 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Adversarial Attacks on Text Classifiers
Jan 21, 2022

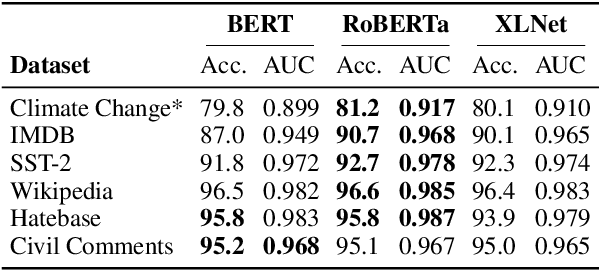
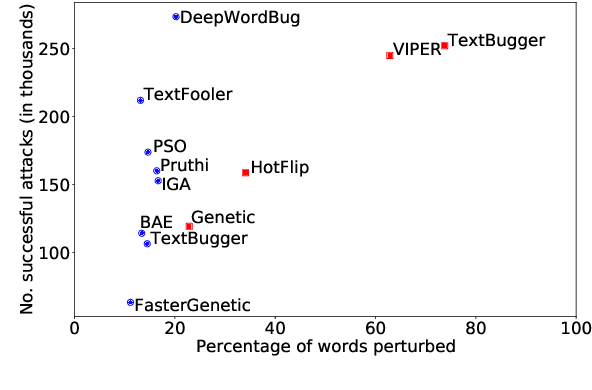
The landscape of adversarial attacks against text classifiers continues to grow, with new attacks developed every year and many of them available in standard toolkits, such as TextAttack and OpenAttack. In response, there is a growing body of work on robust learning, which reduces vulnerability to these attacks, though sometimes at a high cost in compute time or accuracy. In this paper, we take an alternate approach -- we attempt to understand the attacker by analyzing adversarial text to determine which methods were used to create it. Our first contribution is an extensive dataset for attack detection and labeling: 1.5~million attack instances, generated by twelve adversarial attacks targeting three classifiers trained on six source datasets for sentiment analysis and abuse detection in English. As our second contribution, we use this dataset to develop and benchmark a number of classifiers for attack identification -- determining if a given text has been adversarially manipulated and by which attack. As a third contribution, we demonstrate the effectiveness of three classes of features for these tasks: text properties, capturing content and presentation of text; language model properties, determining which tokens are more or less probable throughout the input; and target model properties, representing how the text classifier is influenced by the attack, including internal node activations. Overall, this represents a first step towards forensics for adversarial attacks against text classifiers.
Does Interpretability of Neural Networks Imply Adversarial Robustness?
Dec 07, 2019
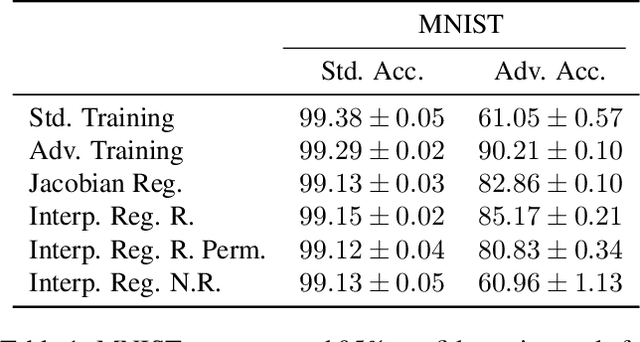
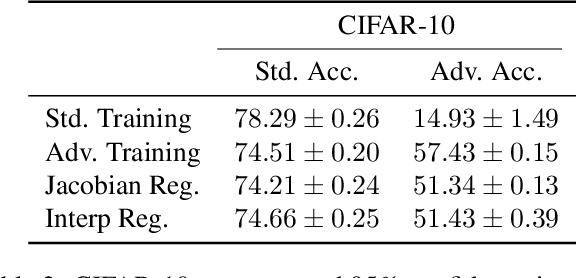

The success of deep neural networks is clouded by two issues that largely remain open to this day: the abundance of adversarial attacks that fool neural networks with small perturbations and the lack of interpretation for the predictions they make. Empirical evidence in the literature as well as theoretical analysis on simple models suggest these two seemingly disparate issues may actually be connected, as robust models tend to be more interpretable than non-robust models. In this paper, we provide evidence for the claim that this relationship is bidirectional. Viz., models that are forced to have interpretable gradients are more robust to adversarial examples than models trained in a standard manner. With further analysis and experiments, we identify two factors behind this phenomenon, namely the suppression of the gradient and the selective use of features guided by high-quality interpretations, which explain model behaviors under various regularization and target interpretation settings.
NormLime: A New Feature Importance Metric for Explaining Deep Neural Networks
Oct 15, 2019
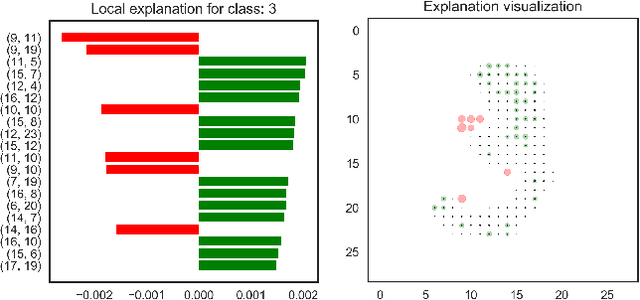
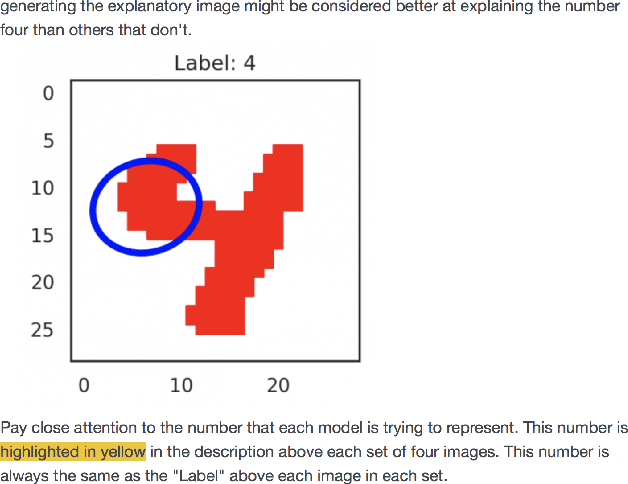
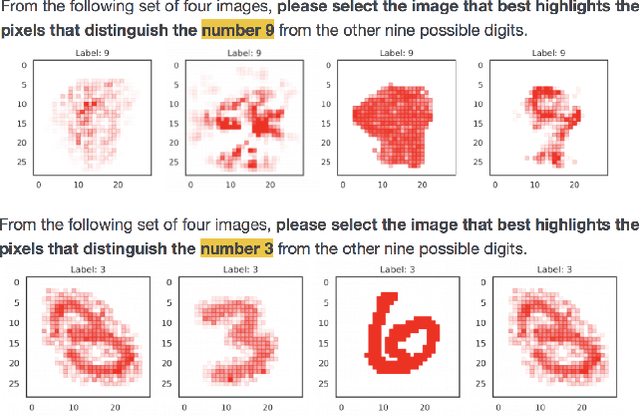
The problem of explaining deep learning models, and model predictions generally, has attracted intensive interest recently. Many successful approaches forgo global approximations in order to provide more faithful local interpretations of the model's behavior. LIME develops multiple interpretable models, each approximating a large neural network on a small region of the data manifold and SP-LIME aggregates the local models to form a global interpretation. Extending this line of research, we propose a simple yet effective method, NormLIME for aggregating local models into global and class-specific interpretations. A human user study strongly favored class-specific interpretations created by NormLIME to other feature importance metrics. Numerical experiments confirm that NormLIME is effective at recognizing important features.