 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Based Uncertainty Estimation for Gradient-Boosted Regression Trees
May 23, 2022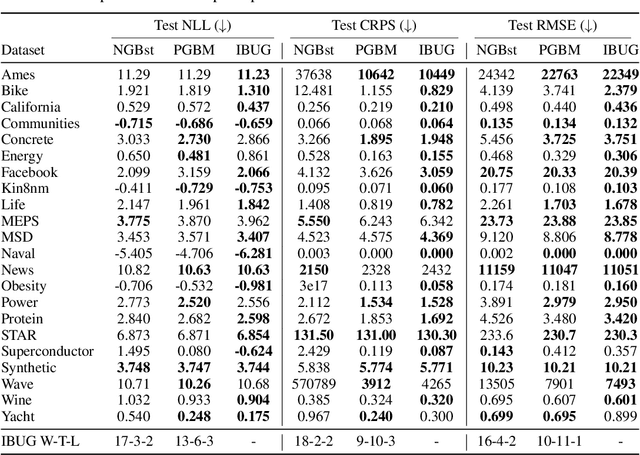


We propose Instance-Based Uncertainty estimation for Gradient-boosted regression trees~(IBUG), a simple method for extending any GBRT point predictor to produce probabilistic predictions. IBUG computes a non-parametric distribution around a prediction using the k-nearest training instances, where distance is measured with a tree-ensemble kernel. The runtime of IBUG depends on the number of training examples at each leaf in the ensemble, and can be improved by sampling trees or training instances. Empirically, we find that IBUG achieves similar or better performance than the previous state-of-the-art across 22 benchmark regression datasets. We also find that IBUG can achieve improved probabilistic performance by using different base GBRT models, and can more flexibly model the posterior distribution of a prediction than competing methods. We also find that previous methods suffer from poor probabilistic calibration on some datasets, which can be mitigated using a scalar factor tuned on the validation data.
Adapting and Evaluating Influence-Estimation Methods for Gradient-Boosted Decision Trees
Apr 30, 2022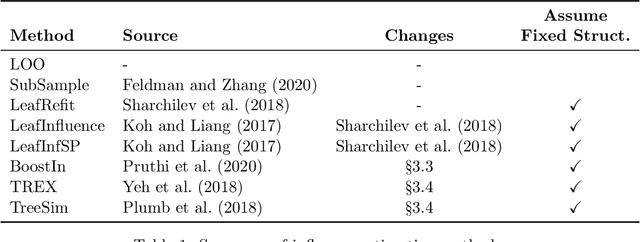

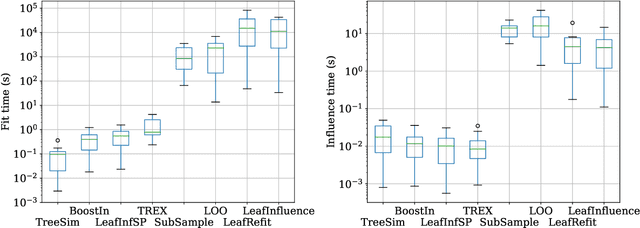
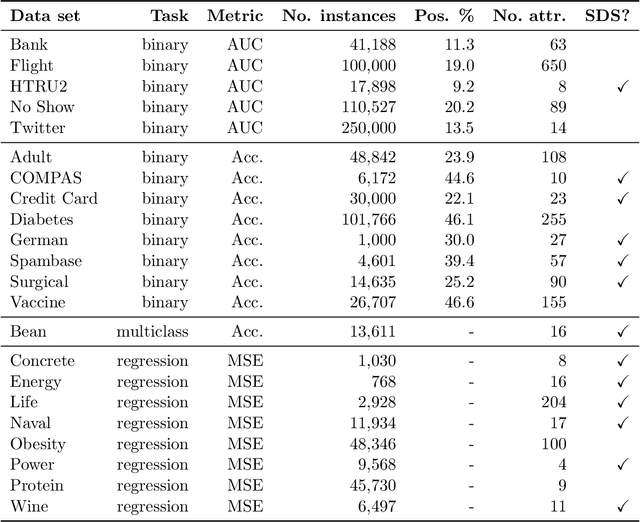
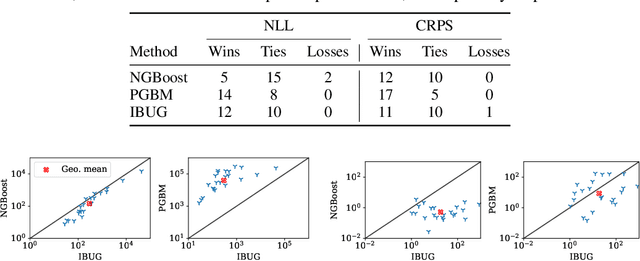
Influence estimation analyzes how changes to the training data can lead to different model predictions; this analysis can help us better understand these predictions, the models making those predictions, and the data sets they're trained on. However, most influence-estimation techniques are designed for deep learning models with continuous parameters. Gradient-boosted decision trees (GBDTs) are a powerful and widely-used class of models; however, these models are black boxes with opaque decision-making processes. In the pursuit of better understanding GBDT predictions and generally improving these models, we adapt recent and popular influence-estimation methods designed for deep learning models to GBDTs. Specifically, we adapt representer-point methods and TracIn, denoting our new methods TREX and BoostIn, respectively; source code is available at https://github.com/jjbrophy47/tree_influence. We compare these methods to LeafInfluence and other baselines using 5 different evaluation measures on 22 real-world data sets with 4 popular GBDT implementations. These experiments give us a comprehensive overview of how different approaches to influence estimation work in GBDT models. We find BoostIn is an efficient influence-estimation method for GBDTs that performs equally well or better than existing work while being four orders of magnitude faster. Our evaluation also suggests the gold-standard approach of leave-one-out~(LOO) retraining consistently identifies the single-most influential training example but performs poorly at finding the most influential set of training examples for a given target prediction.
Identifying Adversarial Attacks on Text Classifiers
Jan 21, 2022

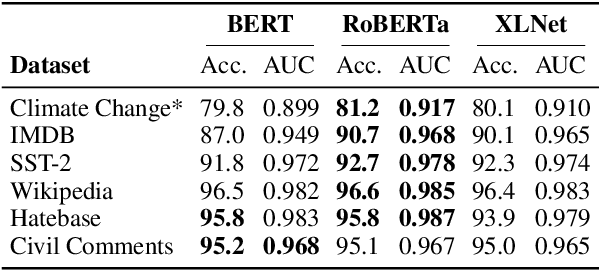
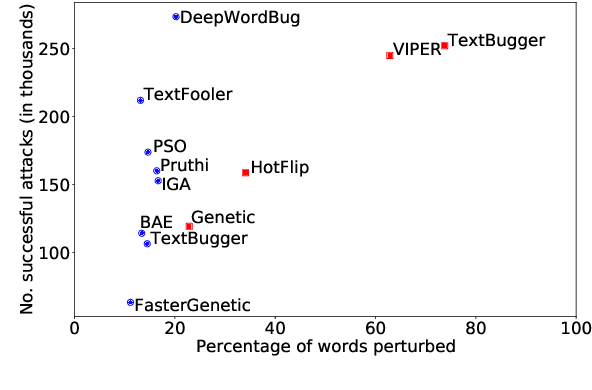
The landscape of adversarial attacks against text classifiers continues to grow, with new attacks developed every year and many of them available in standard toolkits, such as TextAttack and OpenAttack. In response, there is a growing body of work on robust learning, which reduces vulnerability to these attacks, though sometimes at a high cost in compute time or accuracy. In this paper, we take an alternate approach -- we attempt to understand the attacker by analyzing adversarial text to determine which methods were used to create it. Our first contribution is an extensive dataset for attack detection and labeling: 1.5~million attack instances, generated by twelve adversarial attacks targeting three classifiers trained on six source datasets for sentiment analysis and abuse detection in English. As our second contribution, we use this dataset to develop and benchmark a number of classifiers for attack identification -- determining if a given text has been adversarially manipulated and by which attack. As a third contribution, we demonstrate the effectiveness of three classes of features for these tasks: text properties, capturing content and presentation of text; language model properties, determining which tokens are more or less probable throughout the input; and target model properties, representing how the text classifier is influenced by the attack, including internal node activations. Overall, this represents a first step towards forensics for adversarial attacks against text classifiers.
TREX: Tree-Ensemble Representer-Point Explanations
Sep 24, 2020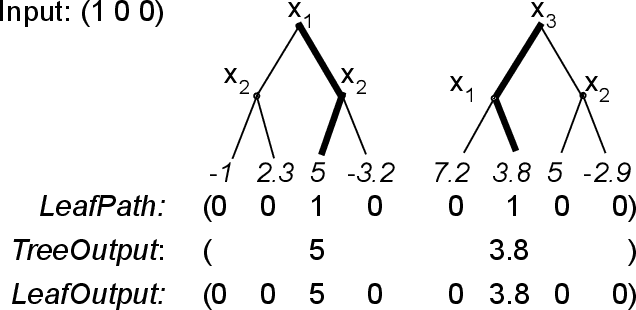
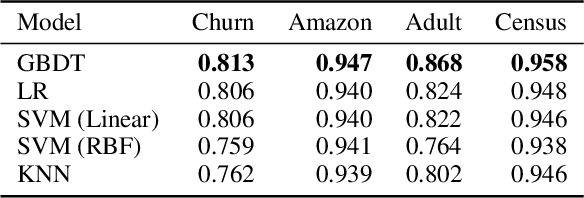
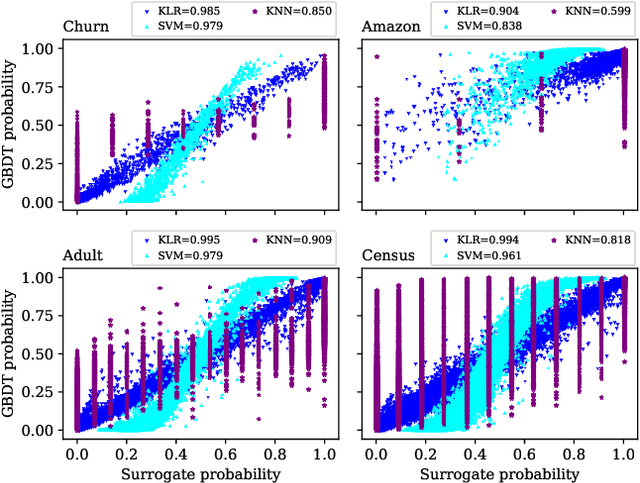

How can we identify the training examples that contribute most to the prediction of a tree ensemble? In this paper, we introduce TREX, an explanation system that provides instance-attribution explanations for tree ensembles, such as random forests and gradient boosted trees. TREX builds on the representer point framework previously developed for explaining deep neural networks. Since tree ensembles are non-differentiable, we define a kernel that captures the structure of the specific tree ensemble. By using this kernel in kernel logistic regression or a support vector machine, TREX builds a surrogate model that approximates the original tree ensemble. The weights in the kernel expansion of the surrogate model are used to define the global or local importance of each training example. Our experiments show that TREX's surrogate model accurately approximates the tree ensemble; its global importance weights are more effective in dataset debugging than the previous state-of-the-art; its explanations identify the most influential samples better than alternative methods under the remove and retrain evaluation framework; it runs orders of magnitude faster than alternative methods; and its local explanations can identify and explain errors due to domain mismatch.
DART: Data Addition and Removal Trees
Sep 11, 2020
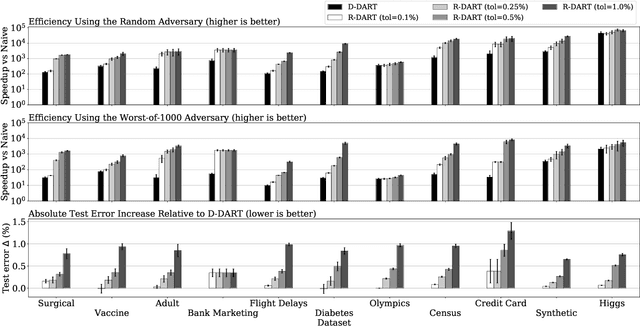
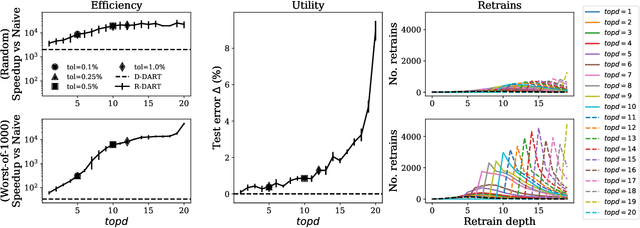

How can we update data for a machine learning model after it has already trained on that data? In this paper, we introduce DART, a variant of random forests that supports adding and removing training data with minimal retraining. Data updates in DART are exact, meaning that adding or removing examples from a DART model yields exactly the same model as retraining from scratch on updated data. DART uses two techniques to make updates efficient. The first is to cache data statistics at each node and training data at each leaf, so that only the necessary subtrees are retrained. The second is to choose the split variable randomly at the upper levels of each tree, so that the choice is completely independent of the data and never needs to change. At the lower levels, split variables are chosen to greedily maximize a split criterion such as Gini index or mutual information. By adjusting the number of random-split levels, DART can trade off between more accurate predictions and more efficient updates. In experiments on ten real-world datasets and one synthetic dataset, we find that DART is orders of magnitude faster than retraining from scratch while sacrificing very little in terms of predictive performance.
EGGS: A Flexible Approach to Relational Modeling of Social Network Spam
Jan 28, 2020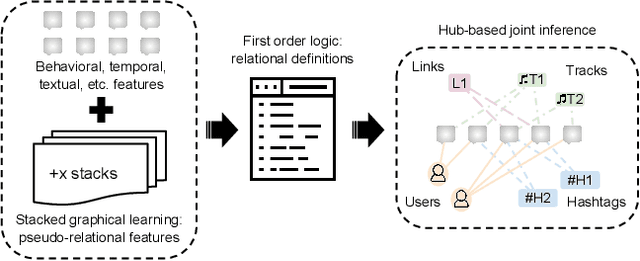


Social networking websites face a constant barrage of spam, unwanted messages that distract, annoy, and even defraud honest users. These messages tend to be very short, making them difficult to identify in isolation. Furthermore, spammers disguise their messages to look legitimate, tricking users into clicking on links and tricking spam filters into tolerating their malicious behavior. Thus, some spam filters examine relational structure in the domain, such as connections among users and messages, to better identify deceptive content. However, even when it is used, relational structure is often exploited in an incomplete or ad hoc manner. In this paper, we present Extended Group-based Graphical models for Spam (EGGS), a general-purpose method for classifying spam in online social networks. Rather than labeling each message independently, we group related messages together when they have the same author, the same content, or other domain-specific connections. To reason about related messages, we combine two popular methods: stacked graphical learning (SGL) and probabilistic graphical models (PGM). Both methods capture the idea that messages are more likely to be spammy when related messages are also spammy, but they do so in different ways; SGL uses sequential classifier predictions and PGMs use probabilistic inference. We apply our method to four different social network domains. EGGS is more accurate than an independent model in most experimental settings, especially when the correct label is uncertain. For the PGM implementation, we compare Markov logic networks to probabilistic soft logic and find that both work well with neither one dominating, and the combination of SGL and PGMs usually performs better than either on its own.