 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-Transformer: Counterfactual Outcome Prediction under Dynamic and Time-varying Treatment Regimes
Jun 11, 2024In the context of medical decision making, counterfactual prediction enables clinicians to predict treatment outcomes of interest under alternative courses of therapeutic actions given observed patient history. Prior machine learning approaches for counterfactual predictions under time-varying treatments focus on static time-varying treatment regimes where treatments do not depend on previous covariate history. In this work, we present G-Transformer, a Transformer-based framework supporting g-computation for counterfactual prediction under dynamic and time-varying treatment strategies. G-Transfomer captures complex, long-range dependencies in time-varying covariates using a Transformer architecture. G-Transformer estimates the conditional distribution of relevant covariates given covariate and treatment history at each time point using an encoder architecture, then produces Monte Carlo estimates of counterfactual outcomes by simulating forward patient trajectories under treatment strategies of interest. We evaluate G-Transformer extensively using two simulated longitudinal datasets from mechanistic models, and a real-world sepsis ICU dataset from MIMIC-IV. G-Transformer outperforms both classical and state-of-the-art counterfactual prediction models in these settings. To the best of our knowledge, this is the first Transformer-based architecture for counterfactual outcome prediction under dynamic and time-varying treatment strategies. Code will be released upon publication of the paper.
User Modeling Challenges in Interactive AI Assistant Systems
Mar 29, 2024Interactive Artificial Intelligent(AI) assistant systems are designed to offer timely guidance to help human users to complete a variety tasks. One of the remaining challenges is to understand user's mental states during the task for more personalized guidance. In this work, we analyze users' mental states during task executions and investigate the capabilities and challenges for large language models to interpret user profiles for more personalized user guidance.
A Knowledge Distillation Approach for Sepsis Outcome Prediction from Multivariate Clinical Time Series
Nov 16, 2023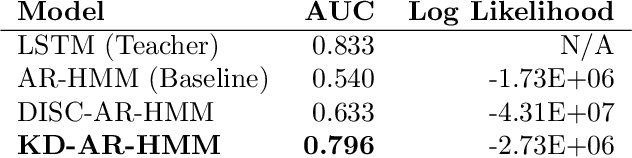
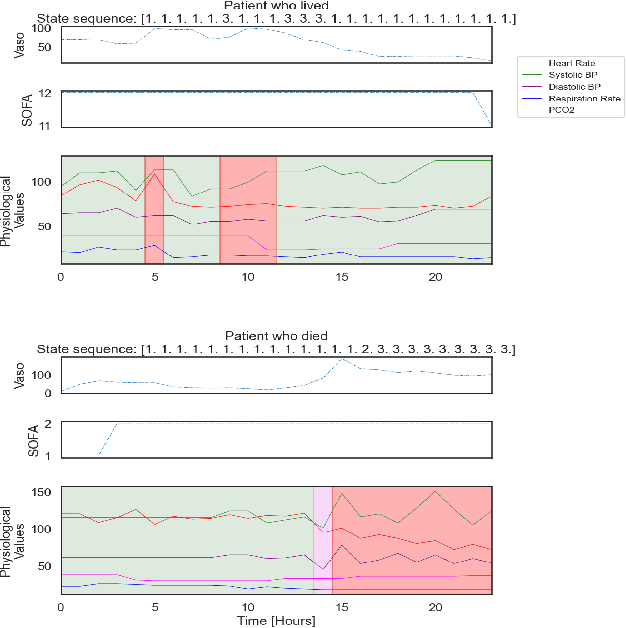
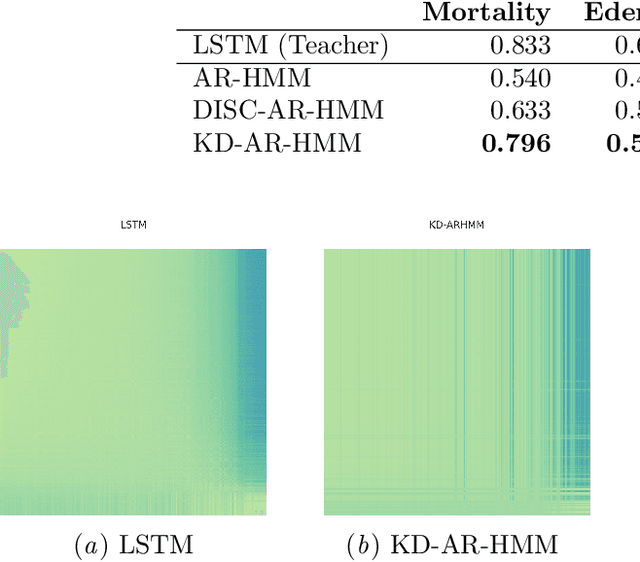

Sepsis is a life-threatening condition triggered by an extreme infection response. Our objective is to forecast sepsis patient outcomes using their medical history and treatments, while learning interpretable state representations to assess patients' risks in developing various adverse outcomes. While neural networks excel in outcome prediction, their limited interpretability remains a key issue. In this work, we use knowledge distillation via constrained variational inference to distill the knowledge of a powerful "teacher" neural network model with high predictive power to train a "student" latent variable model to learn interpretable hidden state representations to achieve high predictive performance for sepsis outcome prediction. Using real-world data from the MIMIC-IV database, we trained an LSTM as the "teacher" model to predict mortality for sepsis patients, given information about their recent history of vital signs, lab values and treatments. For our student model, we use an autoregressive hidden Markov model (AR-HMM) to learn interpretable hidden states from patients' clinical time series, and use the posterior distribution of the learned state representations to predict various downstream outcomes, including hospital mortality, pulmonary edema, need for diuretics, dialysis, and mechanical ventilation. Our results show that our approach successfully incorporates the constraint to achieve high predictive power similar to the teacher model, while maintaining the generative performance.
Can Foundation Models Watch, Talk and Guide You Step by Step to Make a Cake?
Nov 01, 2023Despite tremendous advances in AI, it remains a significant challenge to develop interactive task guidance systems that can offer situated, personalized guidance and assist humans in various tasks. These systems need to have a sophisticated understanding of the user as well as the environment, and make timely accurate decisions on when and what to say. To address this issue, we created a new multimodal benchmark dataset, Watch, Talk and Guide (WTaG) based on natural interaction between a human user and a human instructor. We further proposed two tasks: User and Environment Understanding, and Instructor Decision Making. We leveraged several foundation models to study to what extent these models can be quickly adapted to perceptually enabled task guidance. Our quantitative, qualitative, and human evaluation results show that these models can demonstrate fair performances in some cases with no task-specific training, but a fast and reliable adaptation remains a significant challenge. Our benchmark and baselines will provide a stepping stone for future work on situated task guidance.