 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Interpretability of Neural Networks Imply Adversarial Robustness?
Paper and Code

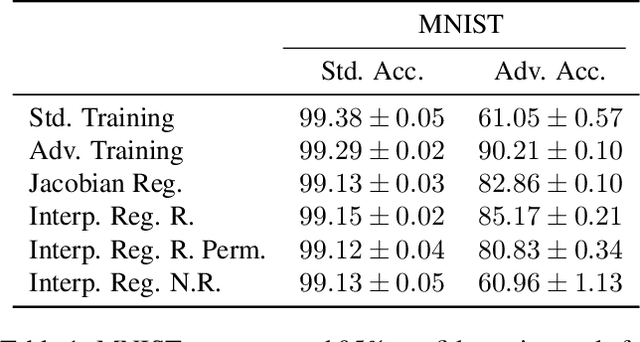
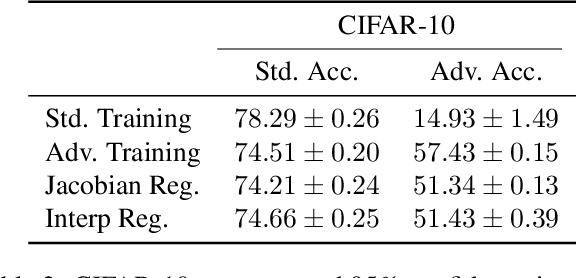

The success of deep neural networks is clouded by two issues that largely remain open to this day: the abundance of adversarial attacks that fool neural networks with small perturbations and the lack of interpretation for the predictions they make. Empirical evidence in the literature as well as theoretical analysis on simple models suggest these two seemingly disparate issues may actually be connected, as robust models tend to be more interpretable than non-robust models. In this paper, we provide evidence for the claim that this relationship is bidirectional. Viz., models that are forced to have interpretable gradients are more robust to adversarial examples than models trained in a standard manner. With further analysis and experiments, we identify two factors behind this phenomenon, namely the suppression of the gradient and the selective use of features guided by high-quality interpretations, which explain model behaviors under various regularization and target interpretation settings.