 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHADA: A Graph-based Amalgamation Framework in Image-text Retrieval
Paper and Code
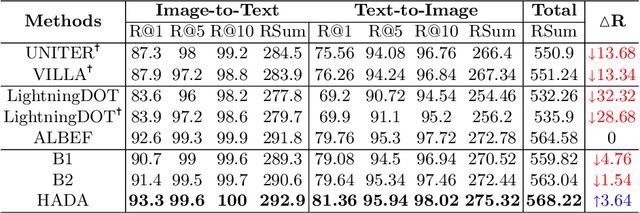
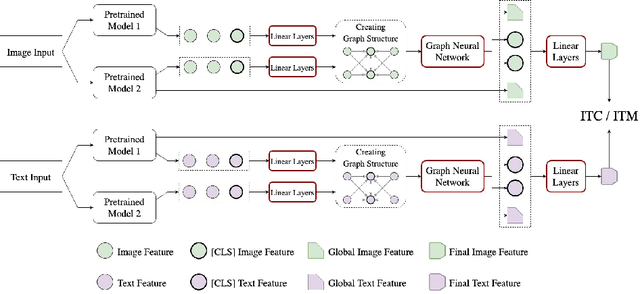
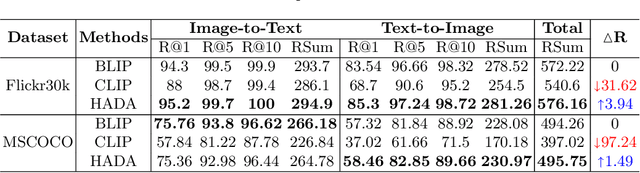
Many models have been proposed for vision and language tasks, especially the image-text retrieval task. All state-of-the-art (SOTA) models in this challenge contained hundreds of millions of parameters. They also were pretrained on a large external dataset that has been proven to make a big improvement in overall performance. It is not easy to propose a new model with a novel architecture and intensively train it on a massive dataset with many GPUs to surpass many SOTA models, which are already available to use on the Internet. In this paper, we proposed a compact graph-based framework, named HADA, which can combine pretrained models to produce a better result, rather than building from scratch. First, we created a graph structure in which the nodes were the features extracted from the pretrained models and the edges connecting them. The graph structure was employed to capture and fuse the information from every pretrained model with each other. Then a graph neural network was applied to update the connection between the nodes to get the representative embedding vector for an image and text. Finally, we used the cosine similarity to match images with their relevant texts and vice versa to ensure a low inference time. Our experiments showed that, although HADA contained a tiny number of trainable parameters, it could increase baseline performance by more than 3.6% in terms of evaluation metrics in the Flickr30k dataset. Additionally, the proposed model did not train on any external dataset and did not require many GPUs but only 1 to train due to its small number of parameters. The source code is available at https://github.com/m2man/HADA.