 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictable Reinforcement Learning Dynamics through Entropy Rate Minimization
Paper and Code
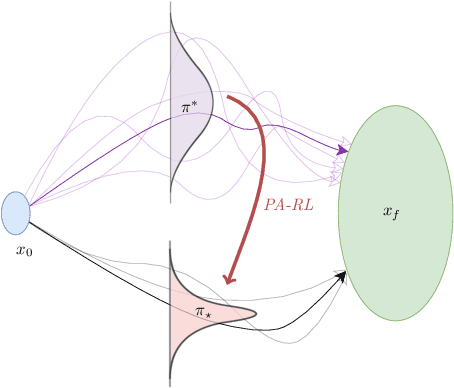
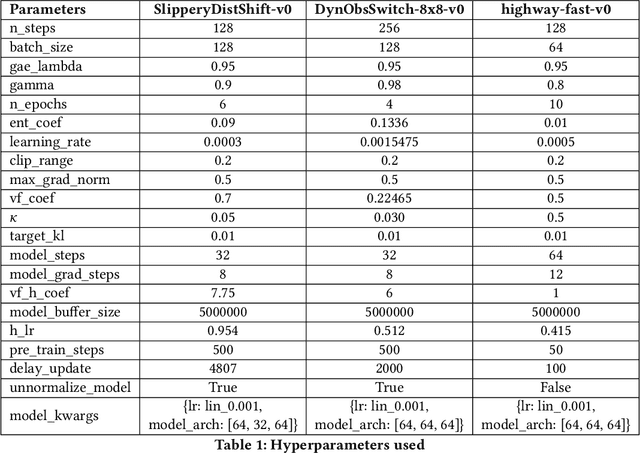
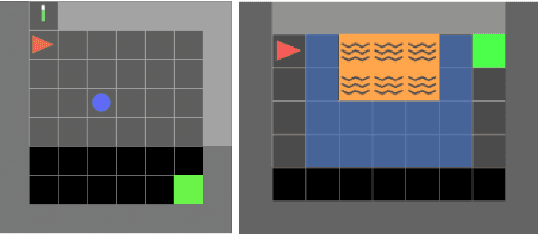
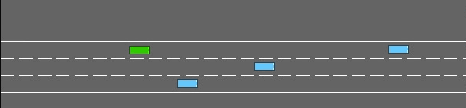
In Reinforcement Learning (RL), agents have no incentive to exhibit predictable behaviors, and are often pushed (through e.g. policy entropy regularization) to randomize their actions in favor of exploration. From a human perspective, this makes RL agents hard to interpret and predict, and from a safety perspective, even harder to formally verify. We propose a novel method to induce predictable behavior in RL agents, referred to as Predictability-Aware RL (PA-RL), which employs the state sequence entropy rate as a predictability measure. We show how the entropy rate can be formulated as an average reward objective, and since its entropy reward function is policy-dependent, we introduce an action-dependent surrogate entropy enabling the use of PG methods. We prove that deterministic policies minimizing the average surrogate reward exist and also minimize the actual entropy rate, and show how, given a learned dynamical model, we are able to approximate the value function associated to the true entropy rate. Finally, we demonstrate the effectiveness of the approach in RL tasks inspired by human-robot use-cases, and show how it produces agents with more predictable behavior while achieving near-optimal rewards.