 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain and Range Aware Synthetic Negatives Generation for Knowledge Graph Embedding Models
Nov 22, 2024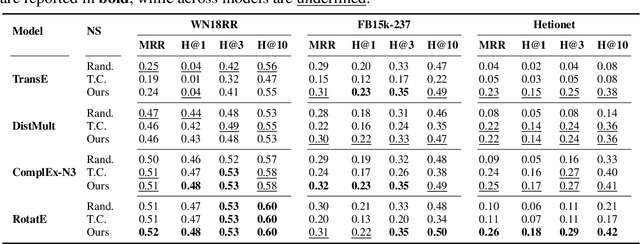
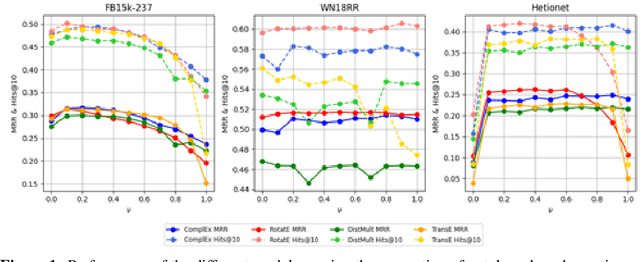

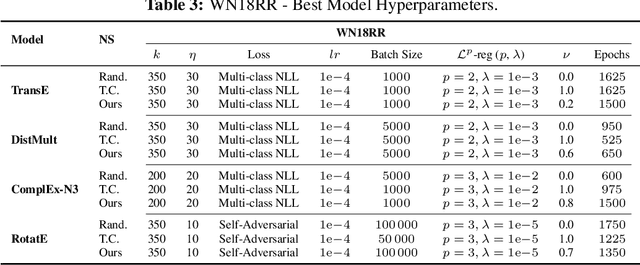
Knowledge Graph Embedding models, representing entities and edges in a low-dimensional space, have been extremely successful at solving tasks related to completing and exploring Knowledge Graphs (KGs). One of the key aspects of training most of these models is teaching to discriminate between true statements positives and false ones (negatives). However, the way in which negatives can be defined is not trivial, as facts missing from the KG are not necessarily false and a set of ground truth negatives is hardly ever given. This makes synthetic negative generation a necessity. Different generation strategies can heavily affect the quality of the embeddings, making it a primary aspect to consider. We revamp a strategy that generates corruptions during training respecting the domain and range of relations, we extend its capabilities and we show our methods bring substantial improvement (+10% MRR) for standard benchmark datasets and over +150% MRR for a larger ontology-backed dataset.