 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Local and Global Scene-Graph Matching for Image-Text Retrieval
Paper and Code
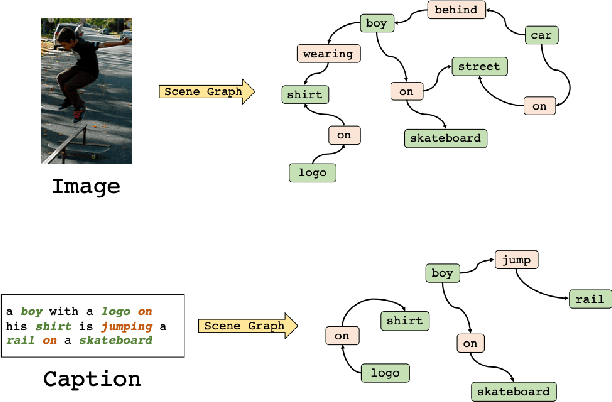
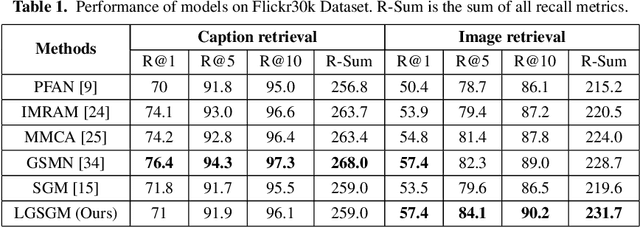
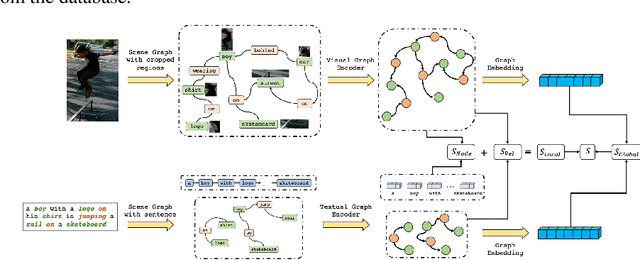
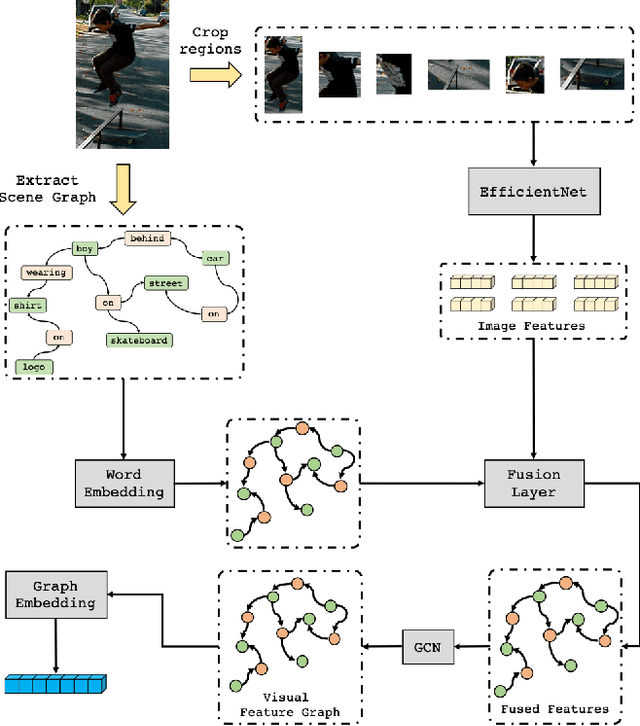
Conventional approaches to image-text retrieval mainly focus on indexing visual objects appearing in pictures but ignore the interactions between these objects. Such objects occurrences and interactions are equivalently useful and important in this field as they are usually mentioned in the text. Scene graph presentation is a suitable method for the image-text matching challenge and obtained good results due to its ability to capture the inter-relationship information. Both images and text are represented in scene graph levels and formulate the retrieval challenge as a scene graph matching challenge. In this paper, we introduce the Local and Global Scene Graph Matching (LGSGM) model that enhances the state-of-the-art method by integrating an extra graph convolution network to capture the general information of a graph. Specifically, for a pair of scene graphs of an image and its caption, two separate models are used to learn the features of each graph's nodes and edges. Then a Siamese-structure graph convolution model is employed to embed graphs into vector forms. We finally combine the graph-level and the vector-level to calculate the similarity of this image-text pair. The empirical experiments show that our enhancement with the combination of levels can improve the performance of the baseline method by increasing the recall by more than 10% on the Flickr30k dataset.