 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Linguistic Structures in Neural Networks are Fragile
Nov 15, 2022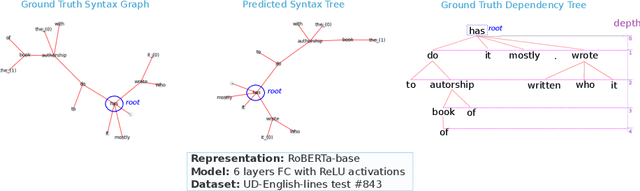
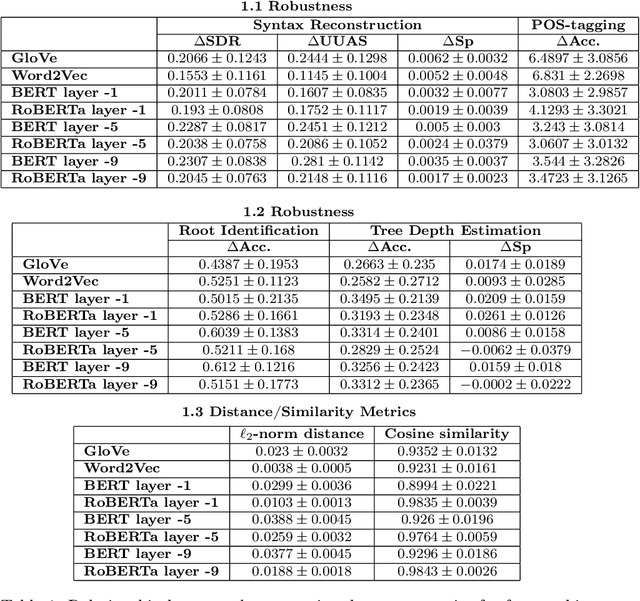
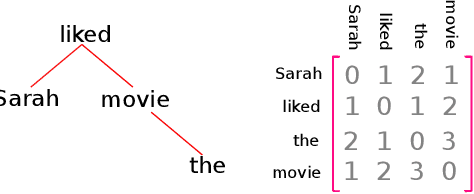
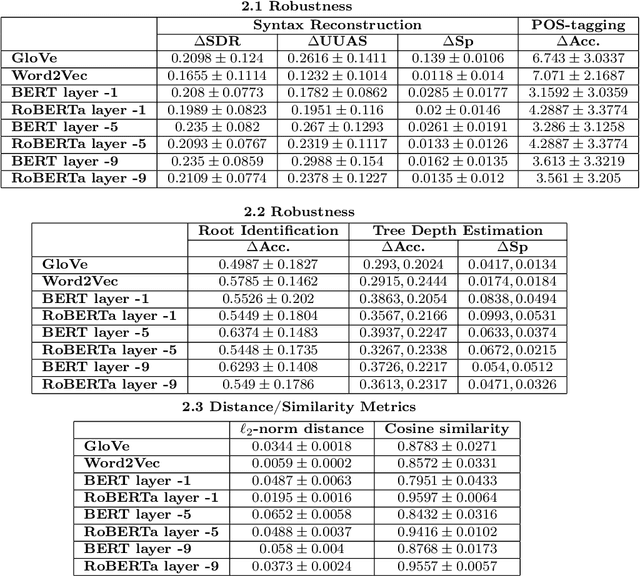
Large language models (LLMs) have been reported to have strong performance on natural language processing tasks. However, performance metrics such as accuracy do not measure the quality of the model in terms of its ability to robustly represent complex linguistic structure. In this work, we propose a framework to evaluate the robustness of linguistic representations using probing tasks. We leverage recent advances in extracting emergent linguistic constructs from LLMs and apply syntax-preserving perturbations to test the stability of these constructs in order to better understand the representations learned by LLMs. Empirically, we study the performance of four LLMs across six different corpora on the proposed robustness measures. We provide evidence that context-free representation (e.g., GloVe) are in some cases competitive with context-dependent representations from modern LLMs (e.g., BERT), yet equally brittle to syntax-preserving manipulations. Emergent syntactic representations in neural networks are brittle, thus our work poses the attention on the risk of comparing such structures to those that are object of a long lasting debate in linguistics.