 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Learning of Stochastic Dynamics for Exact Belief Propagation using Bernstein Normalizing Flows
Sep 19, 2025Predicting the distribution of future states in a stochastic system, known as belief propagation, is fundamental to reasoning under uncertainty. However, nonlinear dynamics often make analytical belief propagation intractable, requiring approximate methods. When the system model is unknown and must be learned from data, a key question arises: can we learn a model that (i) universally approximates general nonlinear stochastic dynamics, and (ii) supports analytical belief propagation? This paper establishes the theoretical foundations for a class of models that satisfy both properties. The proposed approach combines the expressiveness of normalizing flows for density estimation with the analytical tractability of Bernstein polynomials. Empirical results show the efficacy of our learned model over state-of-the-art data-driven methods for belief propagation, especially for highly non-linear systems with non-additive, non-Gaussian noise.
Online Pareto-Optimal Decision-Making for Complex Tasks using Active Inference
Jun 17, 2024When a robot autonomously performs a complex task, it frequently must balance competing objectives while maintaining safety. This becomes more difficult in uncertain environments with stochastic outcomes. Enhancing transparency in the robot's behavior and aligning with user preferences are also crucial. This paper introduces a novel framework for multi-objective reinforcement learning that ensures safe task execution, optimizes trade-offs between objectives, and adheres to user preferences. The framework has two main layers: a multi-objective task planner and a high-level selector. The planning layer generates a set of optimal trade-off plans that guarantee satisfaction of a temporal logic task. The selector uses active inference to decide which generated plan best complies with user preferences and aids learning. Operating iteratively, the framework updates a parameterized learning model based on collected data. Case studies and benchmarks on both manipulation and mobile robots show that our framework outperforms other methods and (i) learns multiple optimal trade-offs, (ii) adheres to a user preference, and (iii) allows the user to adjust the balance between (i) and (ii).
Optimal Cost-Preference Trade-off Planning with Multiple Temporal Tasks
Jun 22, 2023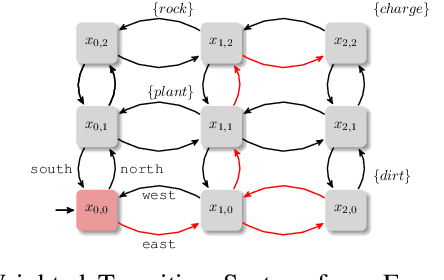
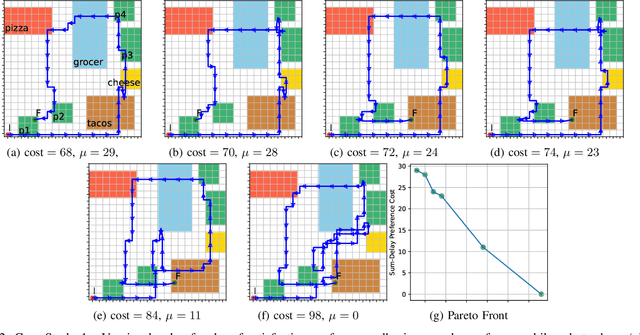
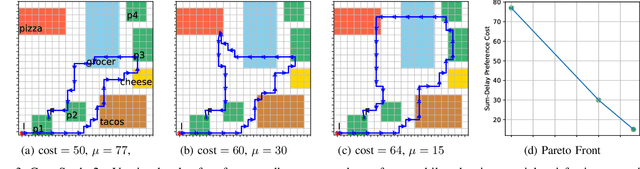

Autonomous robots are increasingly utilized in realistic scenarios with multiple complex tasks. In these scenarios, there may be a preferred way of completing all of the given tasks, but it is often in conflict with optimal execution. Recent work studies preference-based planning, however, they have yet to extend the notion of preference to the behavior of the robot with respect to each task. In this work, we introduce a novel notion of preference that provides a generalized framework to express preferences over individual tasks as well as their relations. Then, we perform an optimal trade-off (Pareto) analysis between behaviors that adhere to the user's preference and the ones that are resource optimal. We introduce an efficient planning framework that generates Pareto-optimal plans given user's preference by extending A* search. Further, we show a method of computing the entire Pareto front (the set of all optimal trade-offs) via an adaptation of a multi-objective A* algorithm. We also present a problem-agnostic search heuristic to enable scalability. We illustrate the power of the framework on both mobile robots and manipulators. Our benchmarks show the effectiveness of the heuristic with up to 2-orders of magnitude speedup.
Let's Collaborate: Regret-based Reactive Synthesis for Robotic Manipulation
Mar 14, 2022
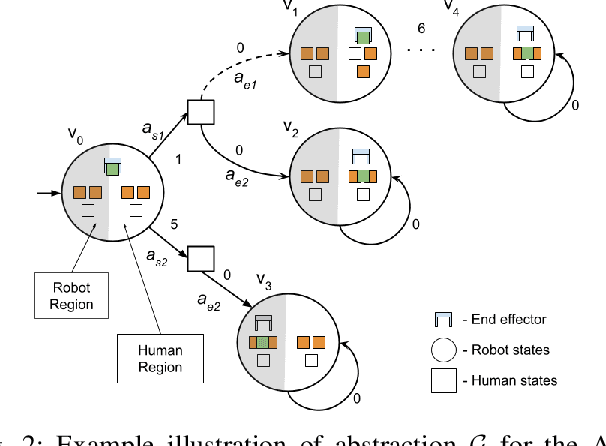
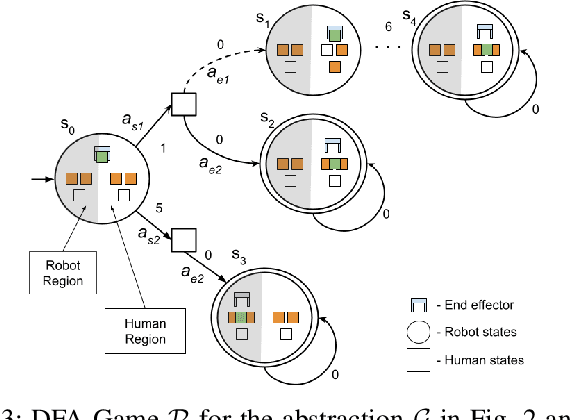

As robots gain capabilities to enter our human-centric world, they require formalism and algorithms that enable smart and efficient interactions. This is challenging, especially for robotic manipulators with complex tasks that may require collaboration with humans. Prior works approach this problem through reactive synthesis and generate strategies for the robot that guarantee task completion by assuming an adversarial human. While this assumption gives a sound solution, it leads to an "unfriendly" robot that is agnostic to the human intentions. We relax this assumption by formulating the problem using the notion of regret. We identify an appropriate definition for regret and develop regret-minimizing synthesis framework that enables the robot to seek cooperation when possible while preserving task completion guarantees. We illustrate the efficacy of our framework via various case studies.