 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Representation Learning for Knowledge Graphs
Sep 30, 2022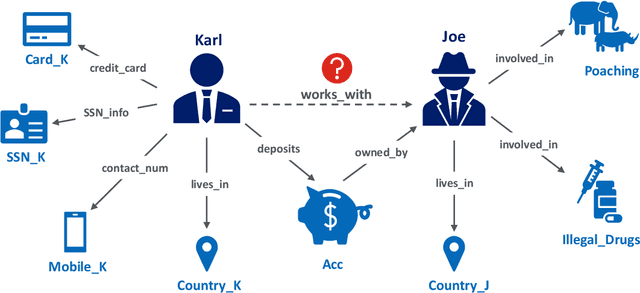

Knowledge graphs represent factual knowledge about the world as relationships between concepts and are critical for intelligent decision making in enterprise applications. New knowledge is inferred from the existing facts in the knowledge graphs by encoding the concepts and relations into low-dimensional feature vector representations. The most effective representations for this task, called Knowledge Graph Embeddings (KGE), are learned through neural network architectures. Due to their impressive predictive performance, they are increasingly used in high-impact domains like healthcare, finance and education. However, are the black-box KGE models adversarially robust for use in domains with high stakes? This thesis argues that state-of-the-art KGE models are vulnerable to data poisoning attacks, that is, their predictive performance can be degraded by systematically crafted perturbations to the training knowledge graph. To support this argument, two novel data poisoning attacks are proposed that craft input deletions or additions at training time to subvert the learned model's performance at inference time. These adversarial attacks target the task of predicting the missing facts in knowledge graphs using KGE models, and the evaluation shows that the simpler attacks are competitive with or outperform the computationally expensive ones. The thesis contributions not only highlight and provide an opportunity to fix the security vulnerabilities of KGE models, but also help to understand the black-box predictive behaviour of KGE models.
Poisoning Knowledge Graph Embeddings via Relation Inference Patterns
Nov 11, 2021

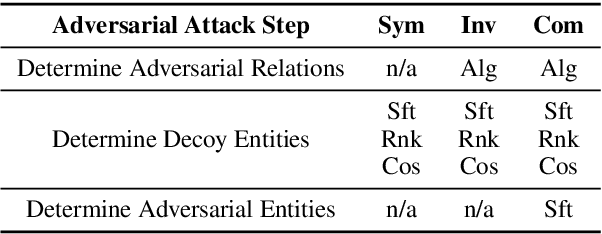
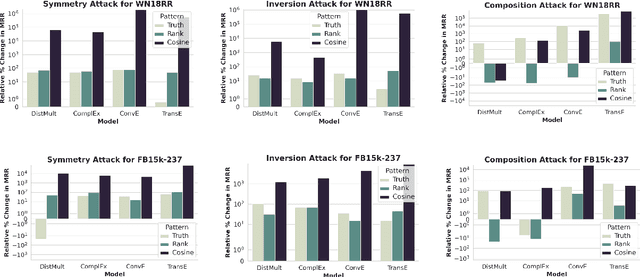
We study the problem of generating data poisoning attacks against Knowledge Graph Embedding (KGE) models for the task of link prediction in knowledge graphs. To poison KGE models, we propose to exploit their inductive abilities which are captured through the relationship patterns like symmetry, inversion and composition in the knowledge graph. Specifically, to degrade the model's prediction confidence on target facts, we propose to improve the model's prediction confidence on a set of decoy facts. Thus, we craft adversarial additions that can improve the model's prediction confidence on decoy facts through different inference patterns. Our experiments demonstrate that the proposed poisoning attacks outperform state-of-art baselines on four KGE models for two publicly available datasets. We also find that the symmetry pattern based attacks generalize across all model-dataset combinations which indicates the sensitivity of KGE models to this pattern.
Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods
Nov 04, 2021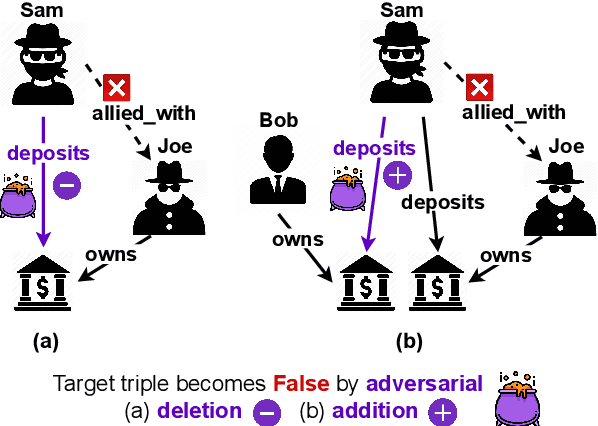

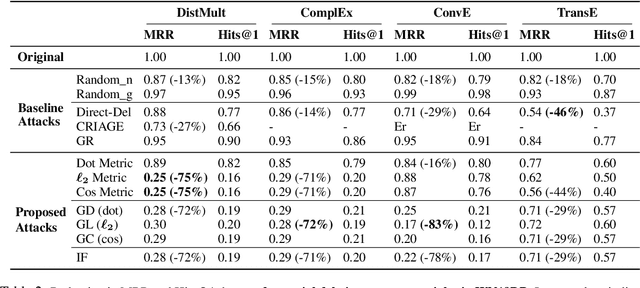
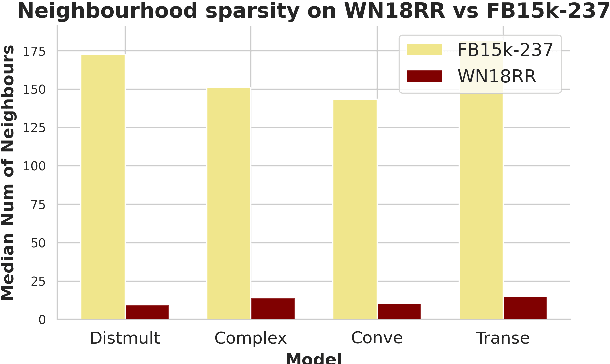
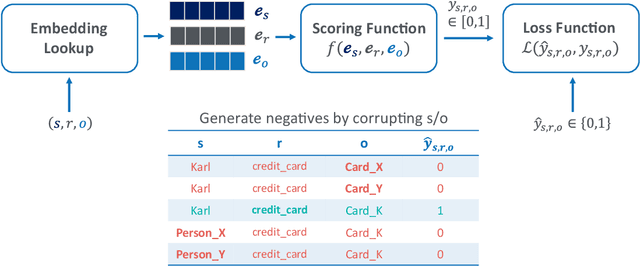
Despite the widespread use of Knowledge Graph Embeddings (KGE), little is known about the security vulnerabilities that might disrupt their intended behaviour. We study data poisoning attacks against KGE models for link prediction. These attacks craft adversarial additions or deletions at training time to cause model failure at test time. To select adversarial deletions, we propose to use the model-agnostic instance attribution methods from Interpretable Machine Learning, which identify the training instances that are most influential to a neural model's predictions on test instances. We use these influential triples as adversarial deletions. We further propose a heuristic method to replace one of the two entities in each influential triple to generate adversarial additions. Our experiments show that the proposed strategies outperform the state-of-art data poisoning attacks on KGE models and improve the MRR degradation due to the attacks by up to 62% over the baselines.