 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Bias Meets Data Bias: The Impacts of Labeling and Measurement Errors on Fairness Criteria
Paper and Code
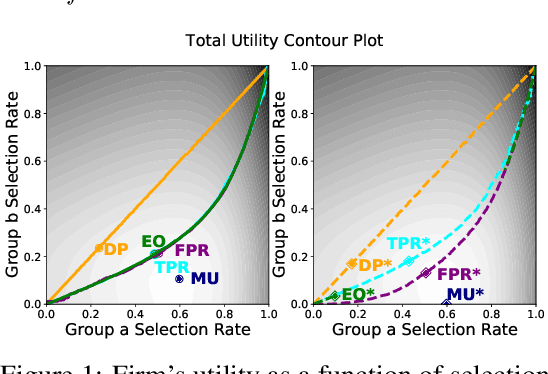
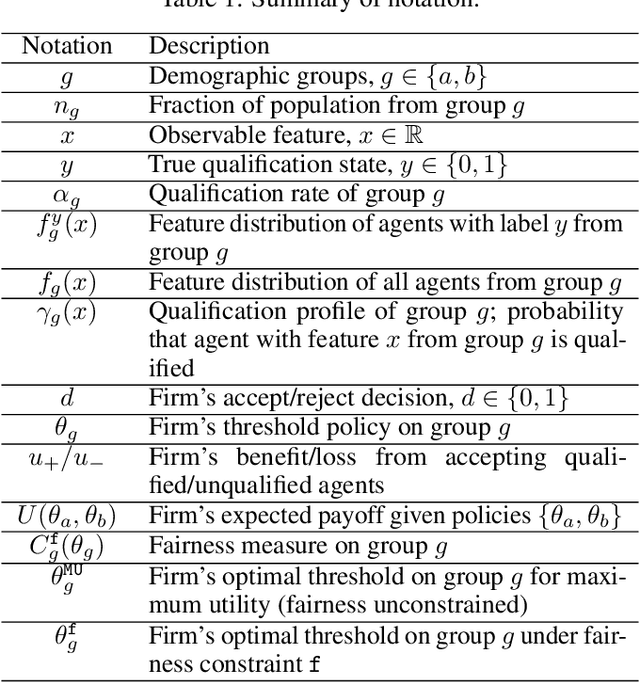
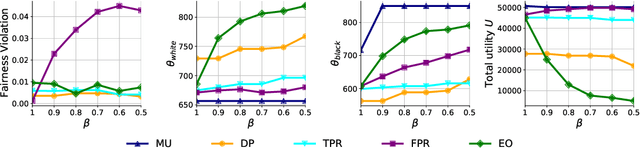
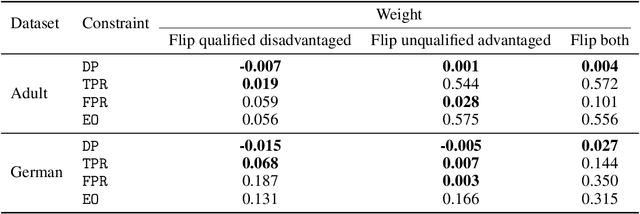
Although many fairness criteria have been proposed to ensure that machine learning algorithms do not exhibit or amplify our existing social biases, these algorithms are trained on datasets that can themselves be statistically biased. In this paper, we investigate the robustness of a number of existing (demographic) fairness criteria when the algorithm is trained on biased data. We consider two forms of dataset bias: errors by prior decision makers in the labeling process, and errors in measurement of the features of disadvantaged individuals. We analytically show that some constraints (such as Demographic Parity) can remain robust when facing certain statistical biases, while others (such as Equalized Odds) are significantly violated if trained on biased data. We also analyze the sensitivity of these criteria and the decision maker's utility to biases. We provide numerical experiments based on three real-world datasets (the FICO, Adult, and German credit score datasets) supporting our analytical findings. Our findings present an additional guideline for choosing among existing fairness criteria, or for proposing new criteria, when available datasets may be biased.