 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Interpretability of Neural Networks Imply Adversarial Robustness?
Dec 07, 2019
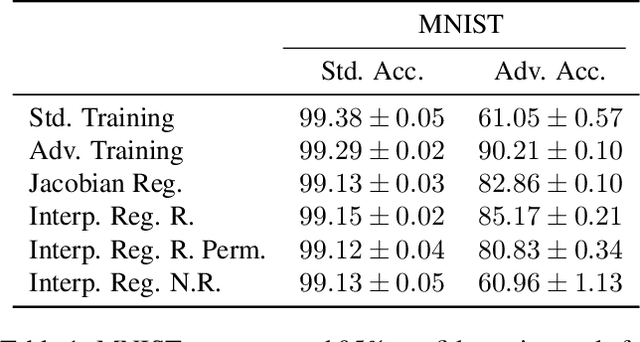
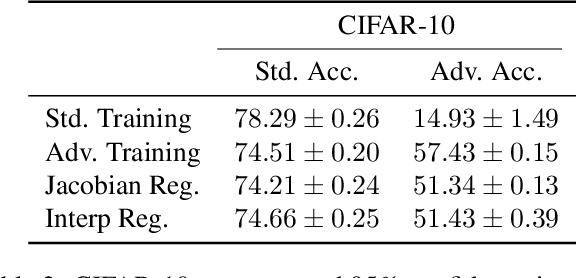

The success of deep neural networks is clouded by two issues that largely remain open to this day: the abundance of adversarial attacks that fool neural networks with small perturbations and the lack of interpretation for the predictions they make. Empirical evidence in the literature as well as theoretical analysis on simple models suggest these two seemingly disparate issues may actually be connected, as robust models tend to be more interpretable than non-robust models. In this paper, we provide evidence for the claim that this relationship is bidirectional. Viz., models that are forced to have interpretable gradients are more robust to adversarial examples than models trained in a standard manner. With further analysis and experiments, we identify two factors behind this phenomenon, namely the suppression of the gradient and the selective use of features guided by high-quality interpretations, which explain model behaviors under various regularization and target interpretation settings.
NormLime: A New Feature Importance Metric for Explaining Deep Neural Networks
Oct 15, 2019
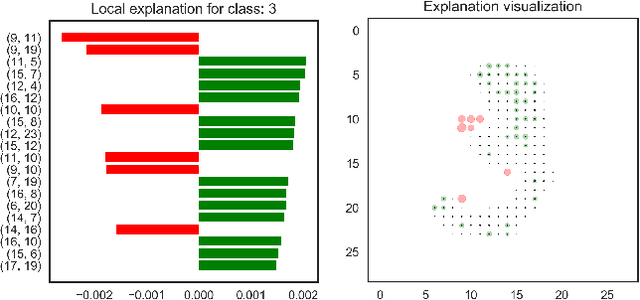
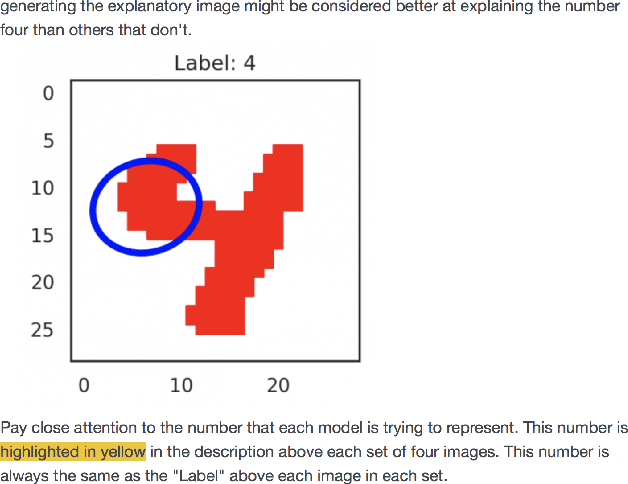
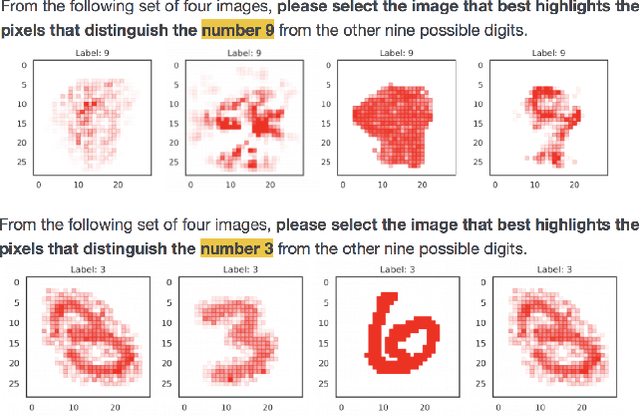
The problem of explaining deep learning models, and model predictions generally, has attracted intensive interest recently. Many successful approaches forgo global approximations in order to provide more faithful local interpretations of the model's behavior. LIME develops multiple interpretable models, each approximating a large neural network on a small region of the data manifold and SP-LIME aggregates the local models to form a global interpretation. Extending this line of research, we propose a simple yet effective method, NormLIME for aggregating local models into global and class-specific interpretations. A human user study strongly favored class-specific interpretations created by NormLIME to other feature importance metrics. Numerical experiments confirm that NormLIME is effective at recognizing important features.