnose images. However, deep learning requires large datasets with reliable labels. The CheXpert dataset was created with the participation of board-certified radiologists, resulting in the strong ground truth needed to train deep learning networks. Following the structured format of Datasheets for Datasets, this paper expands on the original CheXpert paper and other sources to show the critical role played by radiologists in the creation of reliable labels and to describe the different aspects of the dataset composition in detail. Such structured documentation intends to increase the awareness in the machine learning and medical communities of the strengths, applications, and evolution of CheXpert, thereby advancing the field of medical image analysis. Another objective of this paper is to put forward this dataset datasheet as an example to the community of how to create detailed and structured descriptions of datasets. We believe that clearly documenting the creation process, the contents, and applications of datasets accelerates the creation of useful and reliable models.