 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending TWIG: Zero-Shot Predictive Hyperparameter Selection for KGEs based on Graph Structure
Dec 19, 2024Knowledge Graphs (KGs) have seen increasing use across various domains -- from biomedicine and linguistics to general knowledge modelling. In order to facilitate the analysis of knowledge graphs, Knowledge Graph Embeddings (KGEs) have been developed to automatically analyse KGs and predict new facts based on the information in a KG, a task called "link prediction". Many existing studies have documented that the structure of a KG, KGE model components, and KGE hyperparameters can significantly change how well KGEs perform and what relationships they are able to learn. Recently, the Topologically-Weighted Intelligence Generation (TWIG) model has been proposed as a solution to modelling how each of these elements relate. In this work, we extend the previous research on TWIG and evaluate its ability to simulate the output of the KGE model ComplEx in the cross-KG setting. Our results are twofold. First, TWIG is able to summarise KGE performance on a wide range of hyperparameter settings and KGs being learned, suggesting that it represents a general knowledge of how to predict KGE performance from KG structure. Second, we show that TWIG can successfully predict hyperparameter performance on unseen KGs in the zero-shot setting. This second observation leads us to propose that, with additional research, optimal hyperparameter selection for KGE models could be determined in a pre-hoc manner using TWIG-like methods, rather than by using a full hyperparameter search.
A Survey on Knowledge Graph Structure and Knowledge Graph Embeddings
Dec 13, 2024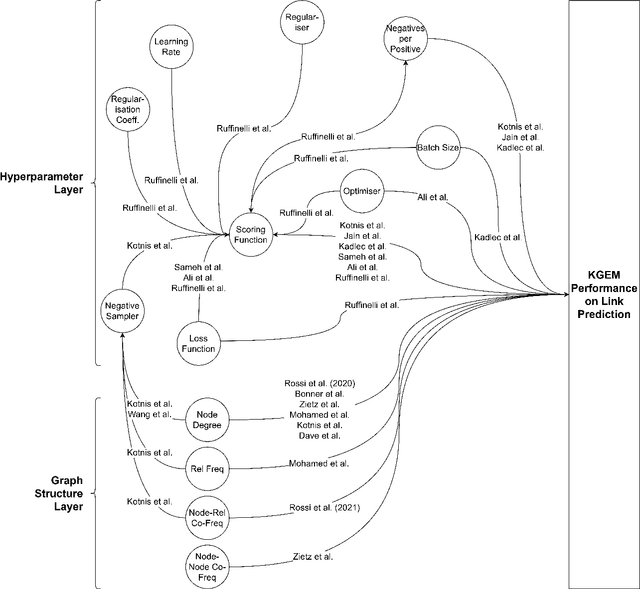
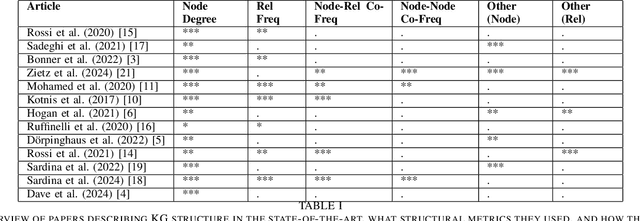

Knowledge Graphs (KGs) and their machine learning counterpart, Knowledge Graph Embedding Models (KGEMs), have seen ever-increasing use in a wide variety of academic and applied settings. In particular, KGEMs are typically applied to KGs to solve the link prediction task; i.e. to predict new facts in the domain of a KG based on existing, observed facts. While this approach has been shown substantial power in many end-use cases, it remains incompletely characterised in terms of how KGEMs react differently to KG structure. This is of particular concern in light of recent studies showing that KG structure can be a significant source of bias as well as partially determinant of overall KGEM performance. This paper seeks to address this gap in the state-of-the-art. This paper provides, to the authors' knowledge, the first comprehensive survey exploring established relationships of Knowledge Graph Embedding Models and Graph structure in the literature. It is the hope of the authors that this work will inspire further studies in this area, and contribute to a more holistic understanding of KGs, KGEMs, and the link prediction task.
TWIG: Towards pre-hoc Hyperparameter Optimisation and Cross-Graph Generalisation via Simulated KGE Models
Feb 08, 2024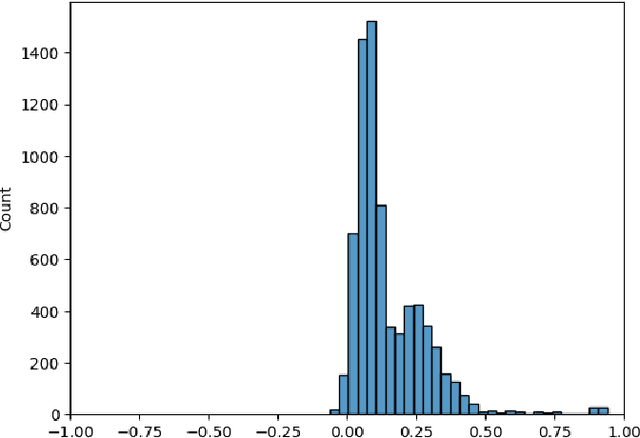
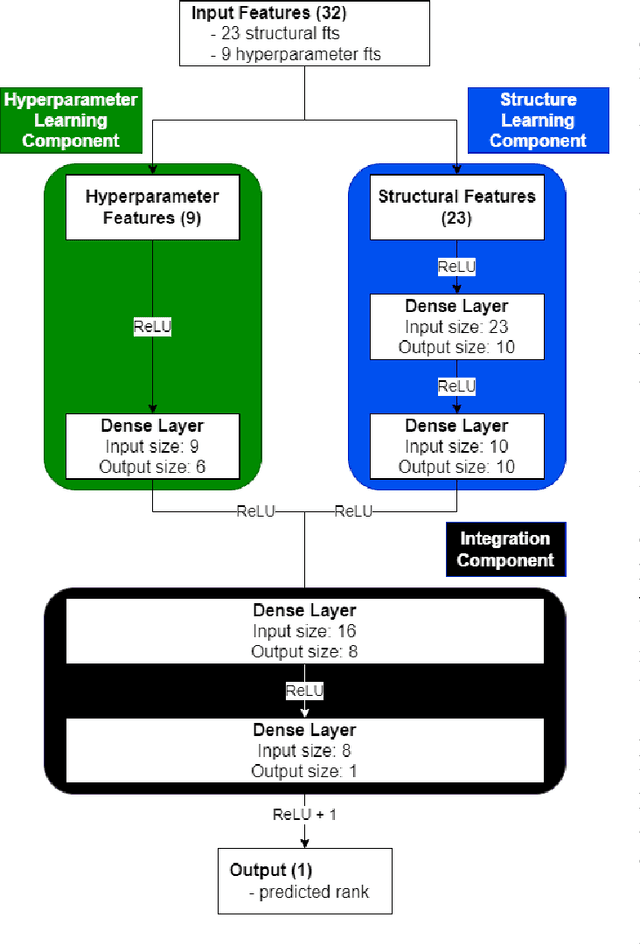
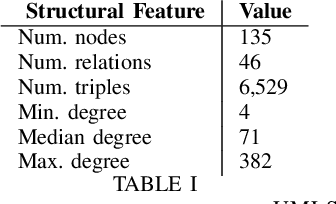

In this paper we introduce TWIG (Topologically-Weighted Intelligence Generation), a novel, embedding-free paradigm for simulating the output of KGEs that uses a tiny fraction of the parameters. TWIG learns weights from inputs that consist of topological features of the graph data, with no coding for latent representations of entities or edges. Our experiments on the UMLS dataset show that a single TWIG neural network can predict the results of state-of-the-art ComplEx-N3 KGE model nearly exactly on across all hyperparameter configurations. To do this it uses a total of 2590 learnable parameters, but accurately predicts the results of 1215 different hyperparameter combinations with a combined cost of 29,322,000 parameters. Based on these results, we make two claims: 1) that KGEs do not learn latent semantics, but only latent representations of structural patterns; 2) that hyperparameter choice in KGEs is a deterministic function of the KGE model and graph structure. We further hypothesise that, as TWIG can simulate KGEs without embeddings, that node and edge embeddings are not needed to learn to accurately predict new facts in KGs. Finally, we formulate all of our findings under the umbrella of the ``Structural Generalisation Hypothesis", which suggests that ``twiggy" embedding-free / data-structure-based learning methods can allow a single neural network to simulate KGE performance, and perhaps solve the Link Prediction task, across many KGs from diverse domains and with different semantics.
Veni, Vidi, Vici: Solving the Myriad of Challenges before Knowledge Graph Learning
Feb 08, 2024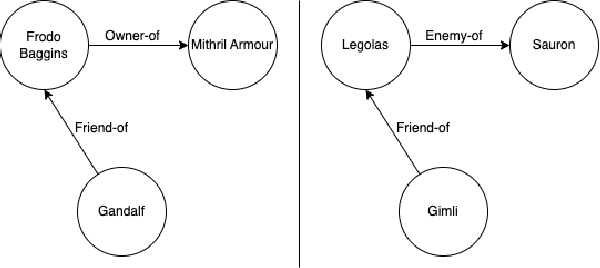
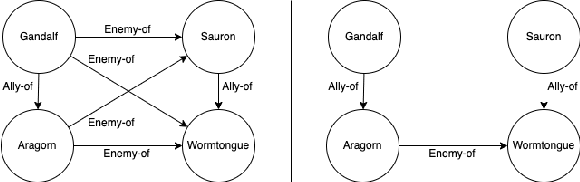
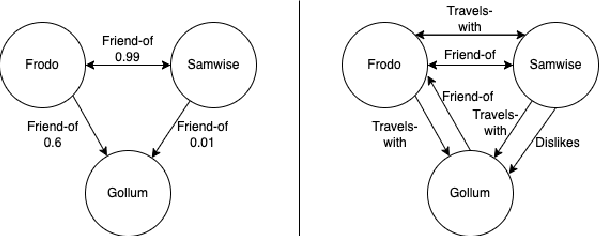
Knowledge Graphs (KGs) have become increasingly common for representing large-scale linked data. However, their immense size has required graph learning systems to assist humans in analysis, interpretation, and pattern detection. While there have been promising results for researcher- and clinician- empowerment through a variety of KG learning systems, we identify four key deficiencies in state-of-the-art graph learning that simultaneously limit KG learning performance and diminish the ability of humans to interface optimally with these learning systems. These deficiencies are: 1) lack of expert knowledge integration, 2) instability to node degree extremity in the KG, 3) lack of consideration for uncertainty and relevance while learning, and 4) lack of explainability. Furthermore, we characterise state-of-the-art attempts to solve each of these problems and note that each attempt has largely been isolated from attempts to solve the other problems. Through a formalisation of these problems and a review of the literature that addresses them, we adopt the position that not only are deficiencies in these four key areas holding back human-KG empowerment, but that the divide-and-conquer approach to solving these problems as individual units rather than a whole is a significant barrier to the interface between humans and KG learning systems. We propose that it is only through integrated, holistic solutions to the limitations of KG learning systems that human and KG learning co-empowerment will be efficiently affected. We finally present our "Veni, Vidi, Vici" framework that sets a roadmap for effectively and efficiently shifting to a holistic co-empowerment model in both the KG learning and the broader machine learning domain.