 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ultimate Cookbook for Invisible Poison: Crafting Subtle Clean-Label Text Backdoors with Style Attributes
Apr 24, 2025Backdoor attacks on text classifiers can cause them to predict a predefined label when a particular "trigger" is present. Prior attacks often rely on triggers that are ungrammatical or otherwise unusual, leading to conspicuous attacks. As a result, human annotators, who play a critical role in curating training data in practice, can easily detect and filter out these unnatural texts during manual inspection, reducing the risk of such attacks. We argue that a key criterion for a successful attack is for text with and without triggers to be indistinguishable to humans. However, prior work neither directly nor comprehensively evaluated attack subtlety and invisibility with human involvement. We bridge the gap by conducting thorough human evaluations to assess attack subtlety. We also propose \emph{AttrBkd}, consisting of three recipes for crafting subtle yet effective trigger attributes, such as extracting fine-grained attributes from existing baseline backdoor attacks. Our human evaluations find that AttrBkd with these baseline-derived attributes is often more effective (higher attack success rate) and more subtle (fewer instances detected by humans) than the original baseline backdoor attacks, demonstrating that backdoor attacks can bypass detection by being inconspicuous and appearing natural even upon close inspection, while still remaining effective. Our human annotation also provides information not captured by automated metrics used in prior work, and demonstrates the misalignment of these metrics with human judgment.
MaPPing Your Model: Assessing the Impact of Adversarial Attacks on LLM-based Programming Assistants
Jul 12, 2024



LLM-based programming assistants offer the promise of programming faster but with the risk of introducing more security vulnerabilities. Prior work has studied how LLMs could be maliciously fine-tuned to suggest vulnerabilities more often. With the rise of agentic LLMs, which may use results from an untrusted third party, there is a growing risk of attacks on the model's prompt. We introduce the Malicious Programming Prompt (MaPP) attack, in which an attacker adds a small amount of text to a prompt for a programming task (under 500 bytes). We show that our prompt strategy can cause an LLM to add vulnerabilities while continuing to write otherwise correct code. We evaluate three prompts on seven common LLMs, from basic to state-of-the-art commercial models. Using the HumanEval benchmark, we find that our prompts are broadly effective, with no customization required for different LLMs. Furthermore, the LLMs that are best at HumanEval are also best at following our malicious instructions, suggesting that simply scaling language models will not prevent MaPP attacks. Using a dataset of eight CWEs in 16 scenarios, we find that MaPP attacks are also effective at implementing specific and targeted vulnerabilities across a range of models. Our work highlights the need to secure LLM prompts against manipulation as well as rigorously auditing code generated with the help of LLMs.
Large Language Models Are Better Adversaries: Exploring Generative Clean-Label Backdoor Attacks Against Text Classifiers
Oct 28, 2023Backdoor attacks manipulate model predictions by inserting innocuous triggers into training and test data. We focus on more realistic and more challenging clean-label attacks where the adversarial training examples are correctly labeled. Our attack, LLMBkd, leverages language models to automatically insert diverse style-based triggers into texts. We also propose a poison selection technique to improve the effectiveness of both LLMBkd as well as existing textual backdoor attacks. Lastly, we describe REACT, a baseline defense to mitigate backdoor attacks via antidote training examples. Our evaluations demonstrate LLMBkd's effectiveness and efficiency, where we consistently achieve high attack success rates across a wide range of styles with little effort and no model training.
Feature Partition Aggregation: A Fast Certified Defense Against a Union of Sparse Adversarial Attacks
Feb 22, 2023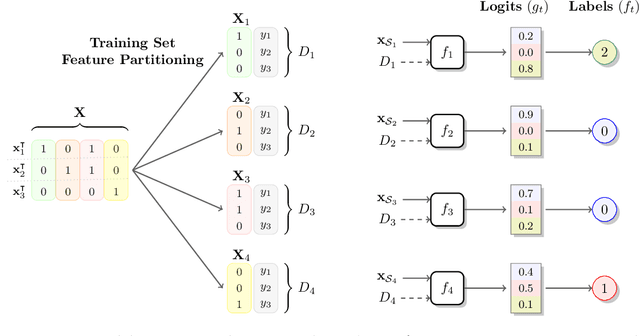

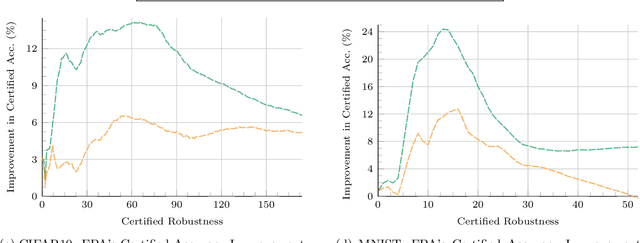
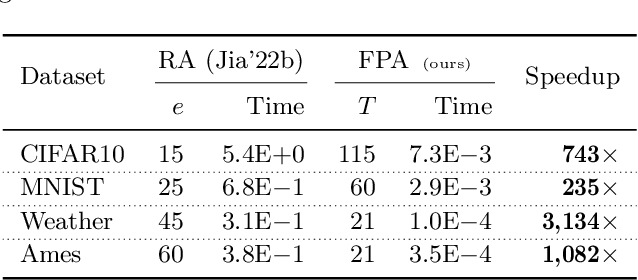
Deep networks are susceptible to numerous types of adversarial attacks. Certified defenses provide guarantees on a model's robustness, but most of these defenses are restricted to a single attack type. In contrast, this paper proposes feature partition aggregation (FPA) - a certified defense against a union of attack types, namely evasion, backdoor, and poisoning attacks. We specifically consider an $\ell_0$ or sparse attacker that arbitrarily controls an unknown subset of the training and test features - even across all instances. FPA generates robustness guarantees via an ensemble whose submodels are trained on disjoint feature sets. Following existing certified sparse defenses, we generalize FPA's guarantees to top-$k$ predictions. FPA significantly outperforms state-of-the-art sparse defenses providing larger and stronger robustness guarantees, while simultaneously being up to 5,000${\times}$ faster.
Training Data Influence Analysis and Estimation: A Survey
Dec 09, 2022Good models require good training data. For overparameterized deep models, the causal relationship between training data and model predictions is increasingly opaque and poorly understood. Influence analysis partially demystifies training's underlying interactions by quantifying the amount each training instance alters the final model. Measuring the training data's influence exactly can be provably hard in the worst case; this has led to the development and use of influence estimators, which only approximate the true influence. This paper provides the first comprehensive survey of training data influence analysis and estimation. We begin by formalizing the various, and in places orthogonal, definitions of training data influence. We then organize state-of-the-art influence analysis methods into a taxonomy; we describe each of these methods in detail and compare their underlying assumptions, asymptotic complexities, and overall strengths and weaknesses. Finally, we propose future research directions to make influence analysis more useful in practice as well as more theoretically and empirically sound. A curated, up-to-date list of resources related to influence analysis is available at https://github.com/ZaydH/influence_analysis_papers.
Reducing Certified Regression to Certified Classification
Aug 29, 2022
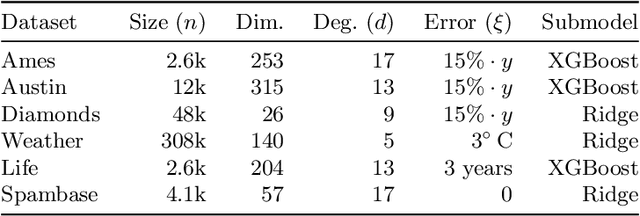

Adversarial training instances can severely distort a model's behavior. This work investigates certified regression defenses, which provide guaranteed limits on how much a regressor's prediction may change under a training-set attack. Our key insight is that certified regression reduces to certified classification when using median as a model's primary decision function. Coupling our reduction with existing certified classifiers, we propose six new provably-robust regressors. To the extent of our knowledge, this is the first work that certifies the robustness of individual regression predictions without any assumptions about the data distribution and model architecture. We also show that existing state-of-the-art certified classifiers often make overly-pessimistic assumptions that can degrade their provable guarantees. We introduce a tighter analysis of model robustness, which in many cases results in significantly improved certified guarantees. Lastly, we empirically demonstrate our approaches' effectiveness on both regression and classification data, where the accuracy of up to 50% of test predictions can be guaranteed under 1% training-set corruption and up to 30% of predictions under 4% corruption. Our source code is available at https://github.com/ZaydH/certified-regression.
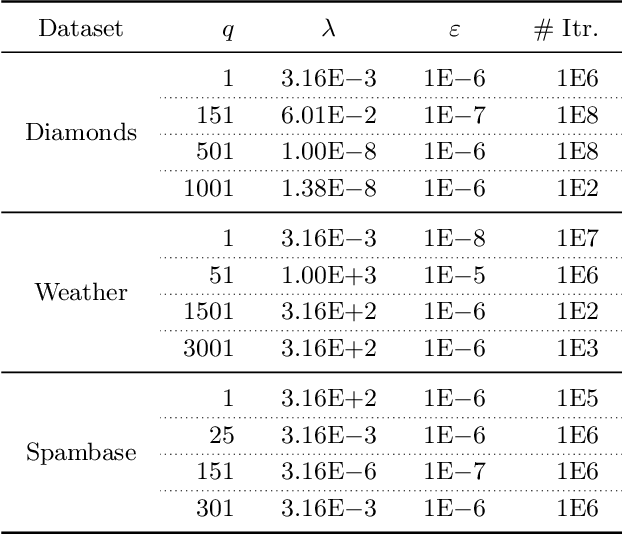
Instance-Based Uncertainty Estimation for Gradient-Boosted Regression Trees
May 23, 2022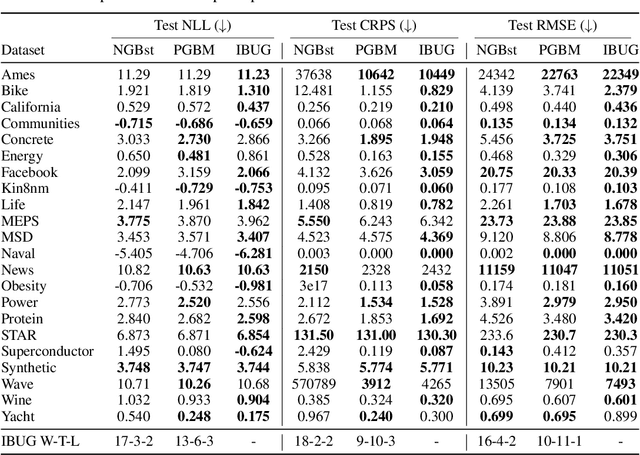

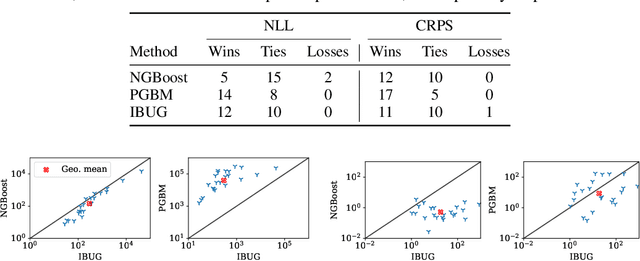

We propose Instance-Based Uncertainty estimation for Gradient-boosted regression trees~(IBUG), a simple method for extending any GBRT point predictor to produce probabilistic predictions. IBUG computes a non-parametric distribution around a prediction using the k-nearest training instances, where distance is measured with a tree-ensemble kernel. The runtime of IBUG depends on the number of training examples at each leaf in the ensemble, and can be improved by sampling trees or training instances. Empirically, we find that IBUG achieves similar or better performance than the previous state-of-the-art across 22 benchmark regression datasets. We also find that IBUG can achieve improved probabilistic performance by using different base GBRT models, and can more flexibly model the posterior distribution of a prediction than competing methods. We also find that previous methods suffer from poor probabilistic calibration on some datasets, which can be mitigated using a scalar factor tuned on the validation data.
Adapting and Evaluating Influence-Estimation Methods for Gradient-Boosted Decision Trees
Apr 30, 2022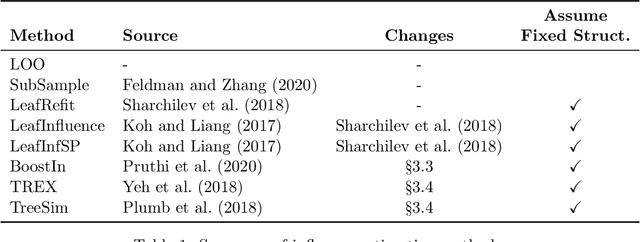

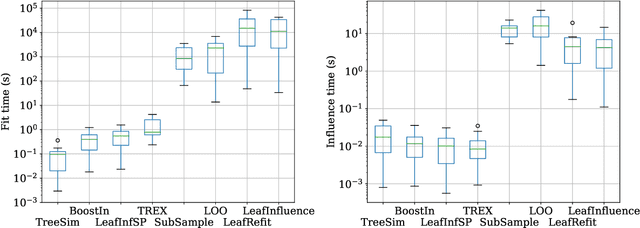
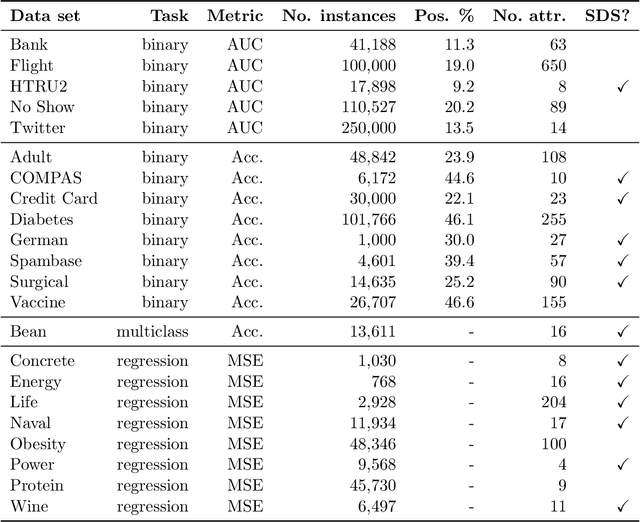
Influence estimation analyzes how changes to the training data can lead to different model predictions; this analysis can help us better understand these predictions, the models making those predictions, and the data sets they're trained on. However, most influence-estimation techniques are designed for deep learning models with continuous parameters. Gradient-boosted decision trees (GBDTs) are a powerful and widely-used class of models; however, these models are black boxes with opaque decision-making processes. In the pursuit of better understanding GBDT predictions and generally improving these models, we adapt recent and popular influence-estimation methods designed for deep learning models to GBDTs. Specifically, we adapt representer-point methods and TracIn, denoting our new methods TREX and BoostIn, respectively; source code is available at https://github.com/jjbrophy47/tree_influence. We compare these methods to LeafInfluence and other baselines using 5 different evaluation measures on 22 real-world data sets with 4 popular GBDT implementations. These experiments give us a comprehensive overview of how different approaches to influence estimation work in GBDT models. We find BoostIn is an efficient influence-estimation method for GBDTs that performs equally well or better than existing work while being four orders of magnitude faster. Our evaluation also suggests the gold-standard approach of leave-one-out~(LOO) retraining consistently identifies the single-most influential training example but performs poorly at finding the most influential set of training examples for a given target prediction.
Identifying a Training-Set Attack's Target Using Renormalized Influence Estimation
Jan 25, 2022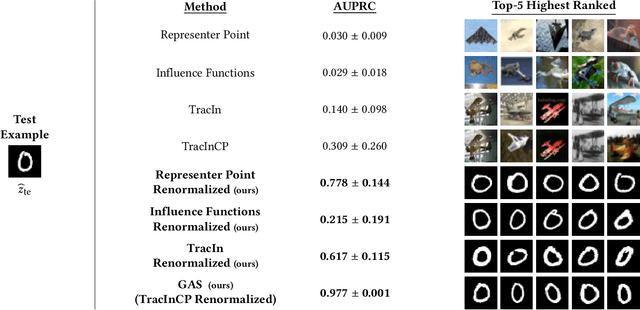
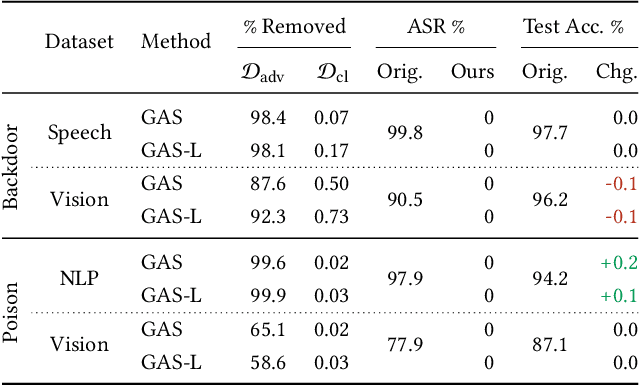
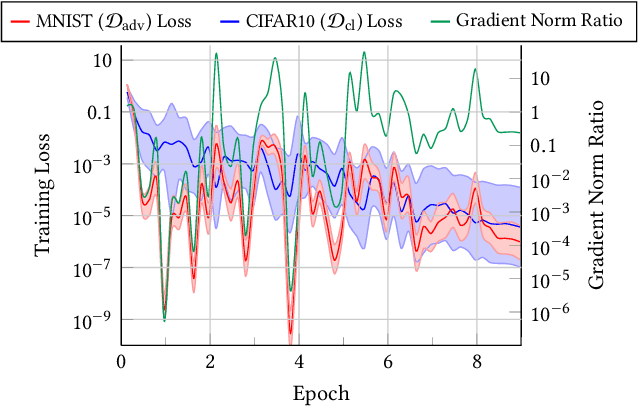

Targeted training-set attacks inject malicious instances into the training set to cause a trained model to mislabel one or more specific test instances. This work proposes the task of target identification, which determines whether a specific test instance is the target of a training-set attack. This can then be combined with adversarial-instance identification to find (and remove) the attack instances, mitigating the attack with minimal impact on other predictions. Rather than focusing on a single attack method or data modality, we build on influence estimation, which quantifies each training instance's contribution to a model's prediction. We show that existing influence estimators' poor practical performance often derives from their over-reliance on instances and iterations with large losses. Our renormalized influence estimators fix this weakness; they far outperform the original ones at identifying influential groups of training examples in both adversarial and non-adversarial settings, even finding up to 100% of adversarial training instances with no clean-data false positives. Target identification then simplifies to detecting test instances with anomalous influence values. We demonstrate our method's generality on backdoor and poisoning attacks across various data domains including text, vision, and speech. Our source code is available at https://github.com/ZaydH/target_identification .
Identifying Adversarial Attacks on Text Classifiers
Jan 21, 2022

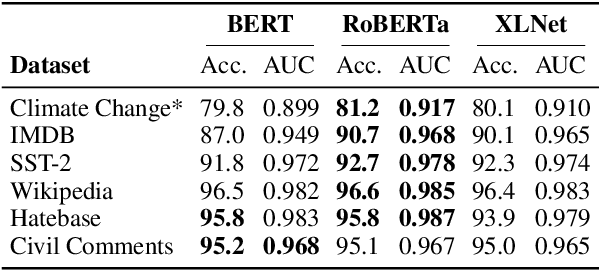
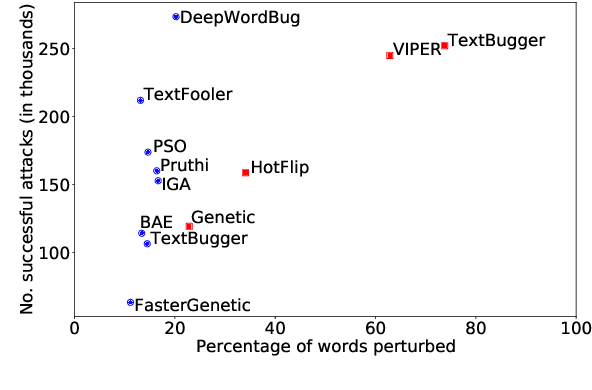
The landscape of adversarial attacks against text classifiers continues to grow, with new attacks developed every year and many of them available in standard toolkits, such as TextAttack and OpenAttack. In response, there is a growing body of work on robust learning, which reduces vulnerability to these attacks, though sometimes at a high cost in compute time or accuracy. In this paper, we take an alternate approach -- we attempt to understand the attacker by analyzing adversarial text to determine which methods were used to create it. Our first contribution is an extensive dataset for attack detection and labeling: 1.5~million attack instances, generated by twelve adversarial attacks targeting three classifiers trained on six source datasets for sentiment analysis and abuse detection in English. As our second contribution, we use this dataset to develop and benchmark a number of classifiers for attack identification -- determining if a given text has been adversarially manipulated and by which attack. As a third contribution, we demonstrate the effectiveness of three classes of features for these tasks: text properties, capturing content and presentation of text; language model properties, determining which tokens are more or less probable throughout the input; and target model properties, representing how the text classifier is influenced by the attack, including internal node activations. Overall, this represents a first step towards forensics for adversarial attacks against text classifiers.