 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Data Addition and Removal Trees
Paper and Code

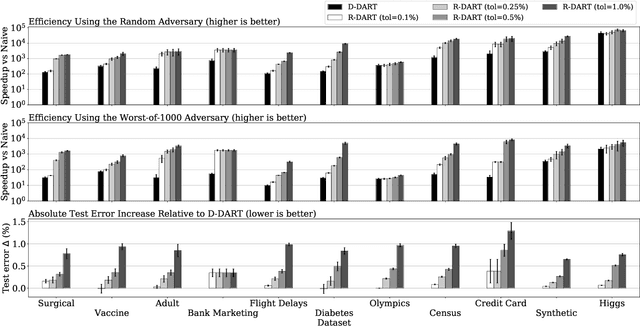
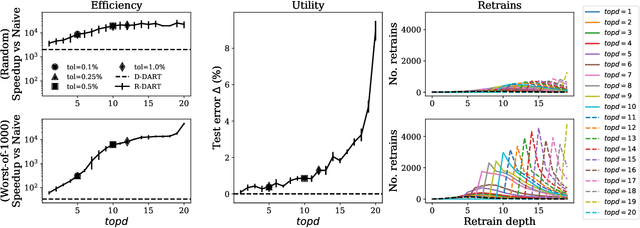

How can we update data for a machine learning model after it has already trained on that data? In this paper, we introduce DART, a variant of random forests that supports adding and removing training data with minimal retraining. Data updates in DART are exact, meaning that adding or removing examples from a DART model yields exactly the same model as retraining from scratch on updated data. DART uses two techniques to make updates efficient. The first is to cache data statistics at each node and training data at each leaf, so that only the necessary subtrees are retrained. The second is to choose the split variable randomly at the upper levels of each tree, so that the choice is completely independent of the data and never needs to change. At the lower levels, split variables are chosen to greedily maximize a split criterion such as Gini index or mutual information. By adjusting the number of random-split levels, DART can trade off between more accurate predictions and more efficient updates. In experiments on ten real-world datasets and one synthetic dataset, we find that DART is orders of magnitude faster than retraining from scratch while sacrificing very little in terms of predictive performance.