 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-limiting Financial Audits via Weighted Sampling without Replacement
May 08, 2023We introduce the notion of a risk-limiting financial auditing (RLFA): given $N$ transactions, the goal is to estimate the total misstated monetary fraction~($m^*$) to a given accuracy $\epsilon$, with confidence $1-\delta$. We do this by constructing new confidence sequences (CSs) for the weighted average of $N$ unknown values, based on samples drawn without replacement according to a (randomized) weighted sampling scheme. Using the idea of importance weighting to construct test martingales, we first develop a framework to construct CSs for arbitrary sampling strategies. Next, we develop methods to improve the quality of CSs by incorporating side information about the unknown values associated with each item. We show that when the side information is sufficiently predictive, it can directly drive the sampling. Addressing the case where the accuracy is unknown a priori, we introduce a method that incorporates side information via control variates. Crucially, our construction is adaptive: if the side information is highly predictive of the unknown misstated amounts, then the benefits of incorporating it are significant; but if the side information is uncorrelated, our methods learn to ignore it. Our methods recover state-of-the-art bounds for the special case when the weights are equal, which has already found applications in election auditing. The harder weighted case solves our more challenging problem of AI-assisted financial auditing.
Anomaly Detection in Large Labeled Multi-Graph Databases
Oct 07, 2020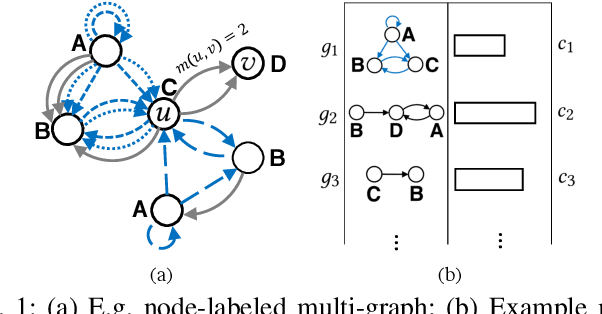

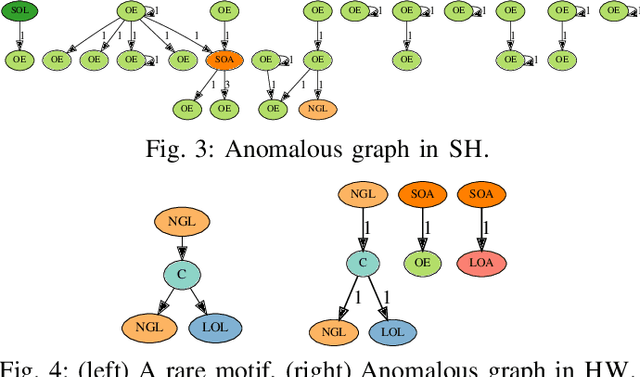

Within a large database G containing graphs with labeled nodes and directed, multi-edges; how can we detect the anomalous graphs? Most existing work are designed for plain (unlabeled) and/or simple (unweighted) graphs. We introduce CODETECT, the first approach that addresses the anomaly detection task for graph databases with such complex nature. To this end, it identifies a small representative set S of structural patterns (i.e., node-labeled network motifs) that losslessly compress database G as concisely as possible. Graphs that do not compress well are flagged as anomalous. CODETECT exhibits two novel building blocks: (i) a motif-based lossless graph encoding scheme, and (ii) fast memory-efficient search algorithms for S. We show the effectiveness of CODETECT on transaction graph databases from three different corporations, where existing baselines adjusted for the task fall behind significantly, across different types of anomalies and performance metrics.