 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally-Grounded Language Generation: A Benchmark for Real-Time Vision-Language Models
May 16, 2025Vision-language models (VLMs) have shown remarkable progress in offline tasks such as image captioning and video question answering. However, real-time interactive environments impose new demands on VLMs, requiring them to generate utterances that are not only semantically accurate but also precisely timed. We identify two core capabilities necessary for such settings -- $\textit{perceptual updating}$ and $\textit{contingency awareness}$ -- and propose a new benchmark task, $\textbf{Temporally-Grounded Language Generation (TGLG)}$, to evaluate them. TGLG requires models to generate utterances in response to streaming video such that both content and timing align with dynamic visual input. To support this benchmark, we curate evaluation datasets from sports broadcasting and egocentric human interaction domains, and introduce a new metric, $\textbf{TRACE}$, to evaluate TGLG by jointly measuring semantic similarity and temporal alignment. Finally, we present $\textbf{Vision-Language Model with Time-Synchronized Interleaving (VLM-TSI)}$, a model that interleaves visual and linguistic tokens in a time-synchronized manner, enabling real-time language generation without relying on turn-based assumptions. Experimental results show that VLM-TSI significantly outperforms a strong baseline, yet overall performance remains modest -- highlighting the difficulty of TGLG and motivating further research in real-time VLMs. Code and data available $\href{https://github.com/yukw777/tglg}{here}$.
Espresso: High Compression For Rich Extraction From Videos for Your Vision-Language Model
Dec 06, 2024Most of the current vision-language models (VLMs) for videos struggle to understand videos longer than a few seconds. This is primarily due to the fact that they do not scale to utilizing a large number of frames. In order to address this limitation, we propose Espresso, a novel method that extracts and compresses spatial and temporal information separately. Through extensive evaluations, we show that spatial and temporal compression in Espresso each have a positive impact on the long-form video understanding capabilities; when combined, their positive impact increases. Furthermore, we show that Espresso's performance scales well with more training data, and that Espresso is far more effective than the existing projectors for VLMs in long-form video understanding. Moreover, we devise a more difficult evaluation setting for EgoSchema called "needle-in-a-haystack" that multiplies the lengths of the input videos. Espresso achieves SOTA performance on this task, outperforming the SOTA VLMs that have been trained on much more training data.
Efficient In-Context Learning in Vision-Language Models for Egocentric Videos
Nov 29, 2023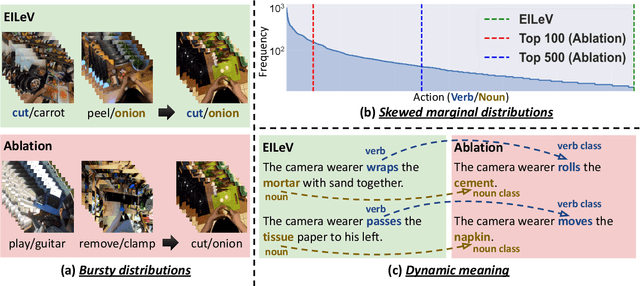
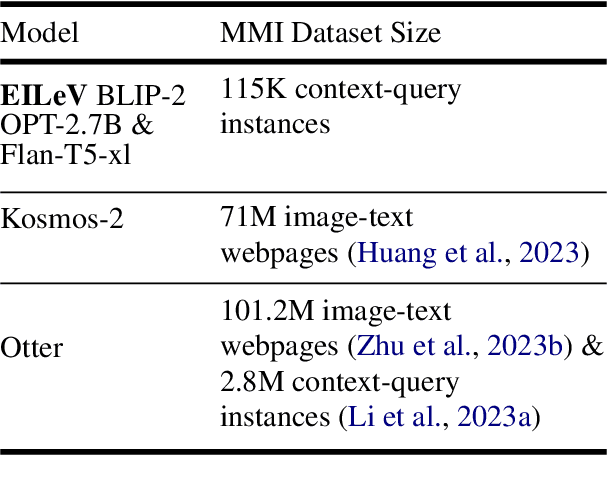
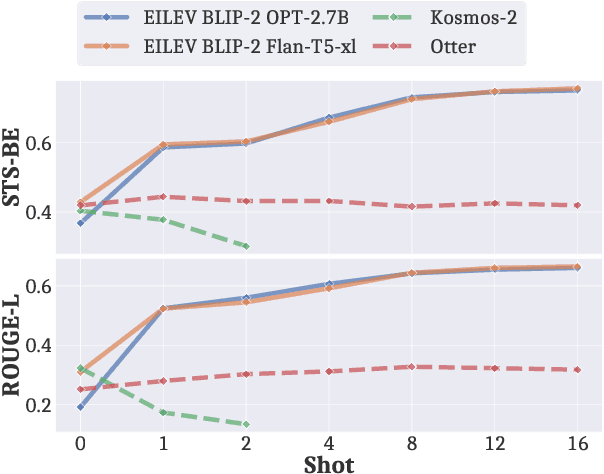
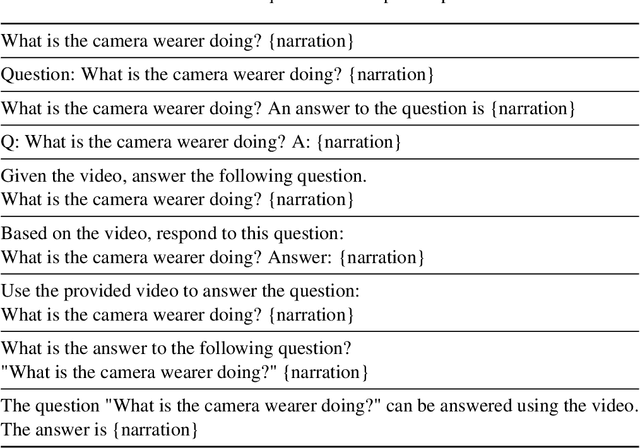
Recent advancements in text-only large language models (LLMs) have highlighted the benefit of in-context learning for adapting to new tasks with a few demonstrations. However, extending in-context learning to large vision-language models (VLMs) using a huge amount of naturalistic vision-language data has shown limited success, particularly for egocentric videos, due to high data collection costs. We propose a novel training method $\mathbb{E}$fficient $\mathbb{I}$n-context $\mathbb{L}$earning on $\mathbb{E}$gocentric $\mathbb{V}$ideos ($\mathbb{EILEV}$), which elicits in-context learning in VLMs for egocentric videos without requiring massive, naturalistic egocentric video datasets. $\mathbb{EILEV}$ involves architectural and training data adaptations to allow the model to process contexts interleaved with video clips and narrations, sampling of in-context examples with clusters of similar verbs and nouns, use of data with skewed marginal distributions with a long tail of infrequent verbs and nouns, as well as homonyms and synonyms. Our evaluations show that $\mathbb{EILEV}$-trained models outperform larger VLMs trained on a huge amount of naturalistic data in in-context learning. Furthermore, they can generalize to not only out-of-distribution, but also novel, rare egocentric videos and texts via in-context learning, demonstrating potential for applications requiring cost-effective training, and rapid post-deployment adaptability. Our code and demo are available at \url{https://github.com/yukw777/EILEV}.
Constructing Temporal Dynamic Knowledge Graphs from Interactive Text-based Games
Nov 03, 2023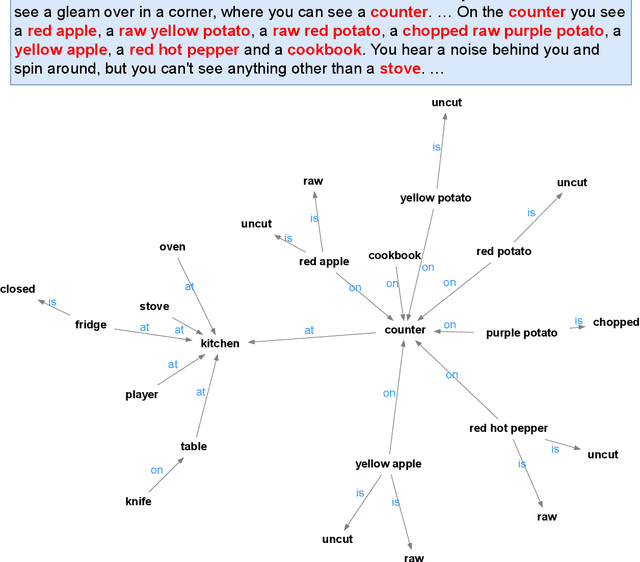

In natural language processing, interactive text-based games serve as a test bed for interactive AI systems. Prior work has proposed to play text-based games by acting based on discrete knowledge graphs constructed by the Discrete Graph Updater (DGU) to represent the game state from the natural language description. While DGU has shown promising results with high interpretability, it suffers from lower knowledge graph accuracy due to its lack of temporality and limited generalizability to complex environments with objects with the same label. In order to address DGU's weaknesses while preserving its high interpretability, we propose the Temporal Discrete Graph Updater (TDGU), a novel neural network model that represents dynamic knowledge graphs as a sequence of timestamped graph events and models them using a temporal point based graph neural network. Through experiments on the dataset collected from a text-based game TextWorld, we show that TDGU outperforms the baseline DGU. We further show the importance of temporal information for TDGU's performance through an ablation study and demonstrate that TDGU has the ability to generalize to more complex environments with objects with the same label. All the relevant code can be found at \url{https://github.com/yukw777/temporal-discrete-graph-updater}.
Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?
Nov 01, 2023Despite tremendous advances in AI, it remains a significant challenge to develop interactive task guidance systems that can offer situated, personalized guidance and assist humans in various tasks. These systems need to have a sophisticated understanding of the user as well as the environment, and make timely accurate decisions on when and what to say. To address this issue, we created a new multimodal benchmark dataset, Watch, Talk and Guide (WTaG) based on natural interaction between a human user and a human instructor. We further proposed two tasks: User and Environment Understanding, and Instructor Decision Making. We leveraged several foundation models to study to what extent these models can be quickly adapted to perceptually enabled task guidance. Our quantitative, qualitative, and human evaluation results show that these models can demonstrate fair performances in some cases with no task-specific training, but a fast and reliable adaptation remains a significant challenge. Our benchmark and baselines will provide a stepping stone for future work on situated task guidance.
NLP Reproducibility For All: Understanding Experiences of Beginners
Jun 03, 2023



As natural language processing (NLP) has recently seen an unprecedented level of excitement, and more people are eager to enter the field, it is unclear whether current research reproducibility efforts are sufficient for this group of beginners to apply the latest developments. To understand their needs, we conducted a study with 93 students in an introductory NLP course, where students reproduced the results of recent NLP papers. Surprisingly, we find that their programming skill and comprehension of research papers have a limited impact on their effort spent completing the exercise. Instead, we find accessibility efforts by research authors to be the key to success, including complete documentation, better coding practice, and easier access to data files. Going forward, we recommend that NLP researchers pay close attention to these simple aspects of open-sourcing their work, and use insights from beginners' feedback to provide actionable ideas on how to better support them.
DANLI: Deliberative Agent for Following Natural Language Instructions
Oct 22, 2022



Recent years have seen an increasing amount of work on embodied AI agents that can perform tasks by following human language instructions. However, most of these agents are reactive, meaning that they simply learn and imitate behaviors encountered in the training data. These reactive agents are insufficient for long-horizon complex tasks. To address this limitation, we propose a neuro-symbolic deliberative agent that, while following language instructions, proactively applies reasoning and planning based on its neural and symbolic representations acquired from past experience (e.g., natural language and egocentric vision). We show that our deliberative agent achieves greater than 70% improvement over reactive baselines on the challenging TEACh benchmark. Moreover, the underlying reasoning and planning processes, together with our modular framework, offer impressive transparency and explainability to the behaviors of the agent. This enables an in-depth understanding of the agent's capabilities, which shed light on challenges and opportunities for future embodied agents for instruction following. The code is available at https://github.com/sled-group/DANLI.
Reproducibility Beyond the Research Community: Experience from NLP Beginners
May 05, 2022



As NLP research attracts public attention and excitement, it becomes increasingly important for it to be accessible to a broad audience. As the research community works to democratize NLP, it remains unclear whether beginners to the field can easily apply the latest developments. To understand their needs, we conducted a study with 93 students in an introductory NLP course, where students reproduced results of recent NLP papers. Surprisingly, our results suggest that their technical skill (i.e., programming experience) has limited impact on their effort spent completing the exercise. Instead, we find accessibility efforts by research authors to be key to a successful experience, including thorough documentation and easy access to required models and datasets.
One Model to Recognize Them All: Marginal Distillation from NER Models with Different Tag Sets
Apr 17, 2020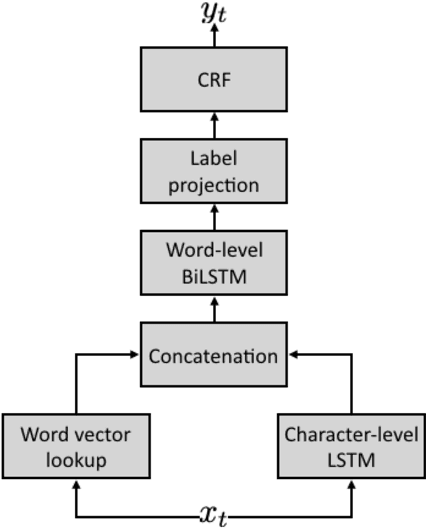
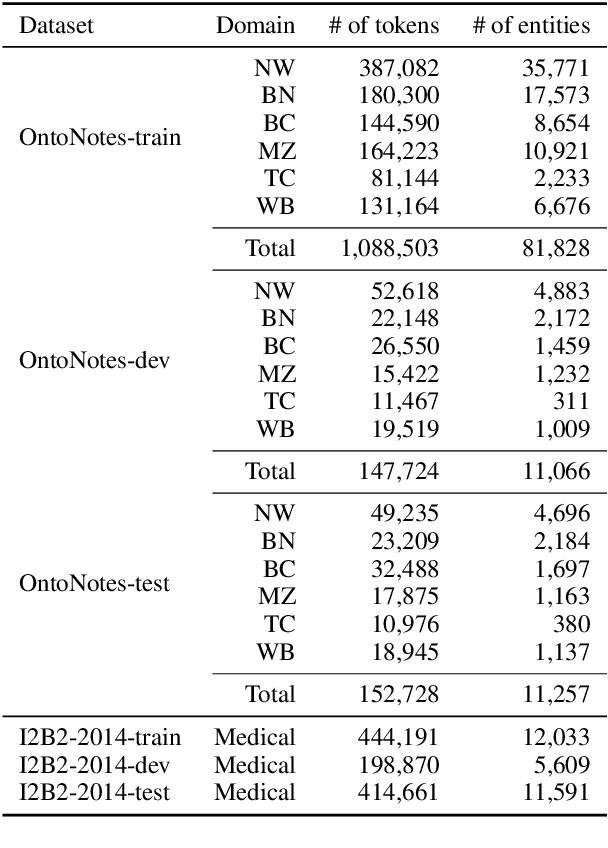


Named entity recognition (NER) is a fundamental component in the modern language understanding pipeline. Public NER resources such as annotated data and model services are available in many domains. However, given a particular downstream application, there is often no single NER resource that supports all the desired entity types, so users must leverage multiple resources with different tag sets. This paper presents a marginal distillation (MARDI) approach for training a unified NER model from resources with disjoint or heterogeneous tag sets. In contrast to recent works, MARDI merely requires access to pre-trained models rather than the original training datasets. This flexibility makes it easier to work with sensitive domains like healthcare and finance. Furthermore, our approach is general enough to integrate with different NER architectures, including local models (e.g., BiLSTM) and global models (e.g., CRF). Experiments on two benchmark datasets show that MARDI performs on par with a strong marginal CRF baseline, while being more flexible in the form of required NER resources. MARDI also sets a new state of the art on the progressive NER task. MARDI significantly outperforms the start-of-the-art model on the task of progressive NER.