 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Flow caching for autoregressive video generation
Feb 11, 2026Autoregressive models, often built on Transformer architectures, represent a powerful paradigm for generating ultra-long videos by synthesizing content in sequential chunks. However, this sequential generation process is notoriously slow. While caching strategies have proven effective for accelerating traditional video diffusion models, existing methods assume uniform denoising across all frames-an assumption that breaks down in autoregressive models where different video chunks exhibit varying similarity patterns at identical timesteps. In this paper, we present FlowCache, the first caching framework specifically designed for autoregressive video generation. Our key insight is that each video chunk should maintain independent caching policies, allowing fine-grained control over which chunks require recomputation at each timestep. We introduce a chunkwise caching strategy that dynamically adapts to the unique denoising characteristics of each chunk, complemented by a joint importance-redundancy optimized KV cache compression mechanism that maintains fixed memory bounds while preserving generation quality. Our method achieves remarkable speedups of 2.38 times on MAGI-1 and 6.7 times on SkyReels-V2, with negligible quality degradation (VBench: 0.87 increase and 0.79 decrease respectively). These results demonstrate that FlowCache successfully unlocks the potential of autoregressive models for real-time, ultra-long video generation-establishing a new benchmark for efficient video synthesis at scale. The code is available at https://github.com/mikeallen39/FlowCache.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
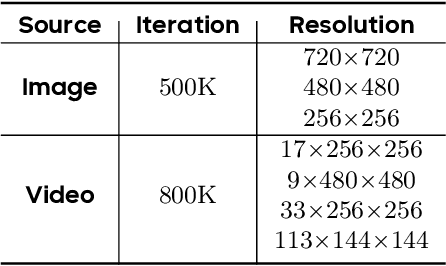
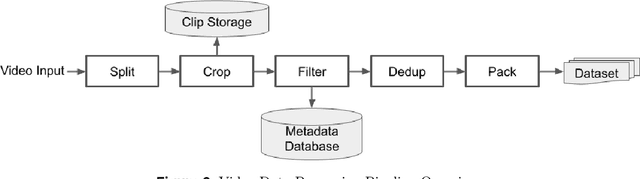

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Deep Dive into Model-free Reinforcement Learning for Biological and Robotic Systems: Theory and Practice
May 19, 2024


Animals and robots exist in a physical world and must coordinate their bodies to achieve behavioral objectives. With recent developments in deep reinforcement learning, it is now possible for scientists and engineers to obtain sensorimotor strategies (policies) for specific tasks using physically simulated bodies and environments. However, the utility of these methods goes beyond the constraints of a specific task; they offer an exciting framework for understanding the organization of an animal sensorimotor system in connection to its morphology and physical interaction with the environment, as well as for deriving general design rules for sensing and actuation in robotic systems. Algorithms and code implementing both learning agents and environments are increasingly available, but the basic assumptions and choices that go into the formulation of an embodied feedback control problem using deep reinforcement learning may not be immediately apparent. Here, we present a concise exposition of the mathematical and algorithmic aspects of model-free reinforcement learning, specifically through the use of \textit{actor-critic} methods, as a tool for investigating the feedback control underlying animal and robotic behavior.
AffineQuant: Affine Transformation Quantization for Large Language Models
Mar 19, 2024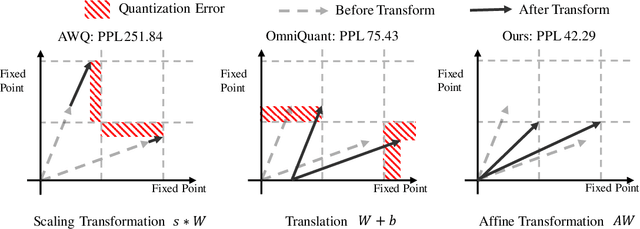
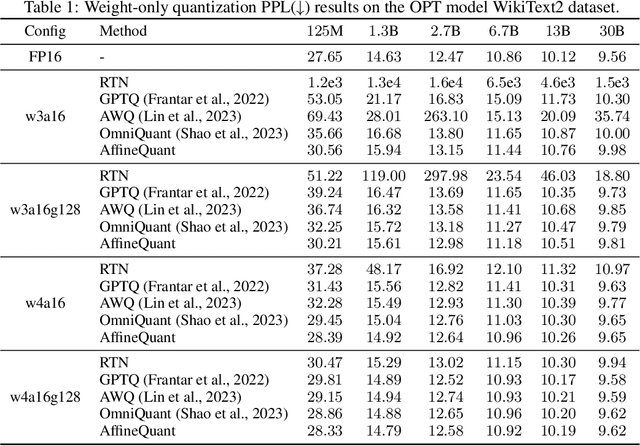
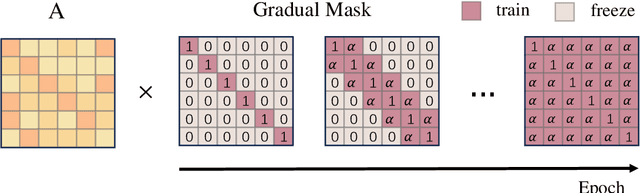
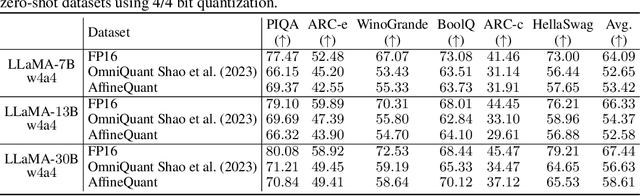
The significant resource requirements associated with Large-scale Language Models (LLMs) have generated considerable interest in the development of techniques aimed at compressing and accelerating neural networks. Among these techniques, Post-Training Quantization (PTQ) has emerged as a subject of considerable interest due to its noteworthy compression efficiency and cost-effectiveness in the context of training. Existing PTQ methods for LLMs limit the optimization scope to scaling transformations between pre- and post-quantization weights. In this paper, we advocate for the direct optimization using equivalent Affine transformations in PTQ (AffineQuant). This approach extends the optimization scope and thus significantly minimizing quantization errors. Additionally, by employing the corresponding inverse matrix, we can ensure equivalence between the pre- and post-quantization outputs of PTQ, thereby maintaining its efficiency and generalization capabilities. To ensure the invertibility of the transformation during optimization, we further introduce a gradual mask optimization method. This method initially focuses on optimizing the diagonal elements and gradually extends to the other elements. Such an approach aligns with the Levy-Desplanques theorem, theoretically ensuring invertibility of the transformation. As a result, significant performance improvements are evident across different LLMs on diverse datasets. To illustrate, we attain a C4 perplexity of 15.76 (2.26 lower vs 18.02 in OmniQuant) on the LLaMA2-7B model of W4A4 quantization without overhead. On zero-shot tasks, AffineQuant achieves an average of 58.61 accuracy (1.98 lower vs 56.63 in OmniQuant) when using 4/4-bit quantization for LLaMA-30B, which setting a new state-of-the-art benchmark for PTQ in LLMs.
A free lunch from ViT:Adaptive Attention Multi-scale Fusion Transformer for Fine-grained Visual Recognition
Oct 11, 2021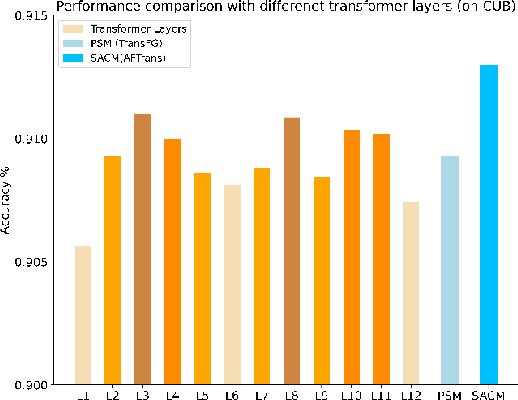
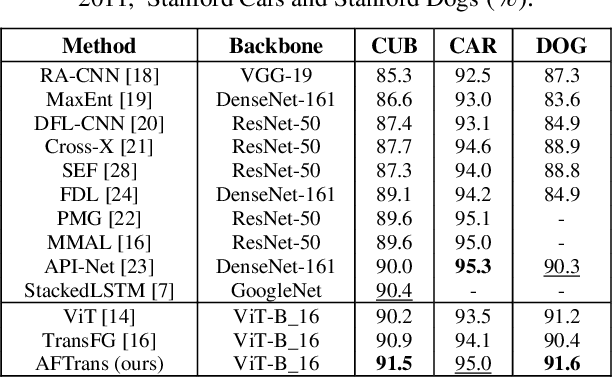
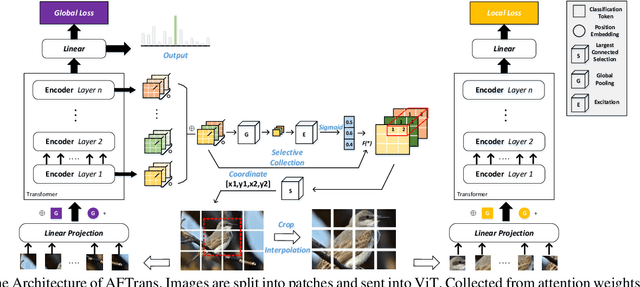

Learning subtle representation about object parts plays a vital role in fine-grained visual recognition (FGVR) field. The vision transformer (ViT) achieves promising results on computer vision due to its attention mechanism. Nonetheless, with the fixed size of patches in ViT, the class token in deep layer focuses on the global receptive field and cannot generate multi-granularity features for FGVR. To capture region attention without box annotations and compensate for ViT shortcomings in FGVR, we propose a novel method named Adaptive attention multi-scale Fusion Transformer (AFTrans). The Selective Attention Collection Module (SACM) in our approach leverages attention weights in ViT and filters them adaptively to correspond with the relative importance of input patches. The multiple scales (global and local) pipeline is supervised by our weights sharing encoder and can be easily trained end-to-end. Comprehensive experiments demonstrate that AFTrans can achieve SOTA performance on three published fine-grained benchmarks: CUB-200-2011, Stanford Dogs and iNat2017.
Learning to swim in potential flow
Sep 30, 2020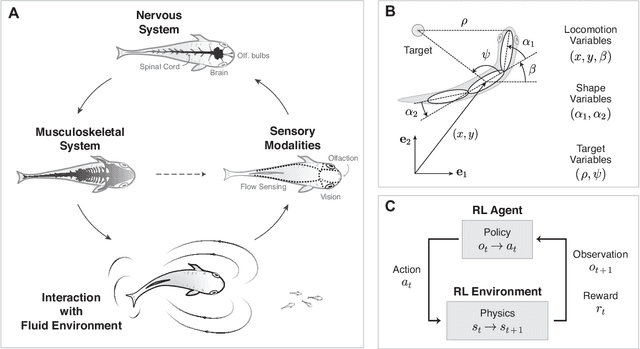
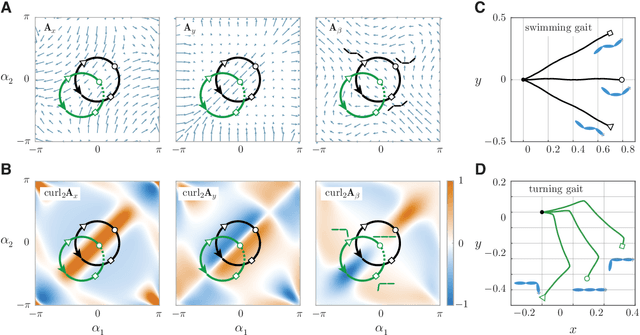
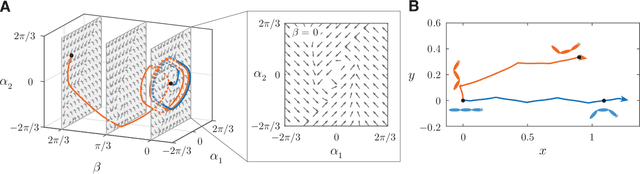
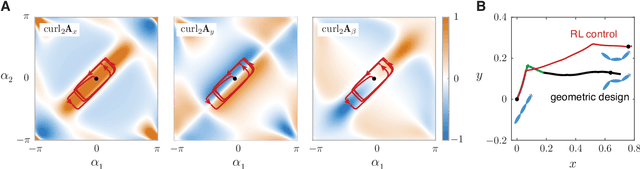
Fish swim by undulating their bodies. These propulsive motions require coordinated shape changes of a body that interacts with its fluid environment, but the specific shape coordination that leads to robust turning and swimming motions remains unclear. We propose a simple model of a three-link fish swimming in a potential flow environment and we use model-free reinforcement learning to arrive at optimal shape changes for two swimming tasks: swimming in a desired direction and swimming towards a known target. This fish model belongs to a class of problems in geometric mechanics, known as driftless dynamical systems, which allow us to analyze the swimming behavior in terms of geometric phases over the shape space of the fish. These geometric methods are less intuitive in the presence of drift. Here, we use the shape space analysis as a tool for assessing, visualizing, and interpreting the control policies obtained via reinforcement learning in the absence of drift. We then examine the robustness of these policies to drift-related perturbations. Although the fish has no direct control over the drift itself, it learns to take advantage of the presence of moderate drift to reach its target.
Cloud detection in Landsat-8 imagery in Google Earth Engine based on a deep neural network
Jun 18, 2020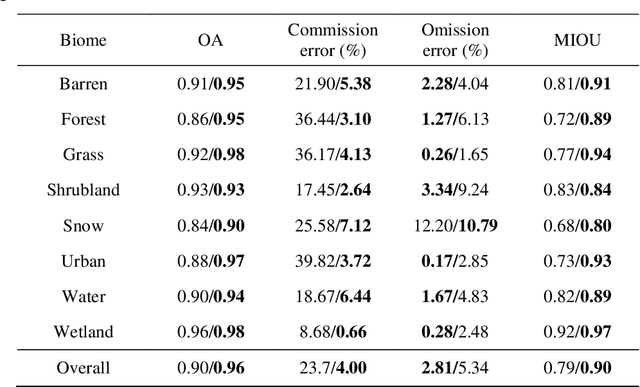
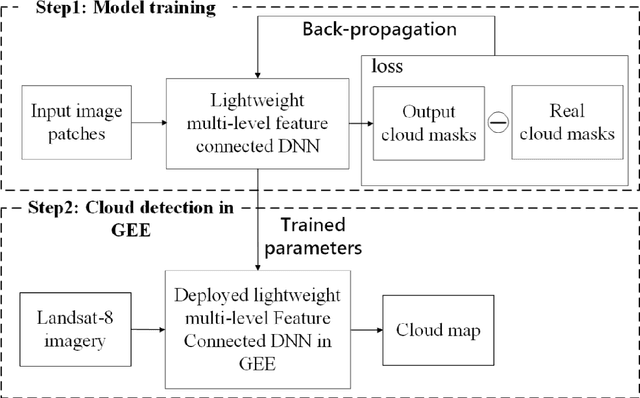
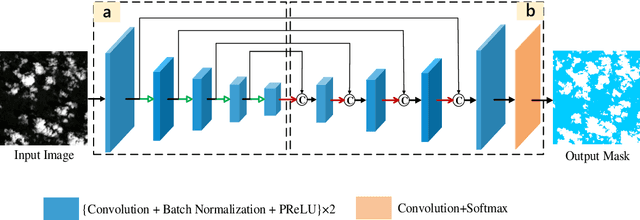
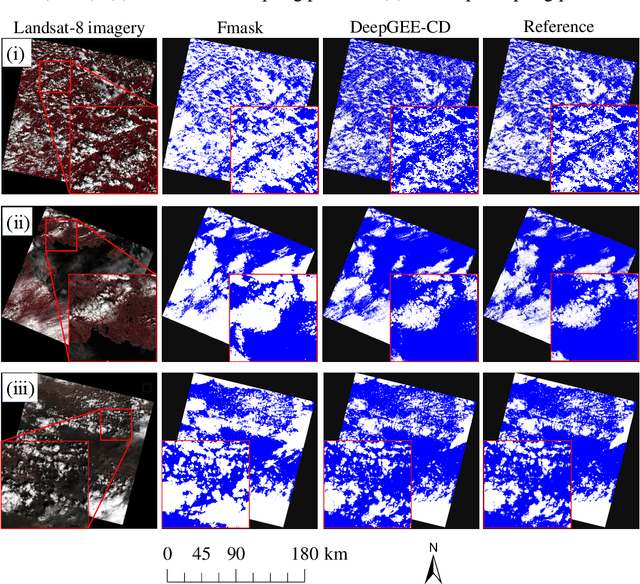
Google Earth Engine (GEE) provides a convenient platform for applications based on optical satellite imagery of large areas. With such data sets, the detection of cloud is often a necessary prerequisite step. Recently, deep learning-based cloud detection methods have shown their potential for cloud detection but they can only be applied locally, leading to inefficient data downloading time and storage problems. This letter proposes a method to directly perform cloud detection in Landsat-8 imagery in GEE based on deep learning (DeepGEE-CD). A deep neural network (DNN) was first trained locally, and then the trained DNN was deployed in the JavaScript client of GEE. An experiment was undertaken to validate the proposed method with a set of Landsat-8 images and the results show that DeepGEE-CD outperformed the widely used function of mask (Fmask) algorithm. The proposed DeepGEE-CD approach can accurately detect cloud in Landsat-8 imagery without downloading it, making it a promising method for routine cloud detection of Landsat-8 imagery in GEE.