 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Model Aggregation for Fast and Robust Federated Learning in Edge Computing
Paper and Code
Mar 23, 2022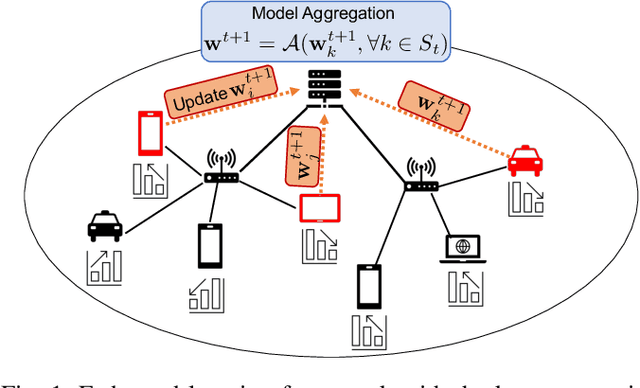
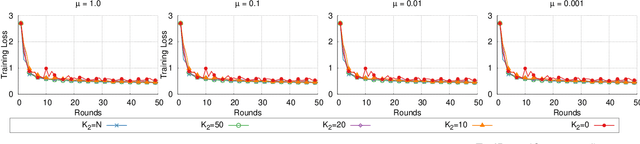
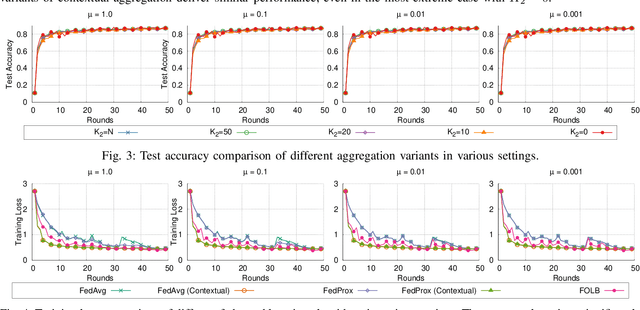
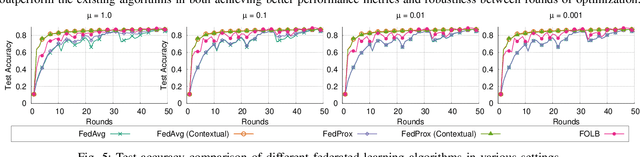
Federated learning is a prime candidate for distributed machine learning at the network edge due to the low communication complexity and privacy protection among other attractive properties. However, existing algorithms face issues with slow convergence and/or robustness of performance due to the considerable heterogeneity of data distribution, computation and communication capability at the edge. In this work, we tackle both of these issues by focusing on the key component of model aggregation in federated learning systems and studying optimal algorithms to perform this task. Particularly, we propose a contextual aggregation scheme that achieves the optimal context-dependent bound on loss reduction in each round of optimization. The aforementioned context-dependent bound is derived from the particular participating devices in that round and an assumption on smoothness of the overall loss function. We show that this aggregation leads to a definite reduction of loss function at every round. Furthermore, we can integrate our aggregation with many existing algorithms to obtain the contextual versions. Our experimental results demonstrate significant improvements in convergence speed and robustness of the contextual versions compared to the original algorithms. We also consider different variants of the contextual aggregation and show robust performance even in the most extreme settings.