 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of DNN-based White-Box Explainable AI Methods in Network Security
Jan 14, 2025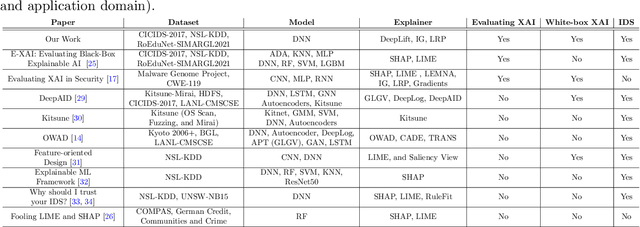
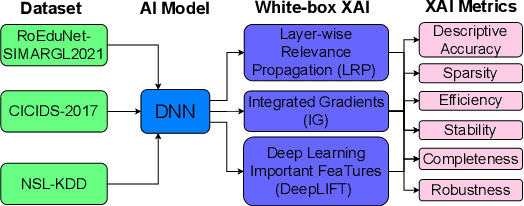
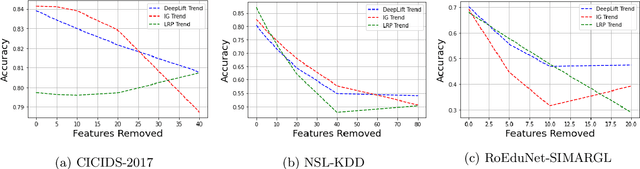
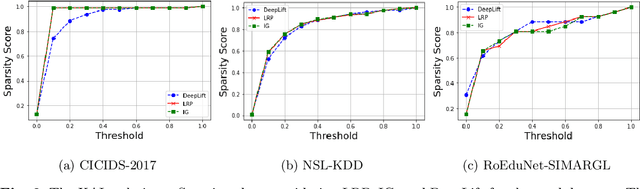
New research focuses on creating artificial intelligence (AI) solutions for network intrusion detection systems (NIDS), drawing its inspiration from the ever-growing number of intrusions on networked systems, increasing its complexity and intelligibility. Hence, the use of explainable AI (XAI) techniques in real-world intrusion detection systems comes from the requirement to comprehend and elucidate black-box AI models to security analysts. In an effort to meet such requirements, this paper focuses on applying and evaluating White-Box XAI techniques (particularly LRP, IG, and DeepLift) for NIDS via an end-to-end framework for neural network models, using three widely used network intrusion datasets (NSL-KDD, CICIDS-2017, and RoEduNet-SIMARGL2021), assessing its global and local scopes, and examining six distinct assessment measures (descriptive accuracy, sparsity, stability, robustness, efficiency, and completeness). We also compare the performance of white-box XAI methods with black-box XAI methods. The results show that using White-box XAI techniques scores high in robustness and completeness, which are crucial metrics for IDS. Moreover, the source codes for the programs developed for our XAI evaluation framework are available to be improved and used by the research community.
HopTrack: A Real-time Multi-Object Tracking System for Embedded Devices
Nov 01, 2024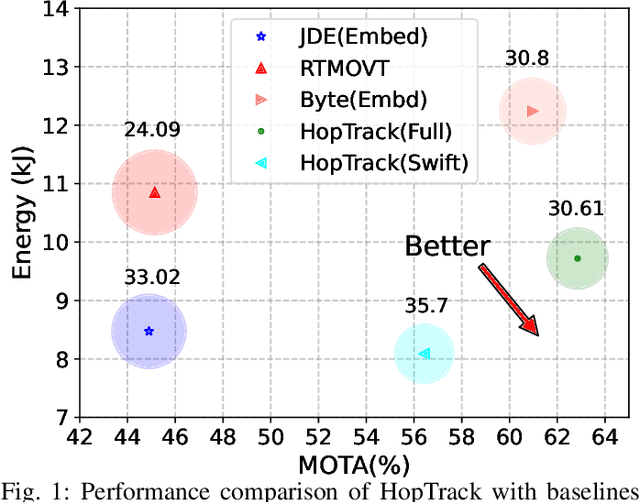
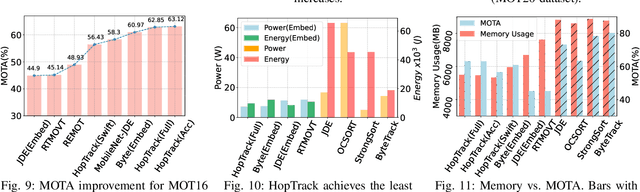
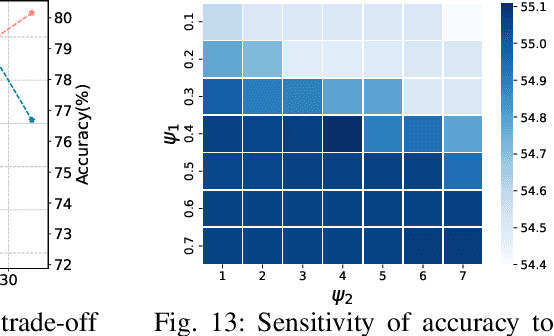
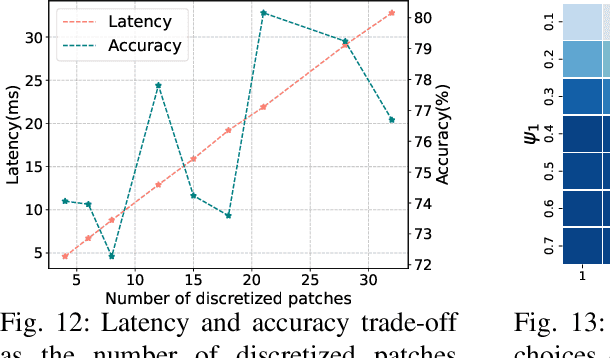
Multi-Object Tracking (MOT) poses significant challenges in computer vision. Despite its wide application in robotics, autonomous driving, and smart manufacturing, there is limited literature addressing the specific challenges of running MOT on embedded devices. State-of-the-art MOT trackers designed for high-end GPUs often experience low processing rates (<11fps) when deployed on embedded devices. Existing MOT frameworks for embedded devices proposed strategies such as fusing the detector model with the feature embedding model to reduce inference latency or combining different trackers to improve tracking accuracy, but tend to compromise one for the other. This paper introduces HopTrack, a real-time multi-object tracking system tailored for embedded devices. Our system employs a novel discretized static and dynamic matching approach along with an innovative content-aware dynamic sampling technique to enhance tracking accuracy while meeting the real-time requirement. Compared with the best high-end GPU modified baseline Byte (Embed) and the best existing baseline on embedded devices MobileNet-JDE, HopTrack achieves a processing speed of up to 39.29 fps on NVIDIA AGX Xavier with a multi-object tracking accuracy (MOTA) of up to 63.12% on the MOT16 benchmark, outperforming both counterparts by 2.15% and 4.82%, respectively. Additionally, the accuracy improvement is coupled with the reduction in energy consumption (20.8%), power (5%), and memory usage (8%), which are crucial resources on embedded devices. HopTrack is also detector agnostic allowing the flexibility of plug-and-play.
A Comprehensive Comparative Study of Individual ML Models and Ensemble Strategies for Network Intrusion Detection Systems
Oct 21, 2024The escalating frequency of intrusions in networked systems has spurred the exploration of new research avenues in devising artificial intelligence (AI) techniques for intrusion detection systems (IDS). Various AI techniques have been used to automate network intrusion detection tasks, yet each model possesses distinct strengths and weaknesses. Selecting the optimal model for a given dataset can pose a challenge, necessitating the exploration of ensemble methods to enhance generalization and applicability in network intrusion detection. This paper addresses this gap by conducting a comprehensive evaluation of diverse individual models and both simple and advanced ensemble methods for network IDS. We introduce an ensemble learning framework tailored for assessing individual models and ensemble methods in network intrusion detection tasks. Our framework encompasses the loading of input datasets, training of individual models and ensemble methods, and the generation of evaluation metrics. Furthermore, we incorporate all features across individual models and ensemble techniques. The study presents results for our framework, encompassing 14 methods, including various bagging, stacking, blending, and boosting techniques applied to multiple base learners such as decision trees, neural networks, and among others. We evaluate the framework using two distinct network intrusion datasets, RoEduNet-SIMARGL2021 and CICIDS-2017, each possessing unique characteristics. Additionally, we categorize AI models based on their performances on our evaluation metrics and via their confusion matrices. Our assessment demonstrates the efficacy of learning across most setups explored in this study. Furthermore, we contribute to the community by releasing our source codes, providing a foundational ensemble learning framework for network intrusion detection.
XAI-based Feature Ensemble for Enhanced Anomaly Detection in Autonomous Driving Systems
Oct 20, 2024



The rapid advancement of autonomous vehicle (AV) technology has introduced significant challenges in ensuring transportation security and reliability. Traditional AI models for anomaly detection in AVs are often opaque, posing difficulties in understanding and trusting their decision making processes. This paper proposes a novel feature ensemble framework that integrates multiple Explainable AI (XAI) methods: SHAP, LIME, and DALEX with various AI models to enhance both anomaly detection and interpretability. By fusing top features identified by these XAI methods across six diverse AI models (Decision Trees, Random Forests, Deep Neural Networks, K Nearest Neighbors, Support Vector Machines, and AdaBoost), the framework creates a robust and comprehensive set of features critical for detecting anomalies. These feature sets, produced by our feature ensemble framework, are evaluated using independent classifiers (CatBoost, Logistic Regression, and LightGBM) to ensure unbiased performance. We evaluated our feature ensemble approach on two popular autonomous driving datasets (VeReMi and Sensor) datasets. Our feature ensemble technique demonstrates improved accuracy, robustness, and transparency of AI models, contributing to safer and more trustworthy autonomous driving systems.
XAI-based Feature Selection for Improved Network Intrusion Detection Systems
Oct 14, 2024



Explainability and evaluation of AI models are crucial parts of the security of modern intrusion detection systems (IDS) in the network security field, yet they are lacking. Accordingly, feature selection is essential for such parts in IDS because it identifies the most paramount features, enhancing attack detection and its description. In this work, we tackle the feature selection problem for IDS by suggesting new ways of applying eXplainable AI (XAI) methods for this problem. We identify the crucial attributes originated by distinct AI methods in tandem with the novel five attribute selection methods. We then compare many state-of-the-art feature selection strategies with our XAI-based feature selection methods, showing that most AI models perform better when using the XAI-based approach proposed in this work. By providing novel feature selection techniques and establishing the foundation for several XAI-based strategies, this research aids security analysts in the AI decision-making reasoning of IDS by providing them with a better grasp of critical intrusion traits. Furthermore, we make the source codes available so that the community may develop additional models on top of our foundational XAI-based feature selection framework.
Anomaly Detection and Inter-Sensor Transfer Learning on Smart Manufacturing Datasets
Jun 13, 2022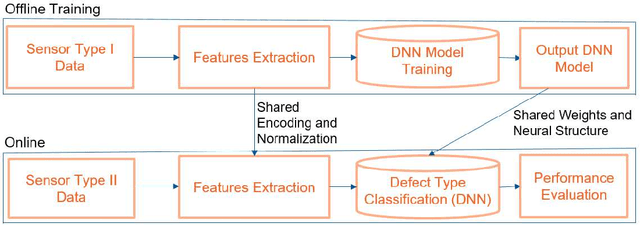



Smart manufacturing systems are being deployed at a growing rate because of their ability to interpret a wide variety of sensed information and act on the knowledge gleaned from system observations. In many cases, the principal goal of the smart manufacturing system is to rapidly detect (or anticipate) failures to reduce operational cost and eliminate downtime. This often boils down to detecting anomalies within the sensor date acquired from the system. The smart manufacturing application domain poses certain salient technical challenges. In particular, there are often multiple types of sensors with varying capabilities and costs. The sensor data characteristics change with the operating point of the environment or machines, such as, the RPM of the motor. The anomaly detection process therefore has to be calibrated near an operating point. In this paper, we analyze four datasets from sensors deployed from manufacturing testbeds. We evaluate the performance of several traditional and ML-based forecasting models for predicting the time series of sensor data. Then, considering the sparse data from one kind of sensor, we perform transfer learning from a high data rate sensor to perform defect type classification. Taken together, we show that predictive failure classification can be achieved, thus paving the way for predictive maintenance.
Anomaly Detection through Transfer Learning in Agriculture and Manufacturing IoT Systems
Feb 11, 2021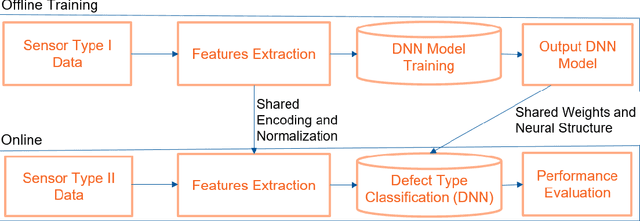
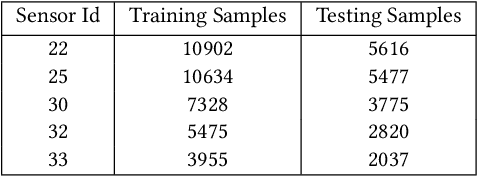
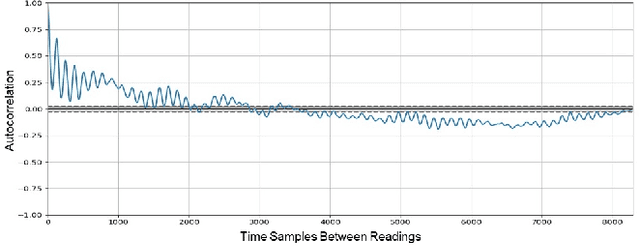
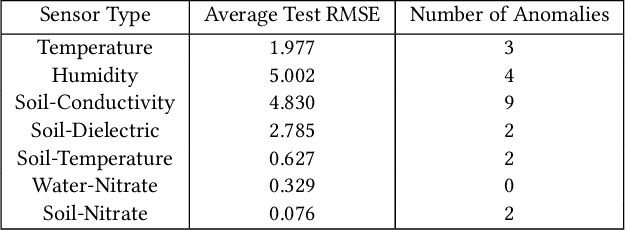
IoT systems have been facing increasingly sophisticated technical problems due to the growing complexity of these systems and their fast deployment practices. Consequently, IoT managers have to judiciously detect failures (anomalies) in order to reduce their cyber risk and operational cost. While there is a rich literature on anomaly detection in many IoT-based systems, there is no existing work that documents the use of ML models for anomaly detection in digital agriculture and in smart manufacturing systems. These two application domains pose certain salient technical challenges. In agriculture the data is often sparse, due to the vast areas of farms and the requirement to keep the cost of monitoring low. Second, in both domains, there are multiple types of sensors with varying capabilities and costs. The sensor data characteristics change with the operating point of the environment or machines, such as, the RPM of the motor. The inferencing and the anomaly detection processes therefore have to be calibrated for the operating point. In this paper, we analyze data from sensors deployed in an agricultural farm with data from seven different kinds of sensors, and from an advanced manufacturing testbed with vibration sensors. We evaluate the performance of ARIMA and LSTM models for predicting the time series of sensor data. Then, considering the sparse data from one kind of sensor, we perform transfer learning from a high data rate sensor. We then perform anomaly detection using the predicted sensor data. Taken together, we show how in these two application domains, predictive failure classification can be achieved, thus paving the way for predictive maintenance.
Morshed: Guiding Behavioral Decision-Makers towards Better Security Investment in Interdependent Systems
Nov 22, 2020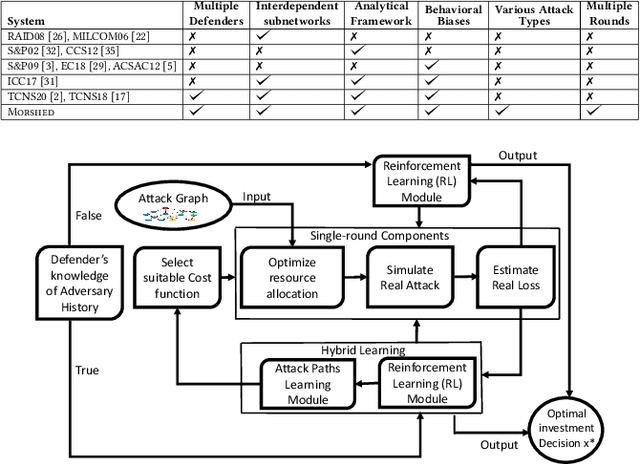
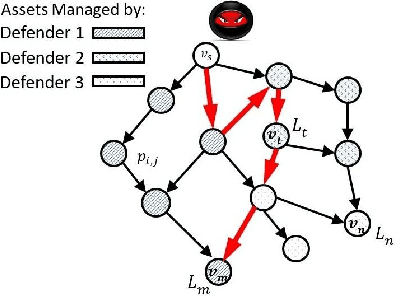

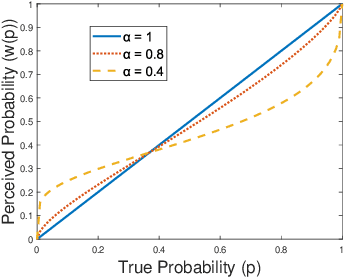
We model the behavioral biases of human decision-making in securing interdependent systems and show that such behavioral decision-making leads to a suboptimal pattern of resource allocation compared to non-behavioral (rational) decision-making. We provide empirical evidence for the existence of such behavioral bias model through a controlled subject study with 145 participants. We then propose three learning techniques for enhancing decision-making in multi-round setups. We illustrate the benefits of our decision-making model through multiple interdependent real-world systems and quantify the level of gain compared to the case in which the defenders are behavioral. We also show the benefit of our learning techniques against different attack models. We identify the effects of different system parameters on the degree of suboptimality of security outcomes due to behavioral decision-making.
ATHENA: Automated Tuning of Genomic Error Correction Algorithms using Language Models
Dec 30, 2018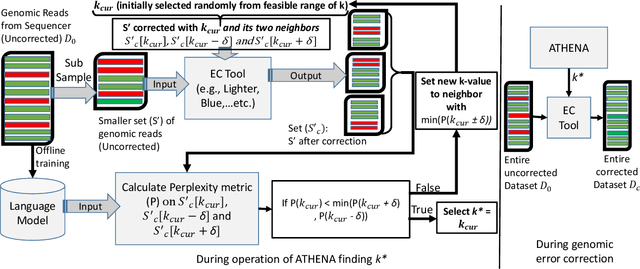


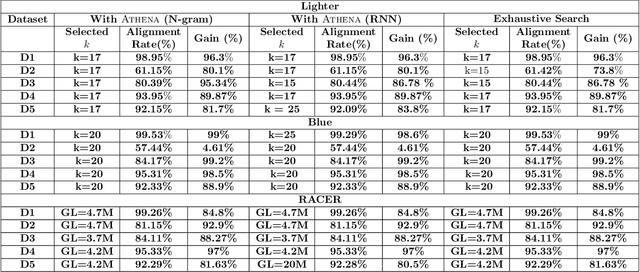
The performance of most error-correction algorithms that operate on genomic sequencer reads is dependent on the proper choice of its configuration parameters, such as the value of k in k-mer based techniques. In this work, we target the problem of finding the best values of these configuration parameters to optimize error correction. We perform this in a data-driven manner, due to the observation that different configuration parameters are optimal for different datasets, i.e., from different instruments and organisms. We use language modeling techniques from the Natural Language Processing (NLP) domain in our algorithmic suite, Athena, to automatically tune the performance-sensitive configuration parameters. Through the use of N-Gram and Recurrent Neural Network (RNN) language modeling, we validate the intuition that the EC performance can be computed quantitatively and efficiently using the perplexity metric, prevalent in NLP. After training the language model, we show that the perplexity metric calculated for runtime data has a strong negative correlation with the correction of the erroneous NGS reads. Therefore, we use the perplexity metric to guide a hill climbing-based search, converging toward the best $k$-value. Our approach is suitable for both de novo and comparative sequencing (resequencing), eliminating the need for a reference genome to serve as the ground truth. This is important because the use of a reference genome often carries forward the biases along the stages of the pipeline.