 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Adversarial Fine-Tuning Benefit BERT?
Paper and Code
Aug 31, 2021
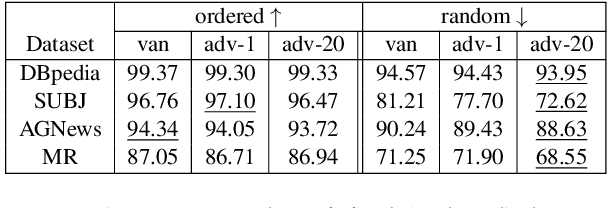
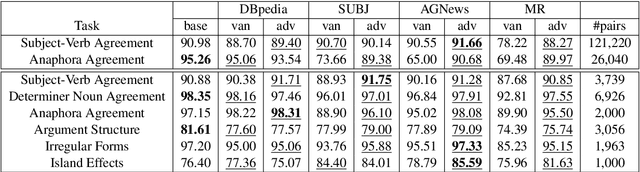

Adversarial training (AT) is one of the most reliable methods for defending against adversarial attacks in machine learning. Variants of this method have been used as regularization mechanisms to achieve SOTA results on NLP benchmarks, and they have been found to be useful for transfer learning and continual learning. We search for the reasons for the effectiveness of AT by contrasting vanilla and adversarially fine-tuned BERT models. We identify partial preservation of BERT's syntactic abilities during fine-tuning as the key to the success of AT. We observe that adversarially fine-tuned models remain more faithful to BERT's language modeling behavior and are more sensitive to the word order. As concrete examples of syntactic abilities, an adversarially fine-tuned model could have an advantage of up to 38% on anaphora agreement and up to 11% on dependency parsing. Our analysis demonstrates that vanilla fine-tuning oversimplifies the sentence representation by focusing heavily on one or a few label-indicative words. AT, however, moderates the effect of these influential words and encourages representational diversity. This allows for a more hierarchical representation of a sentence and leads to the mitigation of BERT's loss of syntactic abilities.