 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation for Unsupervised Combinatorial Optimization
Jan 28, 2026Unsupervised neural combinatorial optimization (NCO) enables learning powerful solvers without access to ground-truth solutions. Existing approaches fall into two disjoint paradigms: models trained for generalization across instances, and instance-specific models optimized independently at test time. While the former are efficient during inference, they lack effective instance-wise adaptability; the latter are flexible but fail to exploit learned inductive structure and are prone to poor local optima. This motivates the central question of our work: how can we leverage the inductive bias learned through generalization while unlocking the flexibility required for effective instance-wise adaptation? We first identify a challenge in bridging these two paradigms: generalization-focused models often constitute poor warm starts for instance-wise optimization, potentially underperforming even randomly initialized models when fine-tuned at test time. To resolve this incompatibility, we propose TACO, a model-agnostic test-time adaptation framework that unifies and extends the two existing paradigms for unsupervised NCO. TACO applies strategic warm-starting to partially relax trained parameters while preserving inductive bias, enabling rapid and effective unsupervised adaptation. Crucially, compared to naively fine-tuning a trained generalizable model or optimizing an instance-specific model from scratch, TACO achieves better solution quality while incurring negligible additional computational cost. Experiments on canonical CO problems, Minimum Vertex Cover and Maximum Clique, demonstrate the effectiveness and robustness of TACO across static, distribution-shifted, and dynamic combinatorial optimization problems, establishing it as a practical bridge between generalizable and instance-specific unsupervised NCO.
Learning for Dynamic Combinatorial Optimization without Training Data
May 26, 2025We introduce DyCO-GNN, a novel unsupervised learning framework for Dynamic Combinatorial Optimization that requires no training data beyond the problem instance itself. DyCO-GNN leverages structural similarities across time-evolving graph snapshots to accelerate optimization while maintaining solution quality. We evaluate DyCO-GNN on dynamic maximum cut, maximum independent set, and the traveling salesman problem across diverse datasets of varying sizes, demonstrating its superior performance under tight and moderate time budgets. DyCO-GNN consistently outperforms the baseline methods, achieving high-quality solutions up to 3-60x faster, highlighting its practical effectiveness in rapidly evolving resource-constrained settings.
Anticipating Gaming to Incentivize Improvement: Guiding Agents in (Fair) Strategic Classification
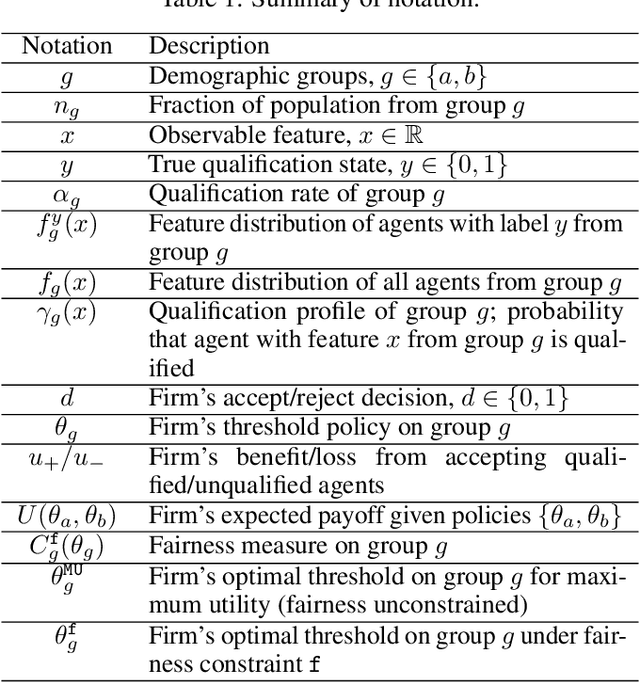
May 08, 2025As machine learning algorithms increasingly influence critical decision making in different application areas, understanding human strategic behavior in response to these systems becomes vital. We explore individuals' choice between genuinely improving their qualifications (``improvement'') vs. attempting to deceive the algorithm by manipulating their features (``manipulation'') in response to an algorithmic decision system. We further investigate an algorithm designer's ability to shape these strategic responses, and its fairness implications. Specifically, we formulate these interactions as a Stackelberg game, where a firm deploys a (fair) classifier, and individuals strategically respond. Our model incorporates both different costs and stochastic efficacy for manipulation and improvement. The analysis reveals different potential classes of agent responses, and characterizes optimal classifiers accordingly. Based on these, we highlight the impact of the firm's anticipation of strategic behavior, identifying when and why a (fair) strategic policy can not only prevent manipulation, but also incentivize agents to opt for improvement.
Adaptive Bounded Exploration and Intermediate Actions for Data Debiasing
Apr 10, 2025The performance of algorithmic decision rules is largely dependent on the quality of training datasets available to them. Biases in these datasets can raise economic and ethical concerns due to the resulting algorithms' disparate treatment of different groups. In this paper, we propose algorithms for sequentially debiasing the training dataset through adaptive and bounded exploration in a classification problem with costly and censored feedback. Our proposed algorithms balance between the ultimate goal of mitigating the impacts of data biases -- which will in turn lead to more accurate and fairer decisions, and the exploration risks incurred to achieve this goal. Specifically, we propose adaptive bounds to limit the region of exploration, and leverage intermediate actions which provide noisy label information at a lower cost. We analytically show that such exploration can help debias data in certain distributions, investigate how {algorithmic fairness interventions} can work in conjunction with our proposed algorithms, and validate the performance of these algorithms through numerical experiments on synthetic and real-world data.
The Double-Edged Sword of Behavioral Responses in Strategic Classification: Theory and User Studies
Oct 23, 2024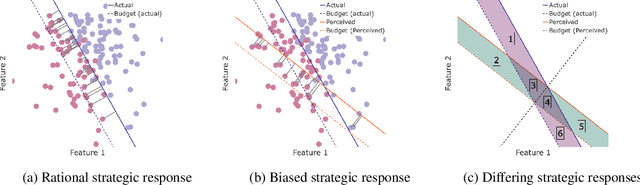

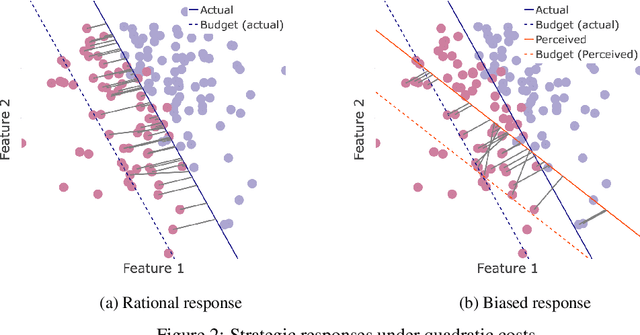

When humans are subject to an algorithmic decision system, they can strategically adjust their behavior accordingly (``game'' the system). While a growing line of literature on strategic classification has used game-theoretic modeling to understand and mitigate such gaming, these existing works consider standard models of fully rational agents. In this paper, we propose a strategic classification model that considers behavioral biases in human responses to algorithms. We show how misperceptions of a classifier (specifically, of its feature weights) can lead to different types of discrepancies between biased and rational agents' responses, and identify when behavioral agents over- or under-invest in different features. We also show that strategic agents with behavioral biases can benefit or (perhaps, unexpectedly) harm the firm compared to fully rational strategic agents. We complement our analytical results with user studies, which support our hypothesis of behavioral biases in human responses to the algorithm. Together, our findings highlight the need to account for human (cognitive) biases when designing AI systems, and providing explanations of them, to strategic human in the loop.
Enhancing Group Fairness in Federated Learning through Personalization
Jul 27, 2024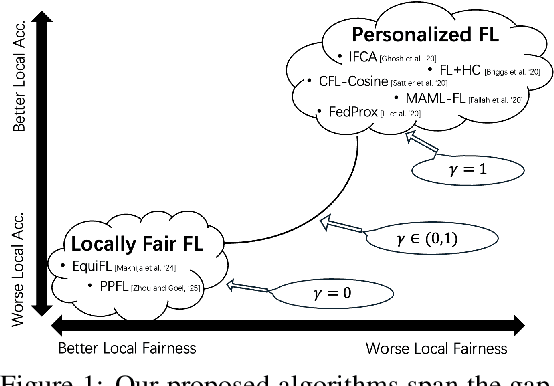
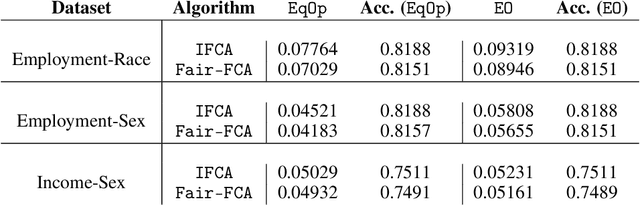
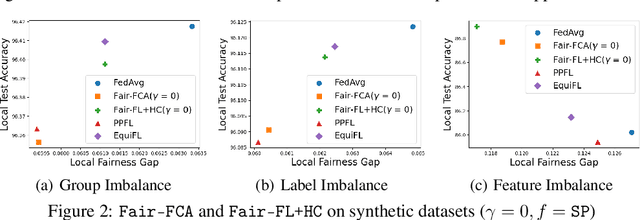
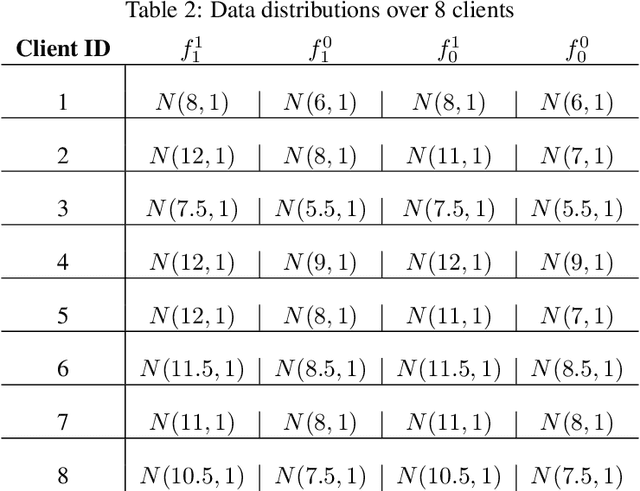
Personalized Federated Learning (FL) algorithms collaboratively train customized models for each client, enhancing the accuracy of the learned models on the client's local data (e.g., by clustering similar clients, or by fine-tuning models locally). In this paper, we investigate the impact of such personalization techniques on the group fairness of the learned models, and show that personalization can also lead to improved (local) fairness as an unintended benefit. We begin by illustrating these benefits of personalization through numerical experiments comparing two classes of personalized FL algorithms (clustering and fine-tuning) against a baseline FedAvg algorithm, elaborating on the reasons behind improved fairness using personalized FL, and then providing analytical support. Motivated by these, we further propose a new, Fairness-aware Federated Clustering Algorithm, Fair-FCA, in which clients can be clustered to obtain a (tuneable) fairness-accuracy tradeoff. Through numerical experiments, we demonstrate the ability of Fair-FCA to strike a balance between accuracy and fairness at the client level.
Generalization Error Bounds for Learning under Censored Feedback
Apr 14, 2024Generalization error bounds from learning theory provide statistical guarantees on how well an algorithm will perform on previously unseen data. In this paper, we characterize the impacts of data non-IIDness due to censored feedback (a.k.a. selective labeling bias) on such bounds. We first derive an extension of the well-known Dvoretzky-Kiefer-Wolfowitz (DKW) inequality, which characterizes the gap between empirical and theoretical CDFs given IID data, to problems with non-IID data due to censored feedback. We then use this CDF error bound to provide a bound on the generalization error guarantees of a classifier trained on such non-IID data. We show that existing generalization error bounds (which do not account for censored feedback) fail to correctly capture the model's generalization guarantees, verifying the need for our bounds. We further analyze the effectiveness of (pure and bounded) exploration techniques, proposed by recent literature as a way to alleviate censored feedback, on improving our error bounds. Together, our findings illustrate how a decision maker should account for the trade-off between strengthening the generalization guarantees of an algorithm and the costs incurred in data collection when future data availability is limited by censored feedback.
An advantage based policy transfer algorithm for reinforcement learning with metrics of transferability
Nov 12, 2023



Reinforcement learning (RL) can enable sequential decision-making in complex and high-dimensional environments if the acquisition of a new state-action pair is efficient, i.e., when interaction with the environment is inexpensive. However, there are a myriad of real-world applications in which a high number of interactions are infeasible. In these environments, transfer RL algorithms, which can be used for the transfer of knowledge from one or multiple source environments to a target environment, have been shown to increase learning speed and improve initial and asymptotic performance. However, most existing transfer RL algorithms are on-policy and sample inefficient, and often require heuristic choices in algorithm design. This paper proposes an off-policy Advantage-based Policy Transfer algorithm, APT-RL, for fixed domain environments. Its novelty is in using the popular notion of ``advantage'' as a regularizer, to weigh the knowledge that should be transferred from the source, relative to new knowledge learned in the target, removing the need for heuristic choices. Further, we propose a new transfer performance metric to evaluate the performance of our algorithm and unify existing transfer RL frameworks. Finally, we present a scalable, theoretically-backed task similarity measurement algorithm to illustrate the alignments between our proposed transferability metric and similarities between source and target environments. Numerical experiments on three continuous control benchmark tasks demonstrate that APT-RL outperforms existing transfer RL algorithms on most tasks, and is $10\%$ to $75\%$ more sample efficient than learning from scratch.
Social Bias Meets Data Bias: The Impacts of Labeling and Measurement Errors on Fairness Criteria
May 31, 2022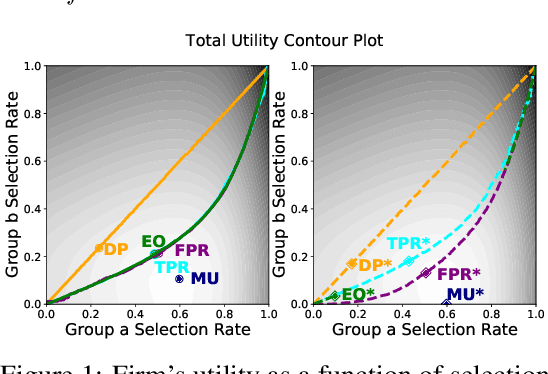
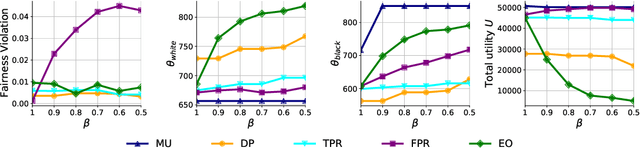
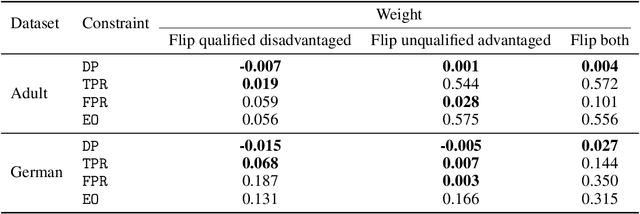
Although many fairness criteria have been proposed to ensure that machine learning algorithms do not exhibit or amplify our existing social biases, these algorithms are trained on datasets that can themselves be statistically biased. In this paper, we investigate the robustness of a number of existing (demographic) fairness criteria when the algorithm is trained on biased data. We consider two forms of dataset bias: errors by prior decision makers in the labeling process, and errors in measurement of the features of disadvantaged individuals. We analytically show that some constraints (such as Demographic Parity) can remain robust when facing certain statistical biases, while others (such as Equalized Odds) are significantly violated if trained on biased data. We also analyze the sensitivity of these criteria and the decision maker's utility to biases. We provide numerical experiments based on three real-world datasets (the FICO, Adult, and German credit score datasets) supporting our analytical findings. Our findings present an additional guideline for choosing among existing fairness criteria, or for proposing new criteria, when available datasets may be biased.
Adaptive Data Debiasing through Bounded Exploration and Fairness
Oct 25, 2021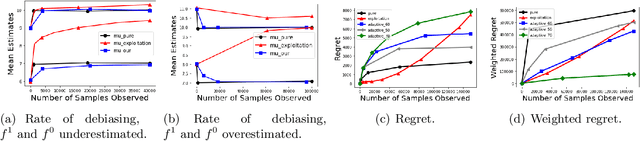
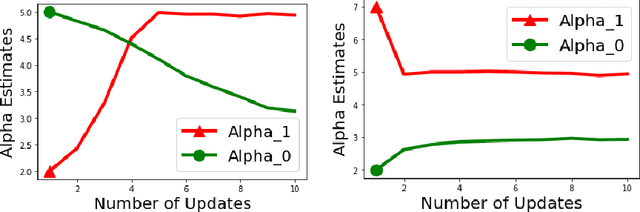
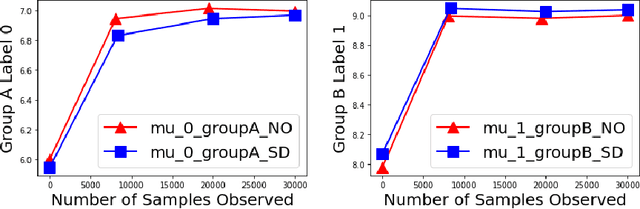
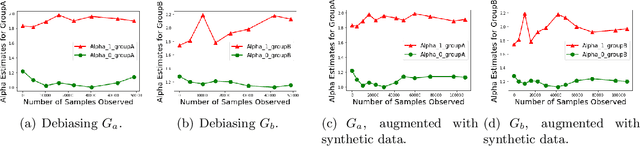
Biases in existing datasets used to train algorithmic decision rules can raise ethical, societal, and economic concerns due to the resulting disparate treatment of different groups. We propose an algorithm for sequentially debiasing such datasets through adaptive and bounded exploration. Exploration in this context means that at times, and to a judiciously-chosen extent, the decision maker deviates from its (current) loss-minimizing rule, and instead accepts some individuals that would otherwise be rejected, so as to reduce statistical data biases. Our proposed algorithm includes parameters that can be used to balance between the ultimate goal of removing data biases -- which will in turn lead to more accurate and fair decisions, and the exploration risks incurred to achieve this goal. We show, both analytically and numerically, how such exploration can help debias data in certain distributions. We further investigate how fairness measures can work in conjunction with such data debiasing efforts.