 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Robust Ageing-Aware Control of Li-ion Battery Systems with Data-Driven Formal Verification
Sep 04, 2025Rechargeable lithium-ion (Li-ion) batteries are a ubiquitous element of modern technology. In the last decades, the production and design of such batteries and their adjacent embedded charging and safety protocols, denoted by Battery Management Systems (BMS), has taken central stage. A fundamental challenge to be addressed is the trade-off between the speed of charging and the ageing behavior, resulting in the loss of capacity in the battery cell. We rely on a high-fidelity physics-based battery model and propose an approach to data-driven charging and safety protocol design. Following a Counterexample-Guided Inductive Synthesis scheme, we combine Reinforcement Learning (RL) with recent developments in data-driven formal methods to obtain a hybrid control strategy: RL is used to synthesise the individual controllers, and a data-driven abstraction guides their partitioning into a switched structure, depending on the initial output measurements of the battery. The resulting discrete selection among RL-based controllers, coupled with the continuous battery dynamics, realises a hybrid system. When a design meets the desired criteria, the abstraction provides probabilistic guarantees on the closed-loop performance of the cell.
On Training-Conditional Conformal Prediction and Binomial Proportion Confidence Intervals
Feb 11, 2025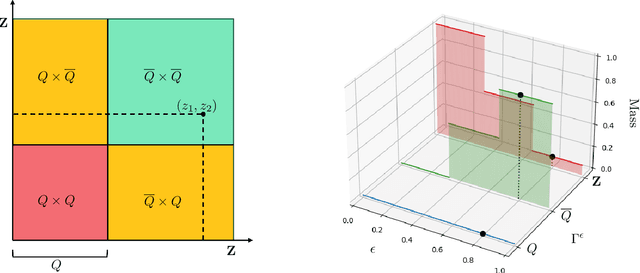
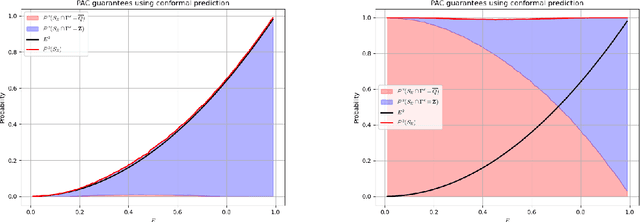
Estimating the expectation of a Bernoulli random variable based on N independent trials is a classical problem in statistics, typically addressed using Binomial Proportion Confidence Intervals (BPCI). In the control systems community, many critical tasks-such as certifying the statistical safety of dynamical systems-can be formulated as BPCI problems. Conformal Prediction (CP), a distribution-free technique for uncertainty quantification, has gained significant attention in recent years and has been applied to various control systems problems, particularly to address uncertainties in learned dynamics or controllers. A variant known as training-conditional CP was recently employed to tackle the problem of safety certification. In this note, we highlight that the use of training-conditional CP in this context does not provide valid safety guarantees. We demonstrate why CP is unsuitable for BPCI problems and argue that traditional BPCI methods are better suited for statistical safety certification.
Robust Event-Driven Interactions in Cooperative Multi-Agent Learning
Apr 07, 2022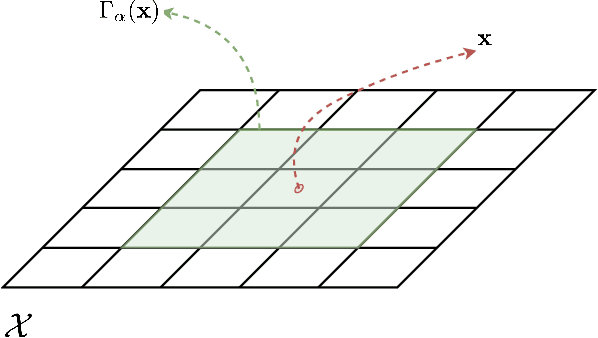
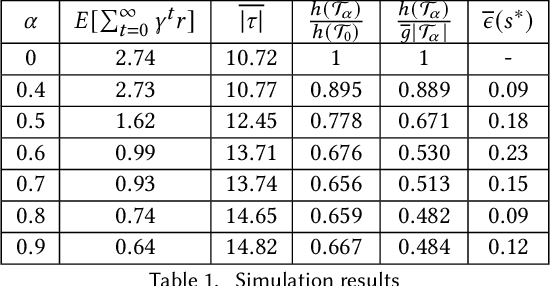
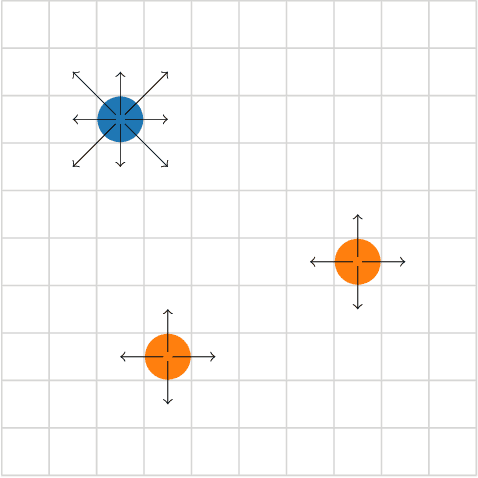
We present an approach to reduce the communication required between agents in a Multi-Agent learning system by exploiting the inherent robustness of the underlying Markov Decision Process. We compute so-called robustness surrogate functions (off-line), that give agents a conservative indication of how far their state measurements can deviate before they need to update other agents in the system. This results in fully distributed decision functions, enabling agents to decide when it is necessary to update others. We derive bounds on the optimality of the resulting systems in terms of the discounted sum of rewards obtained, and show these bounds are a function of the design parameters. Additionally, we extend the results for the case where the robustness surrogate functions are learned from data, and present experimental results demonstrating a significant reduction in communication events between agents.
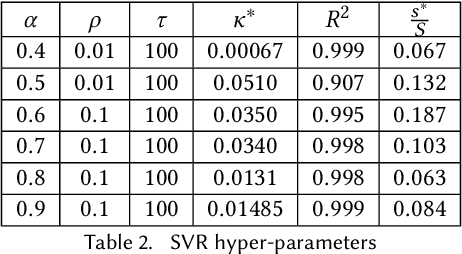
Data-driven Abstractions with Probabilistic Guarantees for Linear PETC Systems
Mar 10, 2022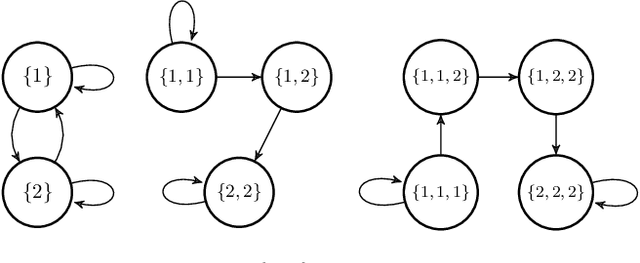
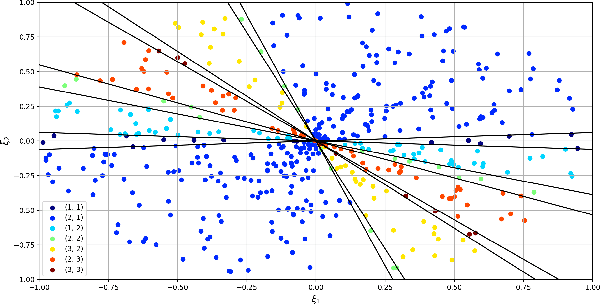
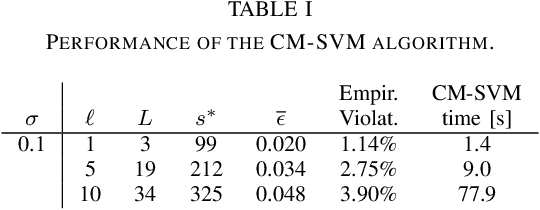
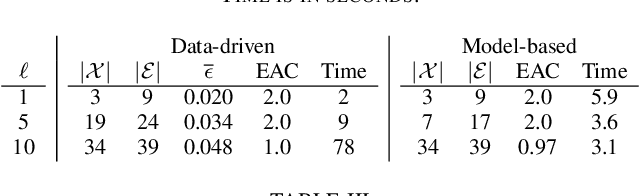
We employ the scenario approach to compute probably approximately correct (PAC) bounds on the average inter-sample time (AIST) generated by an unknown PETC system, based on a finite number of samples. We extend the scenario approach to multiclass SVM algorithms in order to construct a PAC map between the concrete, unknown state-space and the inter-sample times. We then build a traffic model applying an $\ell$-complete relation and find, in the underlying graph, the cycles of minimum and maximum average weight: these provide lower and upper bounds on the AIST. Numerical benchmarks show the practical applicability of our method, which is compared against model-based state-of-the-art tools.
Event-Based Communication in Multi-Agent Distributed Q-Learning
Sep 09, 2021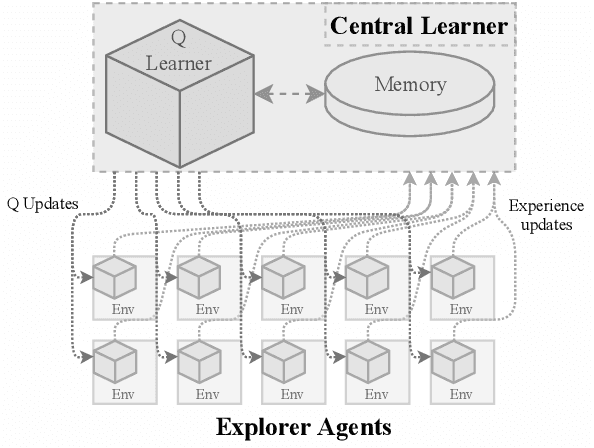
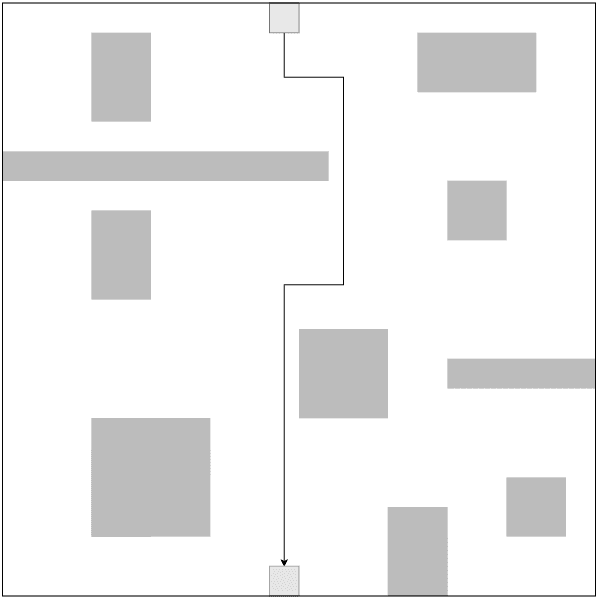
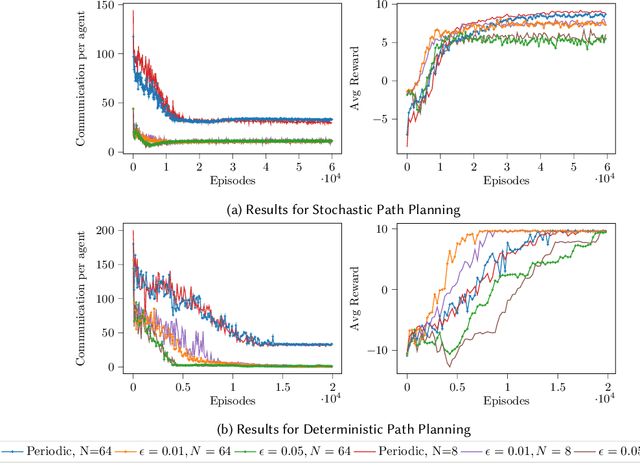
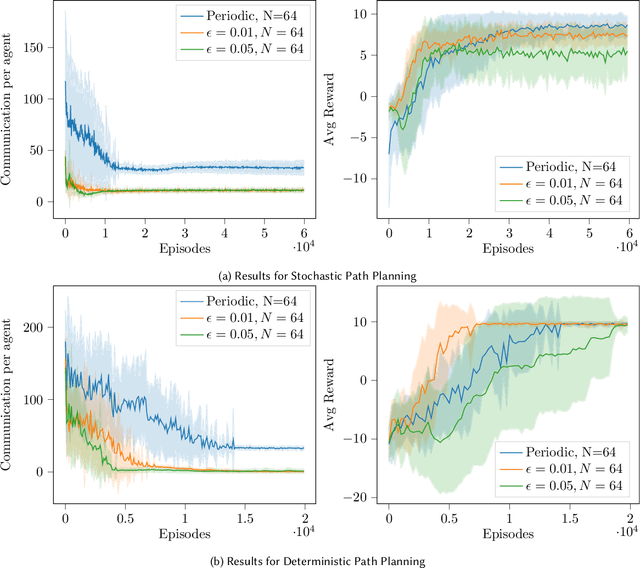
We present in this work an approach to reduce the communication of information needed on a multi-agent learning system inspired by Event Triggered Control (ETC) techniques. We consider a baseline scenario of a distributed Q-learning problem on a Markov Decision Process (MDP). Following an event-based approach, N agents explore the MDP and communicate experiences to a central learner only when necessary, which performs updates of the actor Q functions. We analyse the convergence guarantees retained with respect to a regular Q-learning algorithm, and present experimental results showing that event-based communication results in a substantial reduction of data transmission rates in such distributed systems. Additionally, we discuss what effects (desired and undesired) these event-based approaches have on the learning processes studied, and how they can be applied to more complex multi-agent learning systems.
A Self-Guided Approach for Navigation in a Minimalistic Foraging Robotic Swarm
May 21, 2021

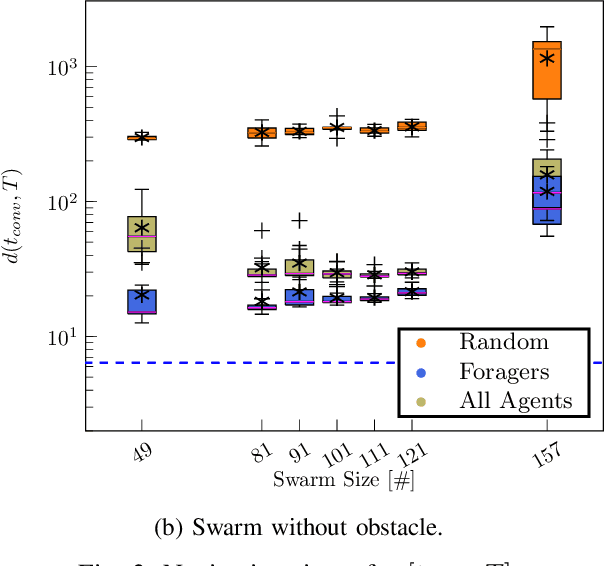
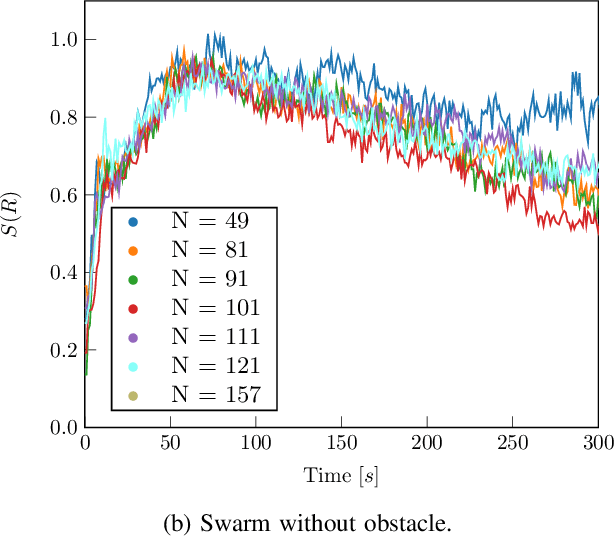
We present a biologically inspired design for swarm foraging based on ant's pheromone deployment, where the swarm is assumed to have very restricted capabilities. The robots do not require global or relative position measurements and the swarm is fully decentralized and needs no infrastructure in place. Additionally, the system only requires one-hop communication over the robot network, we do not make any assumptions about the connectivity of the communication graph and the transmission of information and computation is scalable versus the number of agents. This is done by letting the agents in the swarm act as foragers or as guiding agents (beacons). We present experimental results computed for a swarm of Elisa-3 robots on a simulator, and show how the swarm self-organizes to solve a foraging problem over an unknown environment, converging to trajectories around the shortest path. At last, we discuss the limitations of such a system and propose how the foraging efficiency can be increased.
Mean Field Behaviour of Collaborative Multi-Agent Foragers
Mar 13, 2021
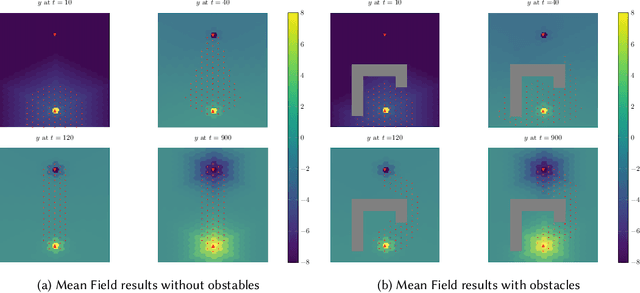

Collaborative multi-agent robotic systems where agents coordinate by modifying a shared environment often result in undesired dynamical couplings that complicate the analysis and experiments when solving a specific problem or task. Simultaneously, biologically-inspired robotics rely on simplifying agents and increasing their number to obtain more efficient solutions to such problems, drawing similarities with natural processes. In this work we focus on the problem of a biologically-inspired multi-agent system solving collaborative foraging. We show how mean field techniques can be used to re-formulate such a stochastic multi-agent problem into a deterministic autonomous system. This de-couples agent dynamics, enabling the computation of limit behaviours and the analysis of optimality guarantees. Furthermore, we analyse how having finite number of agents affects the performance when compared to the mean field limit and we discuss the implications of such limit approximations in this multi-agent system, which have impact on more general collaborative stochastic problems.
Formal Synthesis of Analytic Controllers for Sampled-Data Systems via Genetic Programming
Dec 06, 2018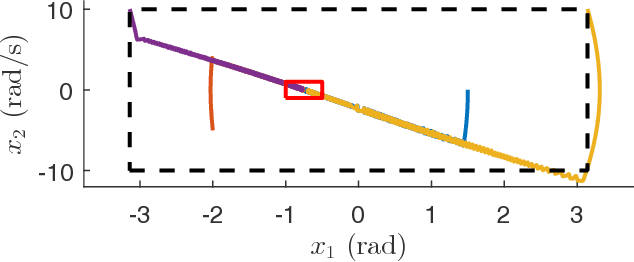
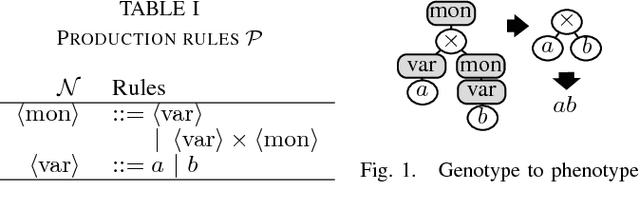
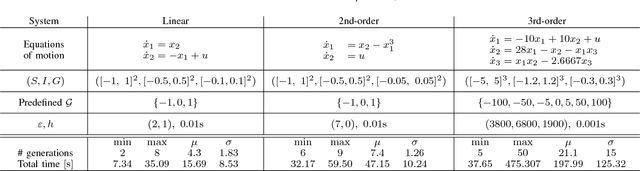

This paper presents an automatic formal controller synthesis method for nonlinear sampled-data systems with safety and reachability specifications. Fundamentally, the presented method is not restricted to polynomial systems and controllers. We consider periodically switched controllers based on a Control Lyapunov Barrier-like functions. The proposed method utilizes genetic programming to synthesize these functions as well as the controller modes. Correctness of the controller are subsequently verified by means of a Satisfiability Modulo Theories solver. Effectiveness of the proposed methodology is demonstrated on multiple systems.