 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Pretraining Improves Entity Tracking Abilities of Language Models
Paper and Code
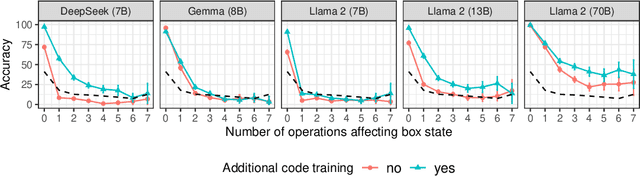
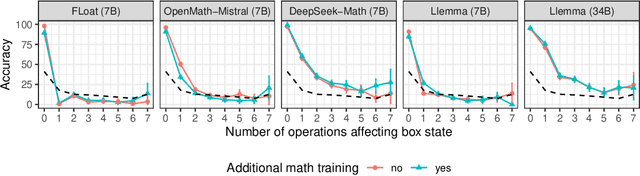

Recent work has provided indirect evidence that pretraining language models on code improves the ability of models to track state changes of discourse entities expressed in natural language. In this work, we systematically test this claim by comparing pairs of language models on their entity tracking performance. Critically, the pairs consist of base models and models trained on top of these base models with additional code data. We extend this analysis to additionally examine the effect of math training, another highly structured data type, and alignment tuning, an important step for enhancing the usability of models. We find clear evidence that models additionally trained on large amounts of code outperform the base models. On the other hand, we find no consistent benefit of additional math training or alignment tuning across various model families.