 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemSCoRe: a $M$ultilingual and Scalable Benchmark for $S$kill-based $Co$mmonsense $Re$asoning
Aug 13, 2025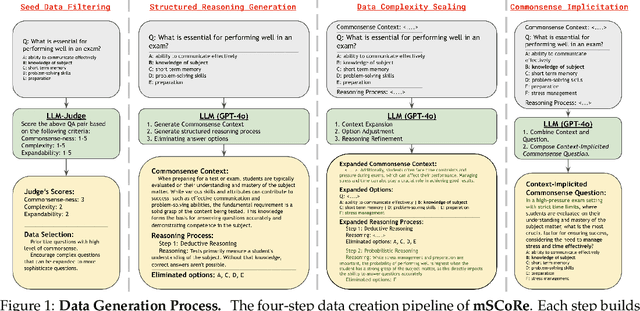

Recent advancements in reasoning-reinforced Large Language Models (LLMs) have shown remarkable capabilities in complex reasoning tasks. However, the mechanism underlying their utilization of different human reasoning skills remains poorly investigated, especially for multilingual commonsense reasoning that involves everyday knowledge across different languages and cultures. To address this gap, we propose a \textbf{M}ultilingual and Scalable Benchmark for \textbf{S}kill-based \textbf{Co}mmonsense \textbf{Re}asoning (\textbf{mSCoRe}). Our benchmark incorporates three key components that are designed to systematically evaluate LLM's reasoning capabilities, including: (1) a novel taxonomy of reasoning skills that enables fine-grained analysis of models' reasoning processes, (2) a robust data synthesis pipeline tailored specifically for commonsense reasoning evaluation, and (3) a complexity scaling framework allowing task difficulty to scale dynamically alongside future improvements in LLM abilities. Extensive experiments on eights state-of-the-art LLMs of varying sizes and training approaches demonstrate that \textbf{mSCoRe} remains significantly challenging for current models, particularly at higher complexity levels. Our results reveal the limitations of such reasoning-reinforced models when confronted with nuanced multilingual general and cultural commonsense. We further provide detailed analysis on the models' reasoning processes, suggesting future directions for improving multilingual commonsense reasoning capabilities.
LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models
Jan 01, 2025



Recent advancements in large language models (LLMs) based embedding models have established new state-of-the-art benchmarks for text embedding tasks, particularly in dense vector-based retrieval. However, these models predominantly focus on English, leaving multilingual embedding capabilities largely unexplored. To address this limitation, we present LUSIFER, a novel zero-shot approach that adapts LLM-based embedding models for multilingual tasks without requiring multilingual supervision. LUSIFER's architecture combines a multilingual encoder, serving as a language-universal learner, with an LLM-based embedding model optimized for embedding-specific tasks. These components are seamlessly integrated through a minimal set of trainable parameters that act as a connector, effectively transferring the multilingual encoder's language understanding capabilities to the specialized embedding model. Additionally, to comprehensively evaluate multilingual embedding performance, we introduce a new benchmark encompassing 5 primary embedding tasks, 123 diverse datasets, and coverage across 14 languages. Extensive experimental results demonstrate that LUSIFER significantly enhances the multilingual performance across various embedding tasks, particularly for medium and low-resource languages, without requiring explicit multilingual training data.
Comprehensive and Practical Evaluation of Retrieval-Augmented Generation Systems for Medical Question Answering
Nov 14, 2024



Retrieval-augmented generation (RAG) has emerged as a promising approach to enhance the performance of large language models (LLMs) in knowledge-intensive tasks such as those from medical domain. However, the sensitive nature of the medical domain necessitates a completely accurate and trustworthy system. While existing RAG benchmarks primarily focus on the standard retrieve-answer setting, they overlook many practical scenarios that measure crucial aspects of a reliable medical system. This paper addresses this gap by providing a comprehensive evaluation framework for medical question-answering (QA) systems in a RAG setting for these situations, including sufficiency, integration, and robustness. We introduce Medical Retrieval-Augmented Generation Benchmark (MedRGB) that provides various supplementary elements to four medical QA datasets for testing LLMs' ability to handle these specific scenarios. Utilizing MedRGB, we conduct extensive evaluations of both state-of-the-art commercial LLMs and open-source models across multiple retrieval conditions. Our experimental results reveals current models' limited ability to handle noise and misinformation in the retrieved documents. We further analyze the LLMs' reasoning processes to provides valuable insights and future directions for developing RAG systems in this critical medical domain.
Zero-shot Cross-lingual Transfer Learning with Multiple Source and Target Languages for Information Extraction: Language Selection and Adversarial Training
Nov 13, 2024



The majority of previous researches addressing multi-lingual IE are limited to zero-shot cross-lingual single-transfer (one-to-one) setting, with high-resource languages predominantly as source training data. As a result, these works provide little understanding and benefit for the realistic goal of developing a multi-lingual IE system that can generalize to as many languages as possible. Our study aims to fill this gap by providing a detailed analysis on Cross-Lingual Multi-Transferability (many-to-many transfer learning), for the recent IE corpora that cover a diverse set of languages. Specifically, we first determine the correlation between single-transfer performance and a wide range of linguistic-based distances. From the obtained insights, a combined language distance metric can be developed that is not only highly correlated but also robust across different tasks and model scales. Next, we investigate the more general zero-shot multi-lingual transfer settings where multiple languages are involved in the training and evaluation processes. Language clustering based on the newly defined distance can provide directions for achieving the optimal cost-performance trade-off in data (languages) selection problem. Finally, a relational-transfer setting is proposed to further incorporate multi-lingual unlabeled data based on adversarial training using the relation induced from the above linguistic distance.
ULLME: A Unified Framework for Large Language Model Embeddings with Generation-Augmented Learning
Aug 06, 2024


Large Language Models (LLMs) excel in various natural language processing tasks, but leveraging them for dense passage embedding remains challenging. This is due to their causal attention mechanism and the misalignment between their pre-training objectives and the text ranking tasks. Despite some recent efforts to address these issues, existing frameworks for LLM-based text embeddings have been limited by their support for only a limited range of LLM architectures and fine-tuning strategies, limiting their practical application and versatility. In this work, we introduce the Unified framework for Large Language Model Embedding (ULLME), a flexible, plug-and-play implementation that enables bidirectional attention across various LLMs and supports a range of fine-tuning strategies. We also propose Generation-augmented Representation Learning (GRL), a novel fine-tuning method to boost LLMs for text embedding tasks. GRL enforces consistency between representation-based and generation-based relevance scores, leveraging LLMs' powerful generative abilities for learning passage embeddings. To showcase our framework's flexibility and effectiveness, we release three pre-trained models from ULLME with different backbone architectures, ranging from 1.5B to 8B parameters, all of which demonstrate strong performance on the Massive Text Embedding Benchmark. Our framework is publicly available at: https://github.com/nlp-uoregon/ullme. A demo video for ULLME can also be found at https://rb.gy/ws1ile.
CulturaX: A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages
Sep 17, 2023The driving factors behind the development of large language models (LLMs) with impressive learning capabilities are their colossal model sizes and extensive training datasets. Along with the progress in natural language processing, LLMs have been frequently made accessible to the public to foster deeper investigation and applications. However, when it comes to training datasets for these LLMs, especially the recent state-of-the-art models, they are often not fully disclosed. Creating training data for high-performing LLMs involves extensive cleaning and deduplication to ensure the necessary level of quality. The lack of transparency for training data has thus hampered research on attributing and addressing hallucination and bias issues in LLMs, hindering replication efforts and further advancements in the community. These challenges become even more pronounced in multilingual learning scenarios, where the available multilingual text datasets are often inadequately collected and cleaned. Consequently, there is a lack of open-source and readily usable dataset to effectively train LLMs in multiple languages. To overcome this issue, we present CulturaX, a substantial multilingual dataset with 6.3 trillion tokens in 167 languages, tailored for LLM development. Our dataset undergoes meticulous cleaning and deduplication through a rigorous pipeline of multiple stages to accomplish the best quality for model training, including language identification, URL-based filtering, metric-based cleaning, document refinement, and data deduplication. CulturaX is fully released to the public in HuggingFace to facilitate research and advancements in multilingual LLMs: https://huggingface.co/datasets/uonlp/CulturaX.
Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback
Aug 02, 2023


A key technology for the development of large language models (LLMs) involves instruction tuning that helps align the models' responses with human expectations to realize impressive learning abilities. Two major approaches for instruction tuning characterize supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), which are currently applied to produce the best commercial LLMs (e.g., ChatGPT). To improve the accessibility of LLMs for research and development efforts, various instruction-tuned open-source LLMs have also been introduced recently, e.g., Alpaca, Vicuna, to name a few. However, existing open-source LLMs have only been instruction-tuned for English and a few popular languages, thus hindering their impacts and accessibility to many other languages in the world. Among a few very recent work to explore instruction tuning for LLMs in multiple languages, SFT has been used as the only approach to instruction-tune LLMs for multiple languages. This has left a significant gap for fine-tuned LLMs based on RLHF in diverse languages and raised important questions on how RLHF can boost the performance of multilingual instruction tuning. To overcome this issue, we present Okapi, the first system with instruction-tuned LLMs based on RLHF for multiple languages. Okapi introduces instruction and response-ranked data in 26 diverse languages to facilitate the experiments and development of future multilingual LLM research. We also present benchmark datasets to enable the evaluation of generative LLMs in multiple languages. Our experiments demonstrate the advantages of RLHF for multilingual instruction over SFT for different base models and datasets. Our framework and resources are released at https://github.com/nlp-uoregon/Okapi.
ChatGPT Beyond English: Towards a Comprehensive Evaluation of Large Language Models in Multilingual Learning
Apr 12, 2023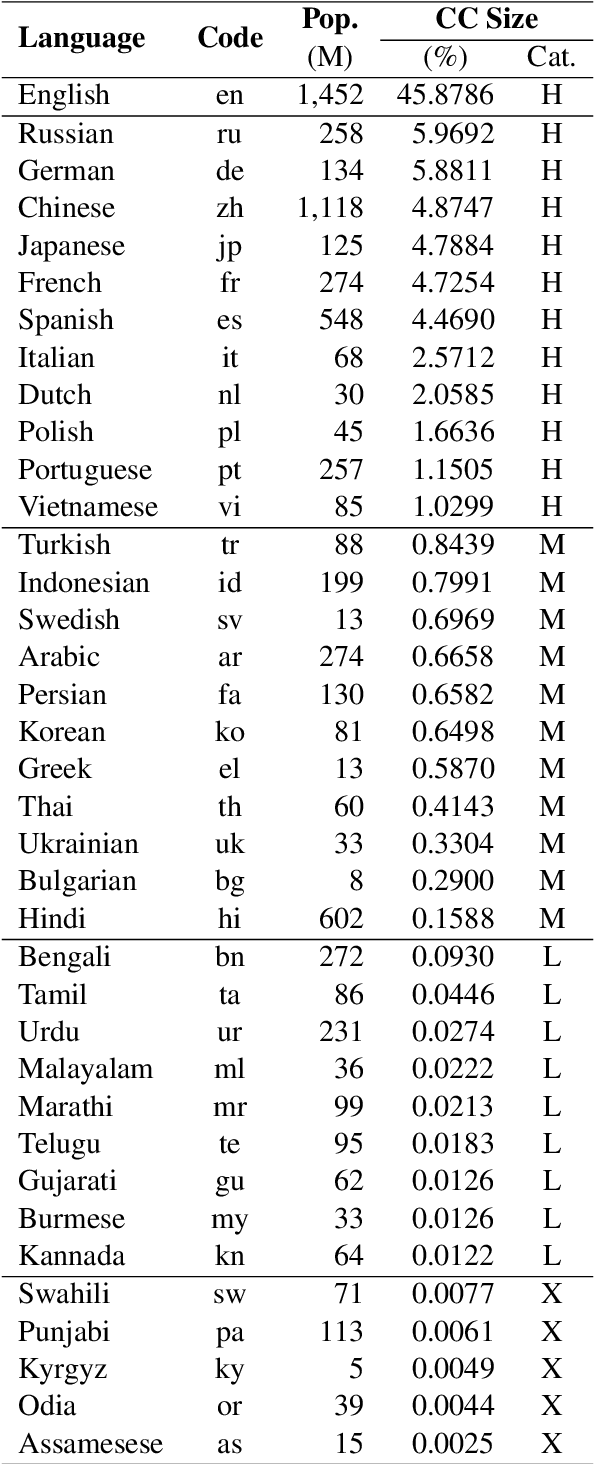
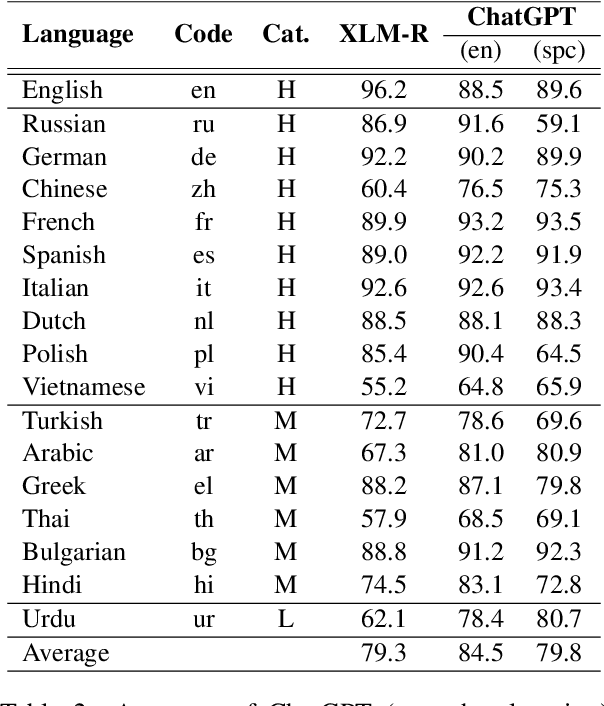
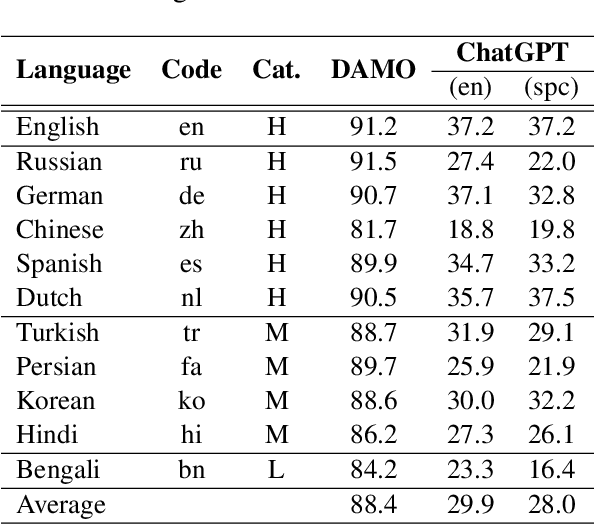
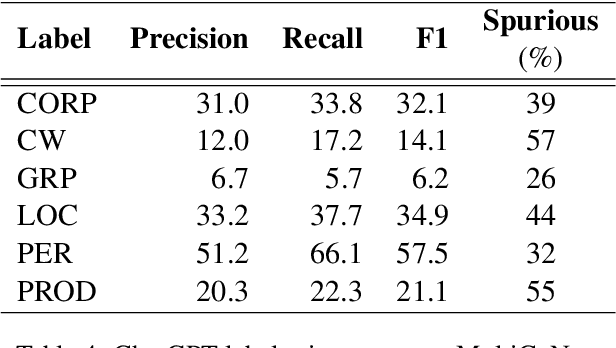
Over the last few years, large language models (LLMs) have emerged as the most important breakthroughs in natural language processing (NLP) that fundamentally transform research and developments in the field. ChatGPT represents one of the most exciting LLM systems developed recently to showcase impressive skills for language generation and highly attract public attention. Among various exciting applications discovered for ChatGPT in English, the model can process and generate texts for multiple languages due to its multilingual training data. Given the broad adoption of ChatGPT for English in different problems and areas, a natural question is whether ChatGPT can also be applied effectively for other languages or it is necessary to develop more language-specific technologies. The answer to this question requires a thorough evaluation of ChatGPT over multiple tasks with diverse languages and large datasets (i.e., beyond reported anecdotes), which is still missing or limited in current research. Our work aims to fill this gap for the evaluation of ChatGPT and similar LLMs to provide more comprehensive information for multilingual NLP applications. While this work will be an ongoing effort to include additional experiments in the future, our current paper evaluates ChatGPT on 7 different tasks, covering 37 diverse languages with high, medium, low, and extremely low resources. We also focus on the zero-shot learning setting for ChatGPT to improve reproducibility and better simulate the interactions of general users. Compared to the performance of previous models, our extensive experimental results demonstrate a worse performance of ChatGPT for different NLP tasks and languages, calling for further research to develop better models and understanding for multilingual learning.
FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
Feb 16, 2022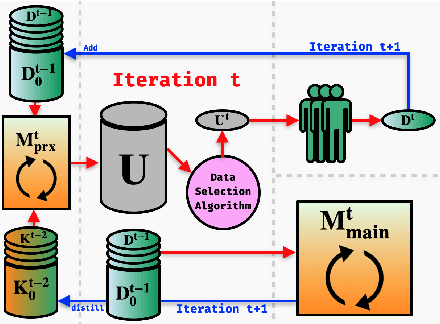


This paper presents FAMIE, a comprehensive and efficient active learning (AL) toolkit for multilingual information extraction. FAMIE is designed to address a fundamental problem in existing AL frameworks where annotators need to wait for a long time between annotation batches due to the time-consuming nature of model training and data selection at each AL iteration. This hinders the engagement, productivity, and efficiency of annotators. Based on the idea of using a small proxy network for fast data selection, we introduce a novel knowledge distillation mechanism to synchronize the proxy network with the main large model (i.e., BERT-based) to ensure the appropriateness of the selected annotation examples for the main model. Our AL framework can support multiple languages. The experiments demonstrate the advantages of FAMIE in terms of competitive performance and time efficiency for sequence labeling with AL. We publicly release our code (\url{https://github.com/nlp-uoregon/famie}) and demo website (\url{http://nlp.uoregon.edu:9000/}). A demo video for FAMIE is provided at: \url{https://youtu.be/I2i8n_jAyrY}.