 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ultimate Cookbook for Invisible Poison: Crafting Subtle Clean-Label Text Backdoors with Style Attributes
Apr 24, 2025Backdoor attacks on text classifiers can cause them to predict a predefined label when a particular "trigger" is present. Prior attacks often rely on triggers that are ungrammatical or otherwise unusual, leading to conspicuous attacks. As a result, human annotators, who play a critical role in curating training data in practice, can easily detect and filter out these unnatural texts during manual inspection, reducing the risk of such attacks. We argue that a key criterion for a successful attack is for text with and without triggers to be indistinguishable to humans. However, prior work neither directly nor comprehensively evaluated attack subtlety and invisibility with human involvement. We bridge the gap by conducting thorough human evaluations to assess attack subtlety. We also propose \emph{AttrBkd}, consisting of three recipes for crafting subtle yet effective trigger attributes, such as extracting fine-grained attributes from existing baseline backdoor attacks. Our human evaluations find that AttrBkd with these baseline-derived attributes is often more effective (higher attack success rate) and more subtle (fewer instances detected by humans) than the original baseline backdoor attacks, demonstrating that backdoor attacks can bypass detection by being inconspicuous and appearing natural even upon close inspection, while still remaining effective. Our human annotation also provides information not captured by automated metrics used in prior work, and demonstrates the misalignment of these metrics with human judgment.
Large Language Models Are Better Adversaries: Exploring Generative Clean-Label Backdoor Attacks Against Text Classifiers
Oct 28, 2023Backdoor attacks manipulate model predictions by inserting innocuous triggers into training and test data. We focus on more realistic and more challenging clean-label attacks where the adversarial training examples are correctly labeled. Our attack, LLMBkd, leverages language models to automatically insert diverse style-based triggers into texts. We also propose a poison selection technique to improve the effectiveness of both LLMBkd as well as existing textual backdoor attacks. Lastly, we describe REACT, a baseline defense to mitigate backdoor attacks via antidote training examples. Our evaluations demonstrate LLMBkd's effectiveness and efficiency, where we consistently achieve high attack success rates across a wide range of styles with little effort and no model training.
Identifying Adversarial Attacks on Text Classifiers
Jan 21, 2022

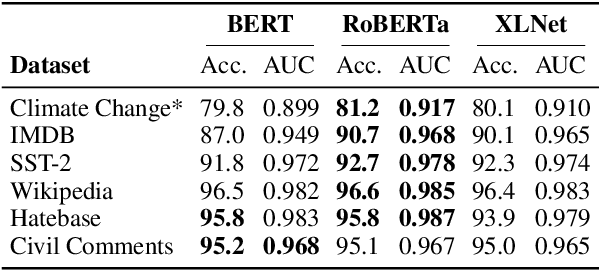
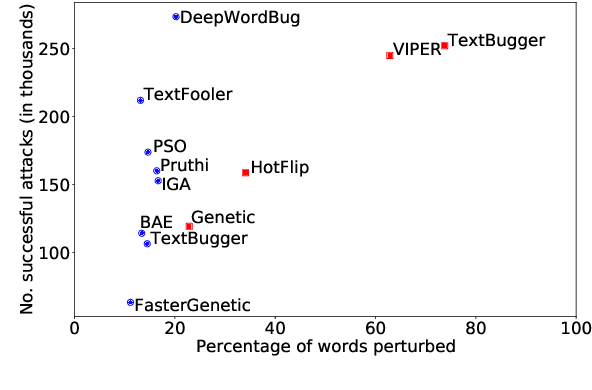
The landscape of adversarial attacks against text classifiers continues to grow, with new attacks developed every year and many of them available in standard toolkits, such as TextAttack and OpenAttack. In response, there is a growing body of work on robust learning, which reduces vulnerability to these attacks, though sometimes at a high cost in compute time or accuracy. In this paper, we take an alternate approach -- we attempt to understand the attacker by analyzing adversarial text to determine which methods were used to create it. Our first contribution is an extensive dataset for attack detection and labeling: 1.5~million attack instances, generated by twelve adversarial attacks targeting three classifiers trained on six source datasets for sentiment analysis and abuse detection in English. As our second contribution, we use this dataset to develop and benchmark a number of classifiers for attack identification -- determining if a given text has been adversarially manipulated and by which attack. As a third contribution, we demonstrate the effectiveness of three classes of features for these tasks: text properties, capturing content and presentation of text; language model properties, determining which tokens are more or less probable throughout the input; and target model properties, representing how the text classifier is influenced by the attack, including internal node activations. Overall, this represents a first step towards forensics for adversarial attacks against text classifiers.