 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
GUI-Eyes: Tool-Augmented Perception for Visual Grounding in GUI Agents
Jan 14, 2026Recent advances in vision-language models (VLMs) and reinforcement learning (RL) have driven progress in GUI automation. However, most existing methods rely on static, one-shot visual inputs and passive perception, lacking the ability to adaptively determine when, whether, and how to observe the interface. We present GUI-Eyes, a reinforcement learning framework for active visual perception in GUI tasks. To acquire more informative observations, the agent learns to make strategic decisions on both whether and how to invoke visual tools, such as cropping or zooming, within a two-stage reasoning process. To support this behavior, we introduce a progressive perception strategy that decomposes decision-making into coarse exploration and fine-grained grounding, coordinated by a two-level policy. In addition, we design a spatially continuous reward function tailored to tool usage, which integrates both location proximity and region overlap to provide dense supervision and alleviate the reward sparsity common in GUI environments. On the ScreenSpot-Pro benchmark, GUI-Eyes-3B achieves 44.8% grounding accuracy using only 3k labeled samples, significantly outperforming both supervised and RL-based baselines. These results highlight that tool-aware active perception, enabled by staged policy reasoning and fine-grained reward feedback, is critical for building robust and data-efficient GUI agents.
Diffusion Model in Hyperspectral Image Processing and Analysis: A Review
May 16, 2025Hyperspectral image processing and analysis has important application value in remote sensing, agriculture and environmental monitoring, but its high dimensionality, data redundancy and noise interference etc. bring great challenges to the analysis. Traditional models have limitations in dealing with these complex data, and it is difficult to meet the increasing demand for analysis. In recent years, Diffusion Model, as an emerging generative model, has shown unique advantages in hyperspectral image processing. By simulating the diffusion process of data in time, the Diffusion Model can effectively process high-dimensional data, generate high-quality samples, and perform well in denoising and data enhancement. In this paper, we review the recent research advances in diffusion modeling for hyperspectral image processing and analysis, and discuss its applications in tasks such as high-dimensional data processing, noise removal, classification, and anomaly detection. The performance of diffusion-based models on image processing is compared and the challenges are summarized. It is shown that the diffusion model can significantly improve the accuracy and efficiency of hyperspectral image analysis, providing a new direction for future research.
Adaptive Sparse ViT: Towards Learnable Adaptive Token Pruning by Fully Exploiting Self-Attention
Sep 28, 2022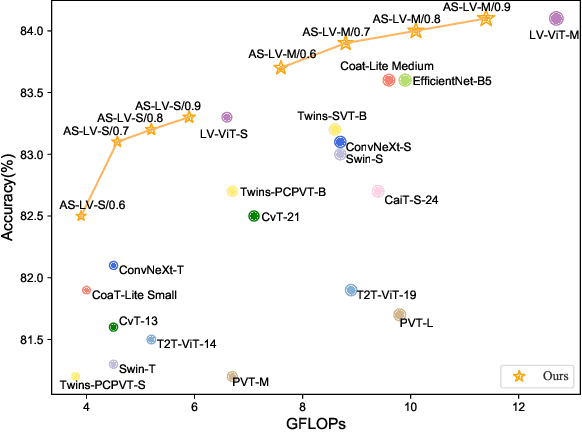
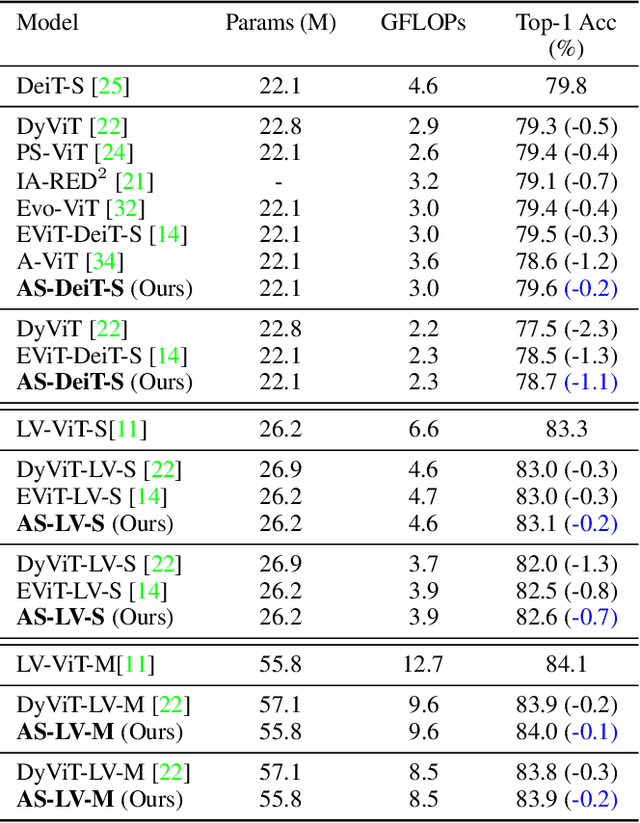

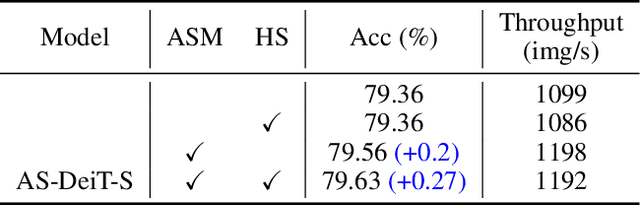
Vision transformer has emerged as a new paradigm in computer vision, showing excellent performance while accompanied by expensive computational cost. Image token pruning is one of the main approaches for ViT compression, due to the facts that the complexity is quadratic with respect to the token number, and many tokens containing only background regions do not truly contribute to the final prediction. Existing works either rely on additional modules to score the importance of individual tokens, or implement a fixed ratio pruning strategy for different input instances. In this work, we propose an adaptive sparse token pruning framework with a minimal cost. Our approach is based on learnable thresholds and leverages the Multi-Head Self-Attention to evaluate token informativeness with little additional operations. Specifically, we firstly propose an inexpensive attention head importance weighted class attention scoring mechanism. Then, learnable parameters are inserted in ViT as thresholds to distinguish informative tokens from unimportant ones. By comparing token attention scores and thresholds, we can discard useless tokens hierarchically and thus accelerate inference. The learnable thresholds are optimized in budget-aware training to balance accuracy and complexity, performing the corresponding pruning configurations for different input instances. Extensive experiments demonstrate the effectiveness of our approach. For example, our method improves the throughput of DeiT-S by 50% and brings only 0.2% drop in top-1 accuracy, which achieves a better trade-off between accuracy and latency than the previous methods.
RAPQ: Rescuing Accuracy for Power-of-Two Low-bit Post-training Quantization
Apr 26, 2022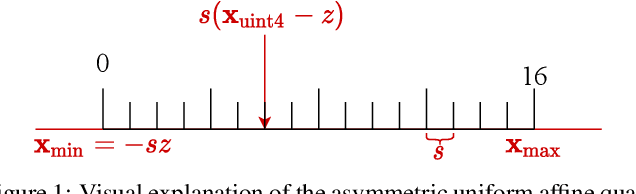
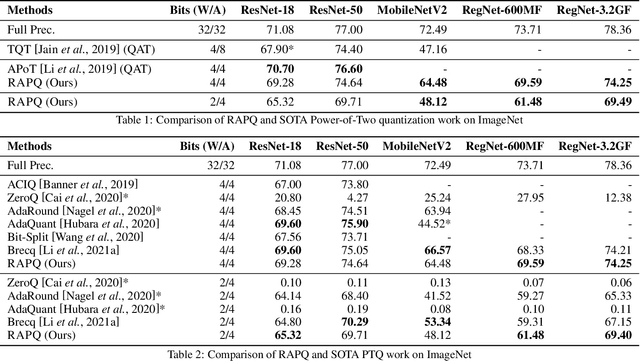
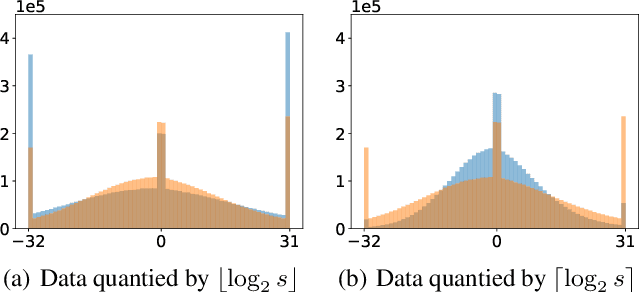
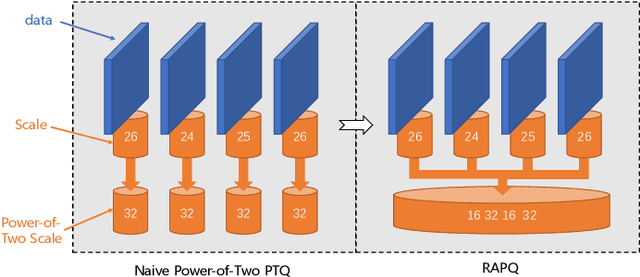
We introduce a Power-of-Two post-training quantization( PTQ) method for deep neural network that meets hardware requirements and does not call for long-time retraining. PTQ requires a small set of calibration data and is easier for deployment, but results in lower accuracy than Quantization-Aware Training( QAT). Power-of-Two quantization can convert the multiplication introduced by quantization and dequantization to bit-shift that is adopted by many efficient accelerators. However, the Power-of-Two scale has fewer candidate values, which leads to more rounding or clipping errors. We propose a novel Power-of-Two PTQ framework, dubbed RAPQ, which dynamically adjusts the Power-of-Two scales of the whole network instead of statically determining them layer by layer. It can theoretically trade off the rounding error and clipping error of the whole network. Meanwhile, the reconstruction method in RAPQ is based on the BN information of every unit. Extensive experiments on ImageNet prove the excellent performance of our proposed method. Without bells and whistles, RAPQ can reach accuracy of 65% and 48% on ResNet-18 and MobileNetV2 respectively with weight INT2 activation INT4. We are the first to propose PTQ for the more constrained but hardware-friendly Power-of-Two quantization and prove that it can achieve nearly the same accuracy as SOTA PTQ method. The code will be released.
A free lunch from ViT:Adaptive Attention Multi-scale Fusion Transformer for Fine-grained Visual Recognition
Oct 11, 2021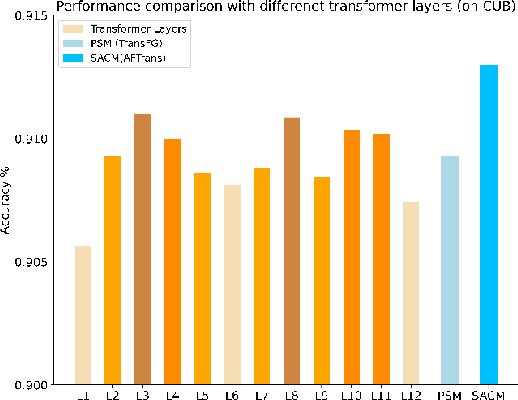
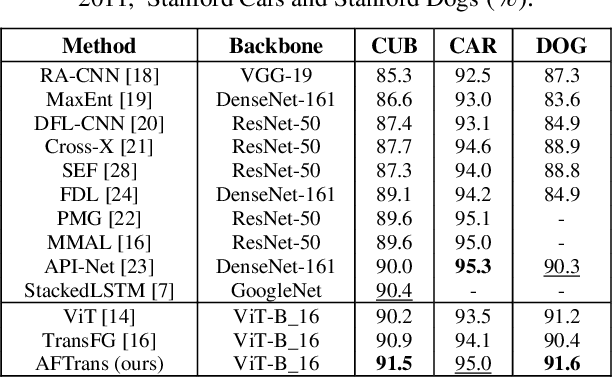
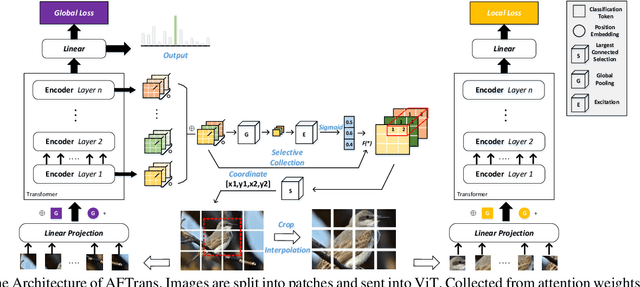

Learning subtle representation about object parts plays a vital role in fine-grained visual recognition (FGVR) field. The vision transformer (ViT) achieves promising results on computer vision due to its attention mechanism. Nonetheless, with the fixed size of patches in ViT, the class token in deep layer focuses on the global receptive field and cannot generate multi-granularity features for FGVR. To capture region attention without box annotations and compensate for ViT shortcomings in FGVR, we propose a novel method named Adaptive attention multi-scale Fusion Transformer (AFTrans). The Selective Attention Collection Module (SACM) in our approach leverages attention weights in ViT and filters them adaptively to correspond with the relative importance of input patches. The multiple scales (global and local) pipeline is supervised by our weights sharing encoder and can be easily trained end-to-end. Comprehensive experiments demonstrate that AFTrans can achieve SOTA performance on three published fine-grained benchmarks: CUB-200-2011, Stanford Dogs and iNat2017.
AdaPruner: Adaptive Channel Pruning and Effective Weights Inheritance
Sep 14, 2021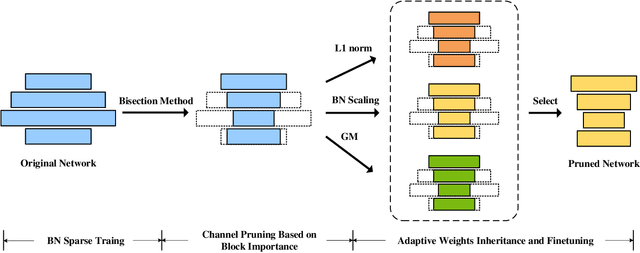
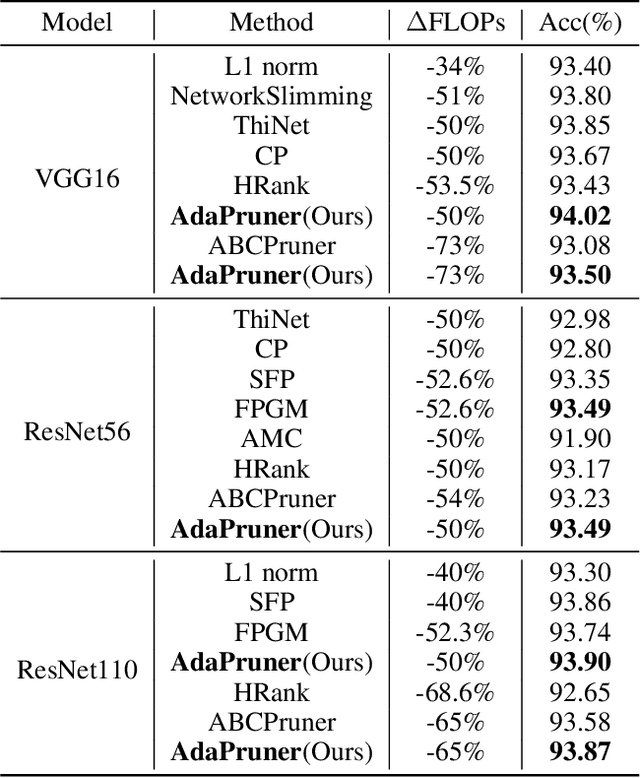
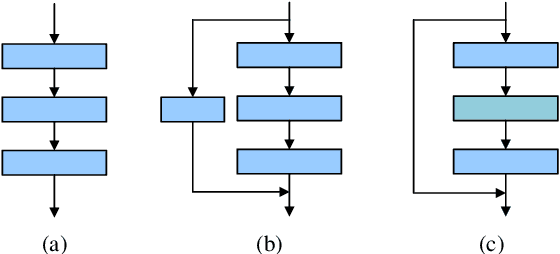
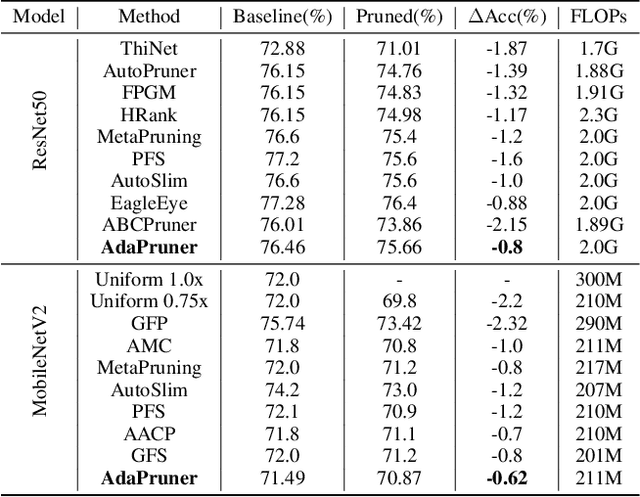
Channel pruning is one of the major compression approaches for deep neural networks. While previous pruning methods have mostly focused on identifying unimportant channels, channel pruning is considered as a special case of neural architecture search in recent years. However, existing methods are either complicated or prone to sub-optimal pruning. In this paper, we propose a pruning framework that adaptively determines the number of each layer's channels as well as the wights inheritance criteria for sub-network. Firstly, evaluate the importance of each block in the network based on the mean of the scaling parameters of the BN layers. Secondly, use the bisection method to quickly find the compact sub-network satisfying the budget. Finally, adaptively and efficiently choose the weight inheritance criterion that fits the current architecture and fine-tune the pruned network to recover performance. AdaPruner allows to obtain pruned network quickly, accurately and efficiently, taking into account both the structure and initialization weights. We prune the currently popular CNN models (VGG, ResNet, MobileNetV2) on different image classification datasets, and the experimental results demonstrate the effectiveness of our proposed method. On ImageNet, we reduce 32.8% FLOPs of MobileNetV2 with only 0.62% decrease for top-1 accuracy, which exceeds all previous state-of-the-art channel pruning methods. The code will be released.
An Once-for-All Budgeted Pruning Framework for ConvNets Considering Input Resolution
Dec 02, 2020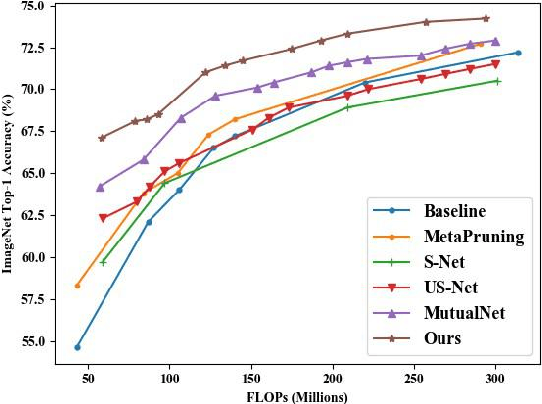

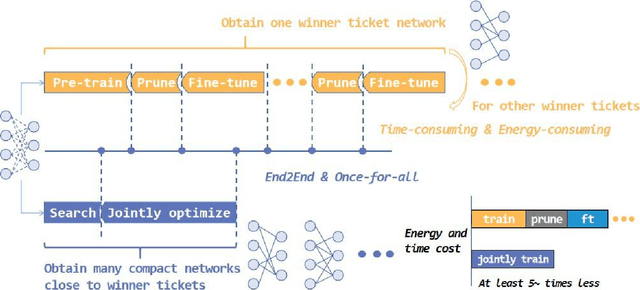
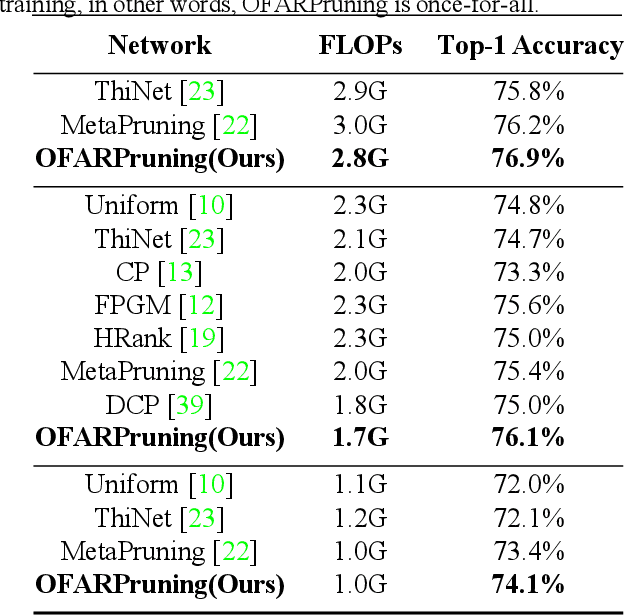
We propose an efficient once-for-all budgeted pruning framework (OFARPruning) to find many compact network structures close to winner tickets in the early training stage considering the effect of input resolution during the pruning process. In structure searching stage, we utilize cosine similarity to measure the similarity of the pruning mask to get high-quality network structures with low energy and time consumption. After structure searching stage, our proposed method randomly sample the compact structures with different pruning rates and input resolution to achieve joint optimization. Ultimately, we can obtain a cohort of compact networks adaptive to various resolution to meet dynamic FLOPs constraints on different edge devices with only once training. The experiments based on image classification and object detection show that OFARPruning has a higher accuracy than the once-for-all compression methods such as US-Net and MutualNet (1-2% better with less FLOPs), and achieve the same even higher accuracy as the conventional pruning methods (72.6% vs. 70.5% on MobileNetv2 under 170 MFLOPs) with much higher efficiency.