 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempusBench: An Evaluation Framework for Time-Series Forecasting
Apr 13, 2026Foundation models have transformed natural language processing and computer vision, and a rapidly growing literature on time-series foundation models (TSFMs) seeks to replicate this success in forecasting. While recent open-source models demonstrate the promise of TSFMs, the field lacks a comprehensive and community-accepted model evaluation framework. We see at least four major issues impeding progress on the development of such a framework. First, current evaluation frameworks consist of benchmark forecasting tasks derived from often outdated datasets (e.g., M3), many of which lack clear metadata and overlap with the corpora used to pre-train TSFMs. Second, existing frameworks evaluate models along a narrowly defined set of benchmark forecasting tasks such as forecast horizon length or domain, but overlook core statistical properties such as non-stationarity and seasonality. Third, domain-specific models (e.g., XGBoost) are often compared unfairly, as existing frameworks neglect a systematic and consistent hyperparameter tuning convention for all models. Fourth, visualization tools for interpreting comparative performance are lacking. To address these issues, we introduce TempusBench, an open-source evaluation framework for TSFMs. TempusBench consists of 1) new datasets which are not included in existing TSFM pretraining corpora, 2) a set of novel benchmark tasks that go beyond existing ones, 3) a model evaluation pipeline with a standardized hyperparameter tuning protocol, and 4) a tensorboard-based visualization interface. We provide access to our code on GitHub: https://github.com/Smlcrm/TempusBench.
Bi-Level Policy Optimization with Nyström Hypergradients
May 16, 2025The dependency of the actor on the critic in actor-critic (AC) reinforcement learning means that AC can be characterized as a bilevel optimization (BLO) problem, also called a Stackelberg game. This characterization motivates two modifications to vanilla AC algorithms. First, the critic's update should be nested to learn a best response to the actor's policy. Second, the actor should update according to a hypergradient that takes changes in the critic's behavior into account. Computing this hypergradient involves finding an inverse Hessian vector product, a process that can be numerically unstable. We thus propose a new algorithm, Bilevel Policy Optimization with Nystr\"om Hypergradients (BLPO), which uses nesting to account for the nested structure of BLO, and leverages the Nystr\"om method to compute the hypergradient. Theoretically, we prove BLPO converges to (a point that satisfies the necessary conditions for) a local strong Stackelberg equilibrium in polynomial time with high probability, assuming a linear parametrization of the critic's objective. Empirically, we demonstrate that BLPO performs on par with or better than PPO on a variety of discrete and continuous control tasks.
Efficient Inverse Multiagent Learning
Feb 20, 2025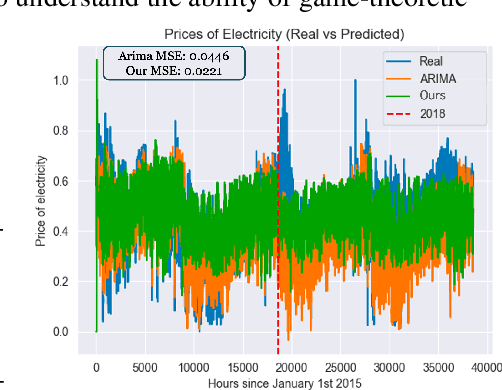

In this paper, we study inverse game theory (resp. inverse multiagent learning) in which the goal is to find parameters of a game's payoff functions for which the expected (resp. sampled) behavior is an equilibrium. We formulate these problems as generative-adversarial (i.e., min-max) optimization problems, for which we develop polynomial-time algorithms to solve, the former of which relies on an exact first-order oracle, and the latter, a stochastic one. We extend our approach to solve inverse multiagent simulacral learning in polynomial time and number of samples. In these problems, we seek a simulacrum, meaning parameters and an associated equilibrium that replicate the given observations in expectation. We find that our approach outperforms the widely-used ARIMA method in predicting prices in Spanish electricity markets based on time-series data.
Flow-Based Synthesis of Reactive Tests for Discrete Decision-Making Systems with Temporal Logic Specifications
Apr 15, 2024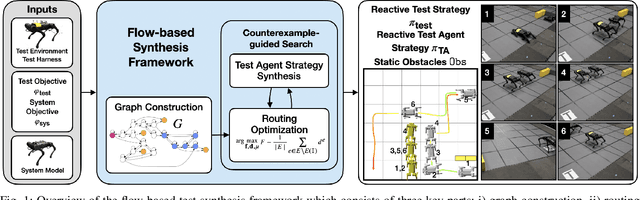
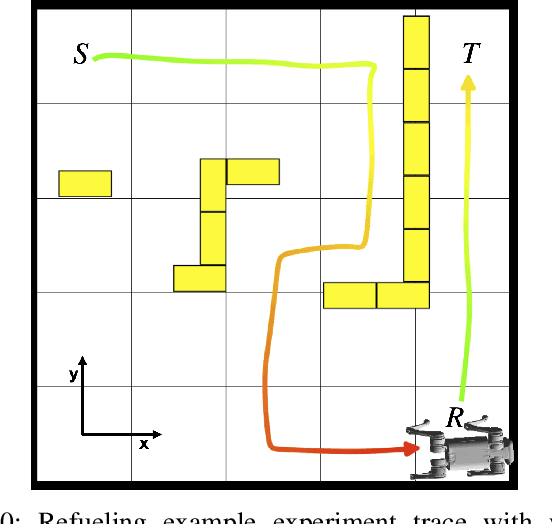

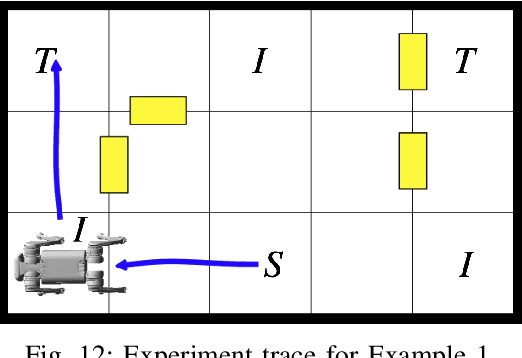
Designing tests to evaluate if a given autonomous system satisfies complex specifications is challenging due to the complexity of these systems. This work proposes a flow-based approach for reactive test synthesis from temporal logic specifications, enabling the synthesis of test environments consisting of static and reactive obstacles and dynamic test agents. The temporal logic specifications describe desired test behavior, including system requirements as well as a test objective that is not revealed to the system. The synthesized test strategy places restrictions on system actions in reaction to the system state. The tests are minimally restrictive and accomplish the test objective while ensuring realizability of the system's objective without aiding it (semi-cooperative setting). Automata theory and flow networks are leveraged to formulate a mixed-integer linear program (MILP) to synthesize the test strategy. For a dynamic test agent, the agent strategy is synthesized for a GR(1) specification constructed from the solution of the MILP. If the specification is unrealizable by the dynamics of the test agent, a counterexample-guided approach is used to resolve the MILP until a strategy is found. This flow-based, reactive test synthesis is conducted offline and is agnostic to the system controller. Finally, the resulting test strategy is demonstrated in simulation and experimentally on a pair of quadrupedal robots for a variety of specifications.
Robust No-Regret Learning in Min-Max Stackelberg Games
Apr 13, 2022
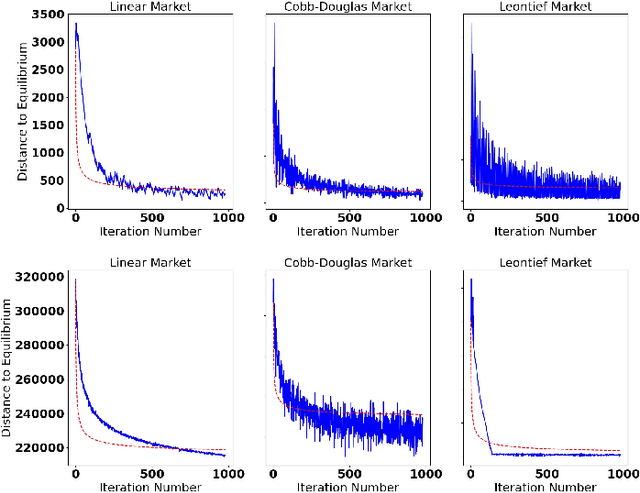
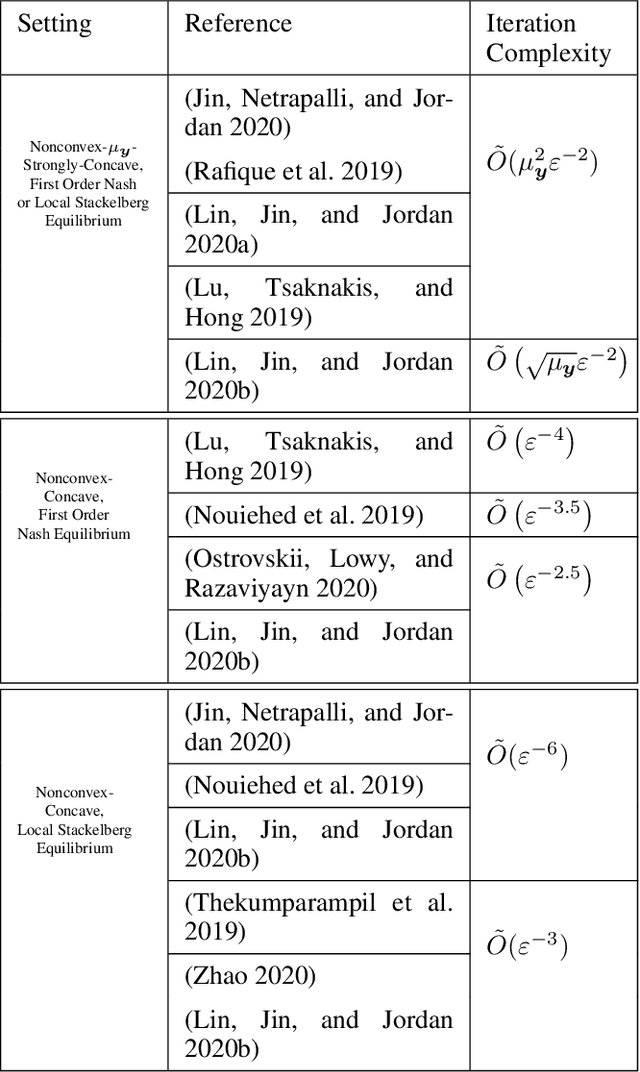
The behavior of no-regret learning algorithms is well understood in two-player min-max (i.e, zero-sum) games. In this paper, we investigate the behavior of no-regret learning in min-max games with dependent strategy sets, where the strategy of the first player constrains the behavior of the second. Such games are best understood as sequential, i.e., min-max Stackelberg, games. We consider two settings, one in which only the first player chooses their actions using a no-regret algorithm while the second player best responds, and one in which both players use no-regret algorithms. For the former case, we show that no-regret dynamics converge to a Stackelberg equilibrium. For the latter case, we introduce a new type of regret, which we call Lagrangian regret, and show that if both players minimize their Lagrangian regrets, then play converges to a Stackelberg equilibrium. We then observe that online mirror descent (OMD) dynamics in these two settings correspond respectively to a known nested (i.e., sequential) gradient descent-ascent (GDA) algorithm and a new simultaneous GDA-like algorithm, thereby establishing convergence of these algorithms to Stackelberg equilibrium. Finally, we analyze the robustness of OMD dynamics to perturbations by investigating online min-max Stackelberg games. We prove that OMD dynamics are robust for a large class of online min-max games with independent strategy sets. In the dependent case, we demonstrate the robustness of OMD dynamics experimentally by simulating them in online Fisher markets, a canonical example of a min-max Stackelberg game with dependent strategy sets.
Convex-Concave Min-Max Stackelberg Games
Oct 05, 2021
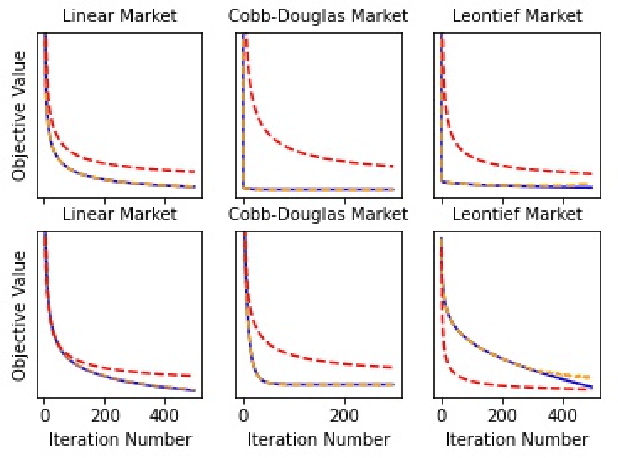

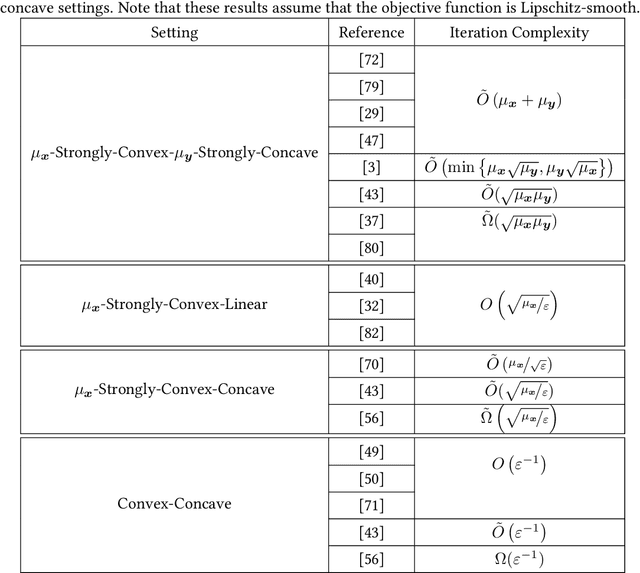
Min-max optimization problems (i.e., min-max games) have been attracting a great deal of attention because of their applicability to a wide range of machine learning problems. Although significant progress has been made recently, the literature to date has focused on games with independent strategy sets; little is known about solving games with dependent strategy sets, which can be characterized as min-max Stackelberg games. We introduce two first-order methods that solve a large class of convex-concave min-max Stackelberg games, and show that our methods converge in polynomial time. Min-max Stackelberg games were first studied by Wald, under the posthumous name of Wald's maximin model, a variant of which is the main paradigm used in robust optimization, which means that our methods can likewise solve many convex robust optimization problems. We observe that the computation of competitive equilibria in Fisher markets also comprises a min-max Stackelberg game. Further, we demonstrate the efficacy and efficiency of our algorithms in practice by computing competitive equilibria in Fisher markets with varying utility structures. Our experiments suggest potential ways to extend our theoretical results, by demonstrating how different smoothness properties can affect the convergence rate of our algorithms.