 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Interpretable Approximations to Deep Reinforcement Learning with Soft Decision Trees
Oct 28, 2020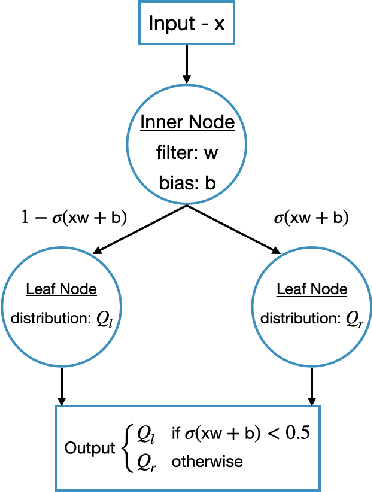
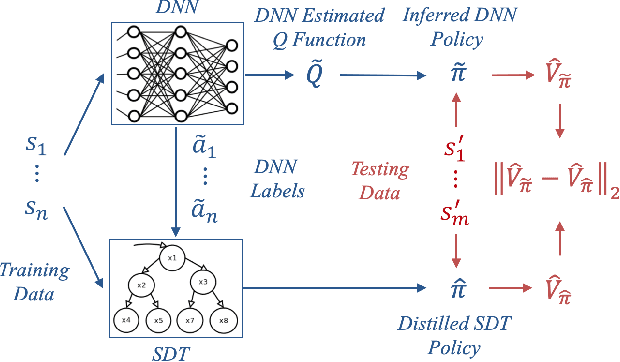
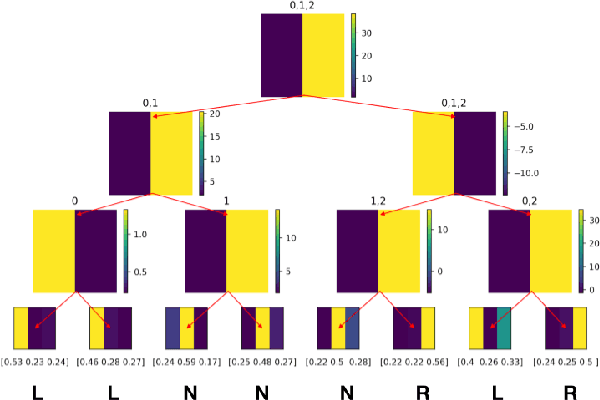
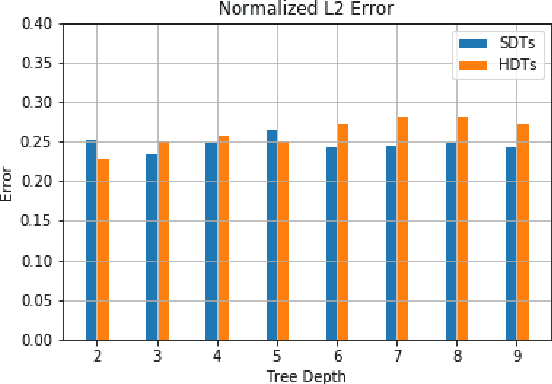
In an ever expanding set of research and application areas, deep neural networks (DNNs) set the bar for algorithm performance. However, depending upon additional constraints such as processing power and execution time limits, or requirements such as verifiable safety guarantees, it may not be feasible to actually use such high-performing DNNs in practice. Many techniques have been developed in recent years to compress or distill complex DNNs into smaller, faster or more understandable models and controllers. This work seeks to provide a quantitative framework with metrics to systematically evaluate the outcome of such conversion processes, and identify reduced models that not only preserve a desired performance level, but also, for example, succinctly explain the latent knowledge represented by a DNN. We illustrate the effectiveness of the proposed approach on the evaluation of decision tree variants in the context of benchmark reinforcement learning tasks.