 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Explanation Methods for Multivariate Time Series Classification
Sep 07, 2023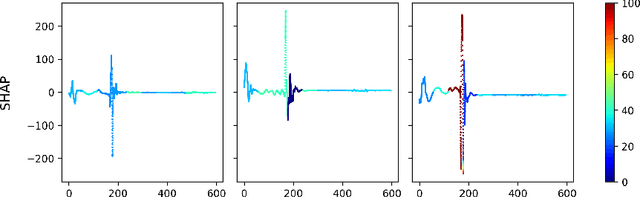

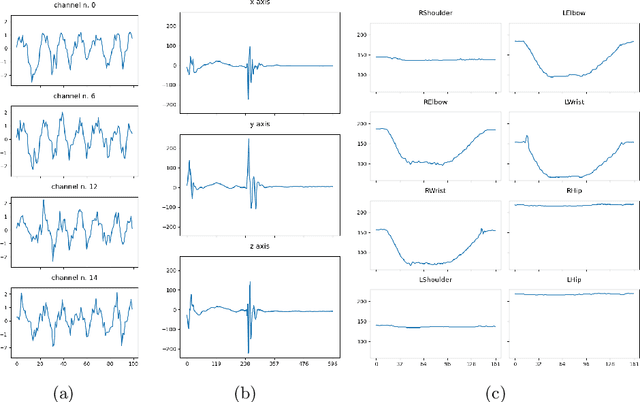

Multivariate time series classification is an important computational task arising in applications where data is recorded over time and over multiple channels. For example, a smartwatch can record the acceleration and orientation of a person's motion, and these signals are recorded as multivariate time series. We can classify this data to understand and predict human movement and various properties such as fitness levels. In many applications classification alone is not enough, we often need to classify but also understand what the model learns (e.g., why was a prediction given, based on what information in the data). The main focus of this paper is on analysing and evaluating explanation methods tailored to Multivariate Time Series Classification (MTSC). We focus on saliency-based explanation methods that can point out the most relevant channels and time series points for the classification decision. We analyse two popular and accurate multivariate time series classifiers, ROCKET and dResNet, as well as two popular explanation methods, SHAP and dCAM. We study these methods on 3 synthetic datasets and 2 real-world datasets and provide a quantitative and qualitative analysis of the explanations provided. We find that flattening the multivariate datasets by concatenating the channels works as well as using multivariate classifiers directly and adaptations of SHAP for MTSC work quite well. Additionally, we also find that the popular synthetic datasets we used are not suitable for time series analysis.
AMEE: A Robust Framework for Explanation Evaluation in Time Series Classification
Jun 08, 2023This paper aims to provide a framework to quantitatively evaluate and rank explanation methods for the time series classification task, which deals with a prevalent data type in critical domains such as healthcare and finance. The recent surge of research interest in explanation methods for time series classification has provided a great variety of explanation techniques. Nevertheless, when these explanation techniques disagree on a specific problem, it remains unclear which of them to use. Comparing the explanations to find the right answer is non-trivial. Two key challenges remain: how to quantitatively and robustly evaluate the informativeness (i.e., relevance for the classification task) of a given explanation method, and how to compare explanation methods side-by-side. We propose AMEE, a Model-Agnostic Explanation Evaluation framework for quantifying and comparing multiple saliency-based explanations for time series classification. Perturbation is added to the input time series guided by the saliency maps (i.e., importance weights for each point in the time series). The impact of perturbation on classification accuracy is measured and used for explanation evaluation. The results show that perturbing discriminative parts of the time series leads to significant changes in classification accuracy. To be robust to different types of perturbations and different types of classifiers, we aggregate the accuracy loss across perturbations and classifiers. This allows us to objectively quantify and rank different explanation methods. We provide a quantitative and qualitative analysis for synthetic datasets, a variety of UCR benchmark datasets, as well as a real-world dataset with known expert ground truth.