 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPQ: Rescuing Accuracy for Power-of-Two Low-bit Post-training Quantization
Paper and Code
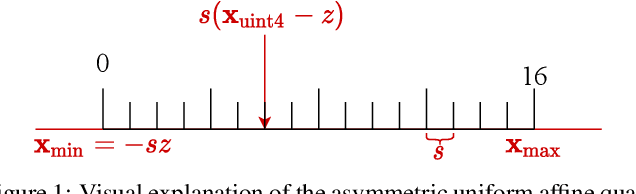
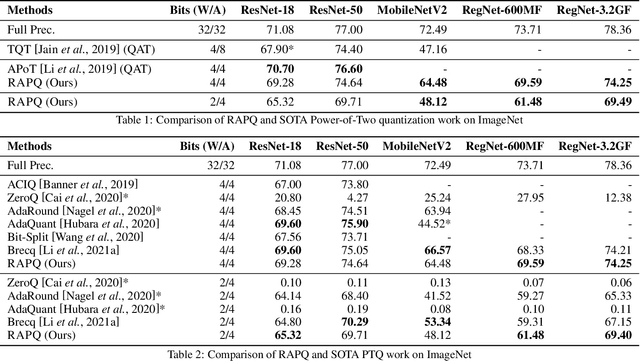
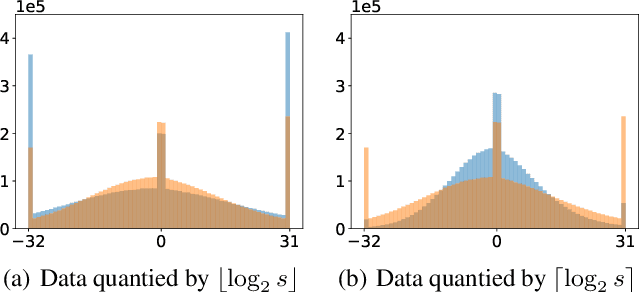
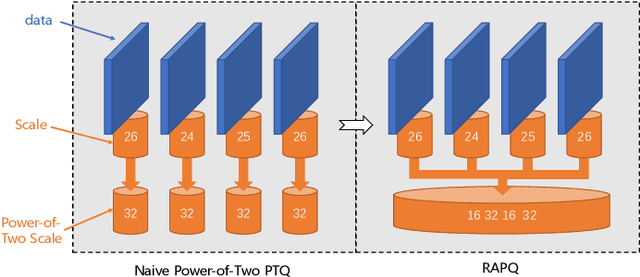
We introduce a Power-of-Two post-training quantization( PTQ) method for deep neural network that meets hardware requirements and does not call for long-time retraining. PTQ requires a small set of calibration data and is easier for deployment, but results in lower accuracy than Quantization-Aware Training( QAT). Power-of-Two quantization can convert the multiplication introduced by quantization and dequantization to bit-shift that is adopted by many efficient accelerators. However, the Power-of-Two scale has fewer candidate values, which leads to more rounding or clipping errors. We propose a novel Power-of-Two PTQ framework, dubbed RAPQ, which dynamically adjusts the Power-of-Two scales of the whole network instead of statically determining them layer by layer. It can theoretically trade off the rounding error and clipping error of the whole network. Meanwhile, the reconstruction method in RAPQ is based on the BN information of every unit. Extensive experiments on ImageNet prove the excellent performance of our proposed method. Without bells and whistles, RAPQ can reach accuracy of 65% and 48% on ResNet-18 and MobileNetV2 respectively with weight INT2 activation INT4. We are the first to propose PTQ for the more constrained but hardware-friendly Power-of-Two quantization and prove that it can achieve nearly the same accuracy as SOTA PTQ method. The code will be released.