 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Representation Learning for Knowledge Graphs
Paper and Code
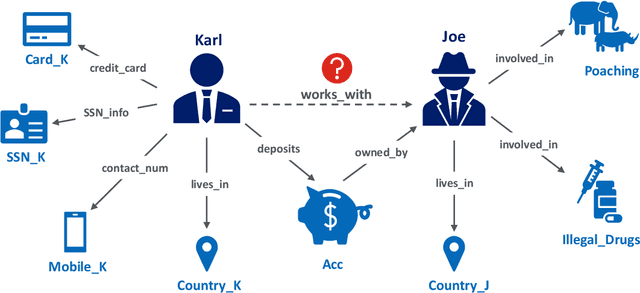

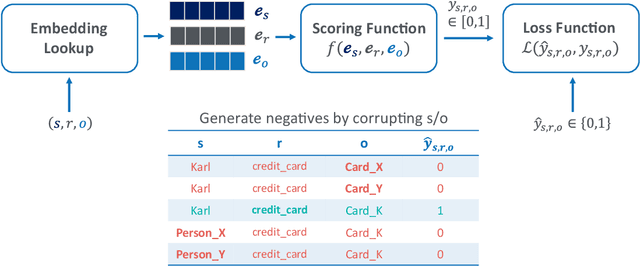
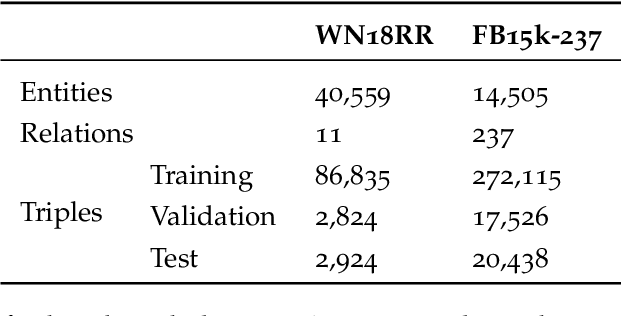
Knowledge graphs represent factual knowledge about the world as relationships between concepts and are critical for intelligent decision making in enterprise applications. New knowledge is inferred from the existing facts in the knowledge graphs by encoding the concepts and relations into low-dimensional feature vector representations. The most effective representations for this task, called Knowledge Graph Embeddings (KGE), are learned through neural network architectures. Due to their impressive predictive performance, they are increasingly used in high-impact domains like healthcare, finance and education. However, are the black-box KGE models adversarially robust for use in domains with high stakes? This thesis argues that state-of-the-art KGE models are vulnerable to data poisoning attacks, that is, their predictive performance can be degraded by systematically crafted perturbations to the training knowledge graph. To support this argument, two novel data poisoning attacks are proposed that craft input deletions or additions at training time to subvert the learned model's performance at inference time. These adversarial attacks target the task of predicting the missing facts in knowledge graphs using KGE models, and the evaluation shows that the simpler attacks are competitive with or outperform the computationally expensive ones. The thesis contributions not only highlight and provide an opportunity to fix the security vulnerabilities of KGE models, but also help to understand the black-box predictive behaviour of KGE models.