 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Classifier-Agnostic Channel Selection for MTSC
Paper and Code
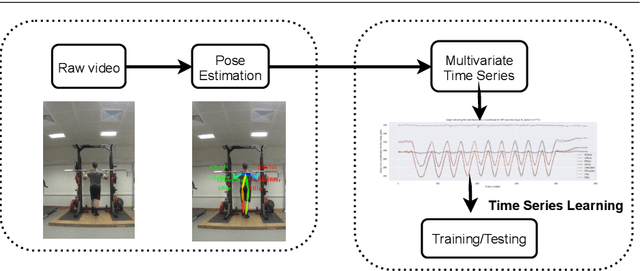
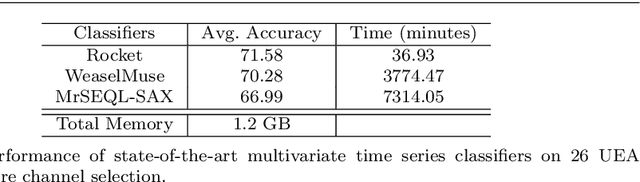
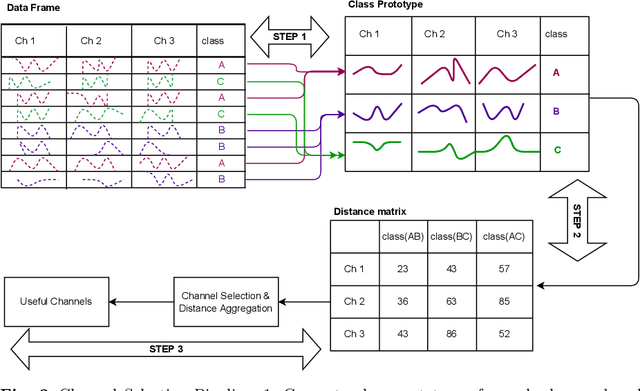
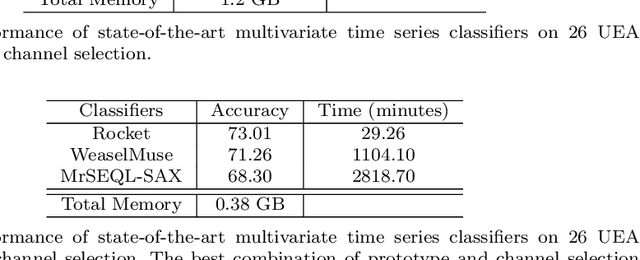
Accuracy is a key focus of current work in time series classification. However, speed and data reduction in many applications is equally important, especially when the data scale and storage requirements increase rapidly. Current MTSC algorithms need hundreds of compute hours to complete training and prediction. This is due to the nature of multivariate time series data, which grows with the number of time series, their length and the number of channels. In many applications, not all the channels are useful for the classification task; hence we require methods that can efficiently select useful channels and thus save computational resources. We propose and evaluate two methods for channel selection. Our techniques work by representing each class by a prototype time series and performing channel selection based on the prototype distance between classes. The main hypothesis is that useful channels enable better separation between classes; hence, channels with the higher distance between class prototypes are more useful. On the UEA Multivariate Time Series Classification (MTSC) benchmark, we show that these techniques achieve significant data reduction and classifier speedup for similar levels of classification accuracy. Channel selection is applied as a pre-processing step before training state-of-the-art MTSC algorithms and saves about 70\% of computation time and data storage, with preserved accuracy. Furthermore, our methods enable even efficient classifiers, such as ROCKET, to achieve better accuracy than using no channel selection or forward channel selection. To further study the impact of our techniques, we present experiments on classifying synthetic multivariate time series datasets with more than 100 channels, as well as a real-world case study on a dataset with 50 channels. Our channel selection methods lead to significant data reduction with preserved or improved accuracy.