 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Data Debiasing through Bounded Exploration and Fairness
Paper and Code
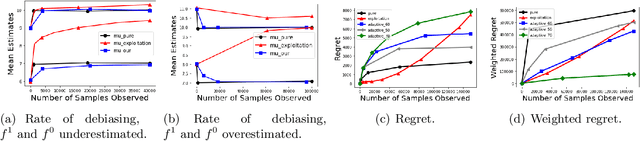
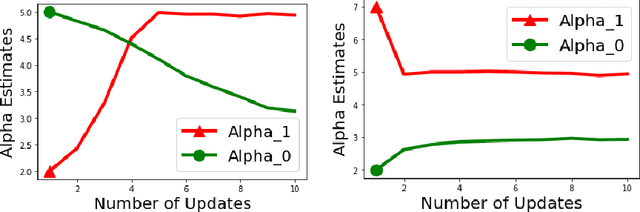
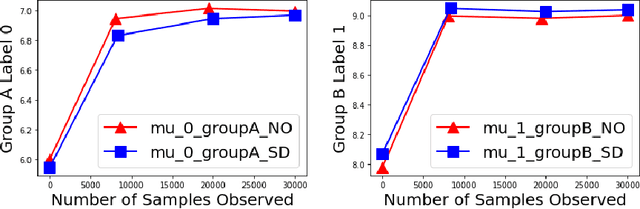
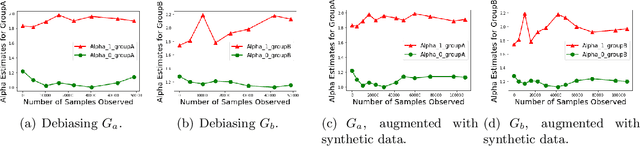
Biases in existing datasets used to train algorithmic decision rules can raise ethical, societal, and economic concerns due to the resulting disparate treatment of different groups. We propose an algorithm for sequentially debiasing such datasets through adaptive and bounded exploration. Exploration in this context means that at times, and to a judiciously-chosen extent, the decision maker deviates from its (current) loss-minimizing rule, and instead accepts some individuals that would otherwise be rejected, so as to reduce statistical data biases. Our proposed algorithm includes parameters that can be used to balance between the ultimate goal of removing data biases -- which will in turn lead to more accurate and fair decisions, and the exploration risks incurred to achieve this goal. We show, both analytically and numerically, how such exploration can help debias data in certain distributions. We further investigate how fairness measures can work in conjunction with such data debiasing efforts.